
如何设计一个合适的决策引擎
 决策引擎,rete算法
决策引擎,rete算法
整出了规则引擎,单模块的规则可以搞定,细节看 规则引擎是如何诞生的。还以信用评分卡以及额度模型来说,不同行业的阈值差异是很大的,因此通常还需要引入分支才是一个完整的决策。
先看一个决策流长什么样?

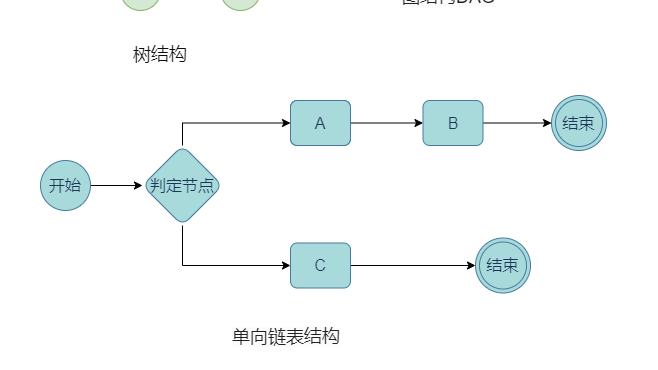
这是一个比较简单的决策流,它由两个规则集顺序编排,并有起始和结束,是符合BPMN规范的。
BPMN是什么?Business Process Diagram(BPM)是指一个业务流程图,“N”是Notation符号,BPMN业务流程建模符号,是由OMG组织维护的一套业务流程建模标准。真实业务会更加复杂,简单的链式无法满足情况,那么几种常见的结构,比如树结构、图结构、链表结构各有特性。
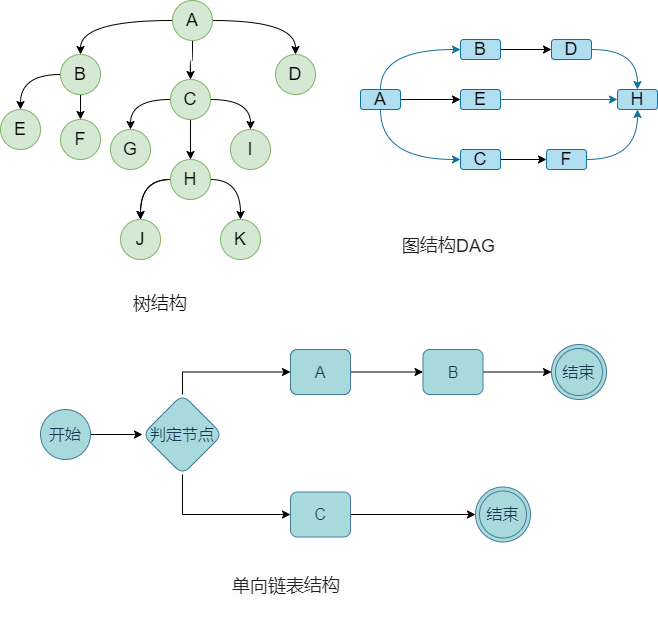
决策流是排它网关,有且只有一个分支满足执行条件,所以单向链表结构更合适。这样也满足我们刚开始的定义,决策流就是一条单向的执行直到结束。那么判定节点如何设计呢,我们先从提出两种经典选择:
- if-else是比较耳熟能详的分支条件,Drools也是这么实现
- 头节点判定,循环执行每个分支的条件表达式,并选择结果为true的第一个分支,决策结果即为决策流下一步要走的分支名。
乍一看不同,再琢磨一下,两个都是一个作风,那就是莽,区别就在于表现形式不同。光是判定就会有重复执行情况,好处也明显,判定很暴力。结局也类似,出现性能问题,rete算法善后。
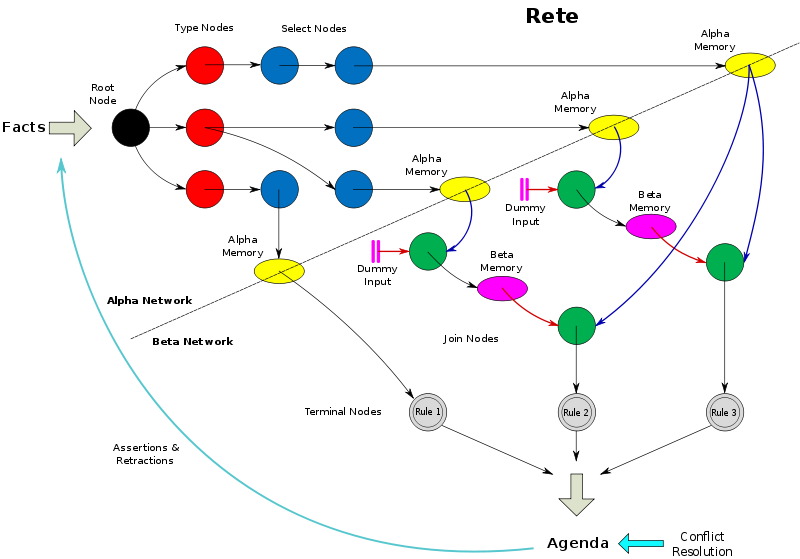
简单总结下rete效率高的原因,一是梳理成网络,干掉了重复。二是将结果保存,空间换时间。这是两个很值得参考的点,接下来我们也会用上。
多分支选择,关注python的同学可能已听过 match-case,这个设计思路是个很好的参考。可以解决我们分支判定时候得重复计算情况,同时只要用点小技巧(分流、AB等各种都可以满足),而不需要开发众多分支网关,效果很好。关于match使用的特征,可以是直接传参过来,也可以是上一轮的结果作为这一轮的特征。
规则集中含有重复的条件,以及不同批次的调用也可能有相同的计算,这个可以在执行引擎做一个cache(限定条目,防止内存不可控),空间换时间的思想也直接用上。分支之后的规则也很容易出现相同,想要rete网格那样的清爽的图,决策流汇合就安排上,这样简单的流就变成这样。
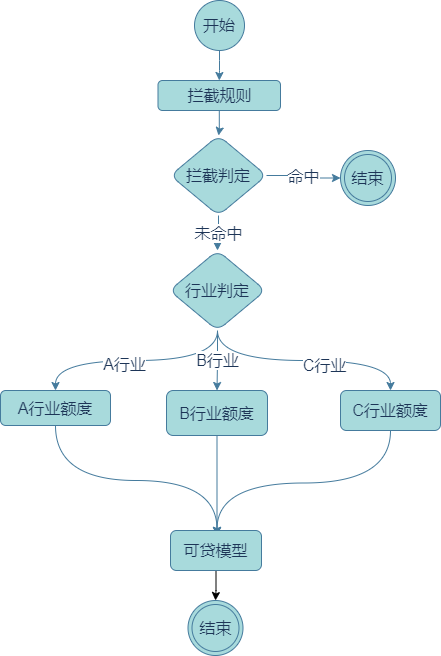
决策流对应数据模型也清爽了。
class WorkNode:
__slots__ = ['name', 'module', 'next_node']
def __init__(self, name, module, next_node):
self.name = name
self.module = module
self.next_node = next_node
class MatchNode:
__slots__ = ['name', 'pattern', 'feature', 'node_cases']
def __init__(self, name, pattern, feature, node_cases: List[Tuple[Any, WorkNode]]):
self.name = name
self.pattern = pattern
self.feature = feature
self.node_cases = node_cases
任务节点WorkNode和分支节点MatchNode就组成所有的分支模块,那么执行引擎就很容易实现了,参考如下:
def _run(self, val, context, node):
if not node:
return True, val
elif isinstance(node, msg.WorkNode):
try:
val = self.work_node_expr(context, node)
context.update({node.module.name: val})
node = node.next_node
return self._run(val, context, node)
except Exception as e:
return False, e
else:
try:
node = self.match_node_expr(context, node)
return self._run(val, context, node)
except Exception as e:
return False, e

 浙公网安备 33010602011771号
浙公网安备 33010602011771号