
规则引擎是如何诞生的
 python实现规则引擎
python实现规则引擎
你是否陷入了整天对着一堆规则判定改来改去,虽然每个信用评分卡和额度模型看起来都很像,但是总是有不同点,一堆密密麻麻的逻辑判定,别说开发了,测试看了挠头。作为一个开发,你想把它规范化,通用化,这就是规则引擎的动机了。
先从拦截规则说起,虽然条目很多,但它简单好写也好测,举个例子如下:
A类拦截规则判定(命中任意一条都拒绝):
1、年销售额低于30万不要
2、近一年存在偷税漏税情况不要
这种简单明了的规则,相信大家分分钟就能写出来,比如这样:
def lanjie_a(year_sales, tax_evasion_count):
if year_sales < 300000:
return True
if tax_evasion_count > 0:
return True
return False
完美写出,大家信心满满,豪气道,这种拦截我可以写十个。求仁得仁,组合拦截来了。
B类拦截规则判定(命中两条及以上都拒绝)
1、法院轻度纠纷事件大于2起
2、年收入连续三年下降
3、存在工资拖欠情况
小小变种还是难不倒聪明的开发,一个计数分分钟解决,参考如下:
def lanjie_b(a, b, c):
counter = 0
if a > 2:
counter += 1
if b:
counter += 1
if c:
counter += 1
return couner >= 2
正当开发想给自己的机智打call的时候,新规则又来了,那就是A和B一起判定,后面C、D同上。求锤得锤,开发仰天长啸:怪不得网上都说代码就是粘贴复制,原来就是这个意思。熟练的按下Ctrl-C和Ctrl-V,一堆长长的代码就这么诞生了。奋战N个回合,终于在手酸腰痛眼花的情况下搞定,七分无奈一分嘲讽,还有两分隐藏心底的自豪。等下次换个行业再来类似的拦截,一堆CV猛如虎,两分自豪慢慢消失,变成茫然与不甘。
深吸一口气,放松下自己,放弃代码,我们来看看一条规则到底是什么东西?当某个变量满足一定阈值就会给出一个判定,然后这一个判定作为变量又进入了下一轮条件判定,直到规则结束。是不是一下子有了点思路,再抽象下可以变成这样:
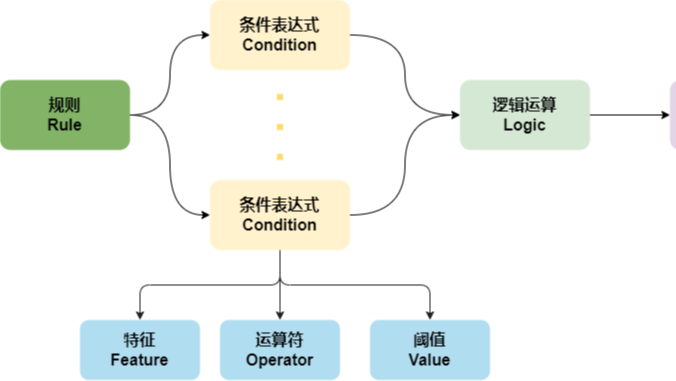
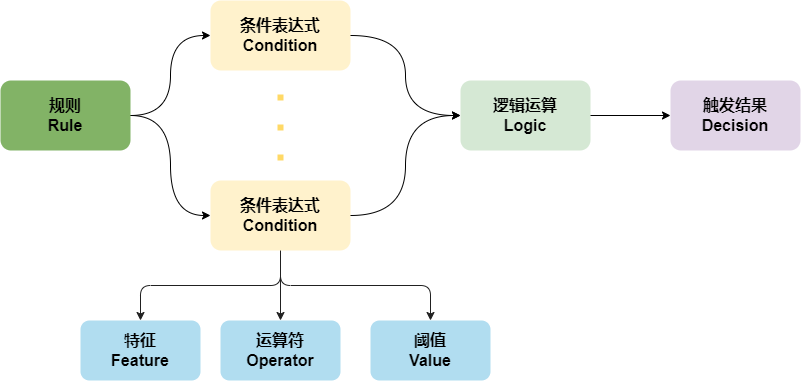
特征 (年销售额) 运算符(小于) 阈值(300000) ---> 触发结果(拒绝)
这里产生几个概念:特征feature、运算符operator、阈值value,这三要素构成条件表达式condition,加上触发结果decision,组成了规则rule的基础元素,他们之间关系如下:
先对条件表达式进行建模,假设只有拒绝与通过两种决策,那么模型可以这样
class Condition:
__slots__ = [feature", "operator", "value"]
def __init__(self, feature, operator, value):
self.feature = feature
self.operator = operator
self.value = value
我们可以很轻松的将条件转化为上述的模型,那么如何得到结果呢?我们以常见的数字类型来举例,Python比较简单,参考如下:
class NumberCondition(Object):
@property
def ops(self):
return [">", "<", ">=", "<=", "==", "!=", "in"]
def __call__(self, context: dict, c: Condition):
# TODO check
val = context[c.feature]
if not isinstance(val, (int, float)):
raise TypeError(f"Feature {c.feature} not (int, float)")
expr = f'{val} {c.operator} {c.value}'
return eval(expr, {}, context)
def __repr__(self):
return 'number_condition'
条件表达式解决了,但是我们一般都是一堆条件在一起组合,那又该如何建模呢?
class Rule:
"""规则中所有条件都会执行"""
__slots__ = ['conditions', 'logic', 'decision', 'depends']
def __init__(self, conditions, logic, decision, depends):
self.conditions = conditions
self.logic = logic
self.decision = decision
self.depends = depends
单个条件判定只有是否两种结果,因此不需要logic,而比如拦截规则,可能属于A类规则,只要有一个就行;也可能是B类,最少2条才行,因此不同规则的逻辑是不同的。不同规则拦截可能输出提示也不同,因此我们再额外引入个 decision,用来承载描述,而 depends 则是我们包含的条件需要的特征有哪些,参考引擎如下:
class RuleExpression(object):
def __init__(self):
# 不同类型表达式实现不一样,我们整个工厂模型打个包,统一入口
self.condition_expr = ConditionExpression()
# 逻辑引擎需要根据需求来完善,比如上述案例,需要实现任意一条,和最少两条的逻辑判定
self.logic_expr = LogicExpression()
def __call__(self, context: dict, r: Rule):
for feature in r.depends:
if feature not in context:
raise KeyError(f'Rule {r.name} depends {feature} not in context {context}')
results = list(self.condition_expr(context, c) for c in r.conditions)
logic_results = self.logic_expr(results, r.logic)
retrun r.decision if logic_results and r.decision is not None else logic_results
规则之间很容易组合操作,那么我们参考规则与条件的关系,把规则集也建模出来。这里需要注意,嵌套两层就差不多了,无限嵌套看似灵活,实在大坑,可以通过完善条件表达式,以及合理的设计来实现降维,保证整体效果。
经过一阵不分日夜的努力,引擎底座研发出来了,那么我们如何提供服务呢?是嵌入到代码里,还是提供服务,如果提供服务,那么规则的更新又该如何实现呢?一阵头脑风暴,DSL该登场了。
DSL是什么?全称是Domain Specific Language,领域特定语言。举个例子SQL就是数据库领域的交互语言,它定义了一套标准语法,各大数据库厂商(如mysql、oracle)对其进行解析实现,任何人都可通过编写SQL实现与数据库的交互。类似还有正则表达式、HTML&CSS等均形成了自己的语法标准。
回想我们的引擎真实的操作对象是我们的模型,那么只要能将输入转化成模型,任何格式我们都可以用来定义我们的规则引擎。因此我们可以针对不同的场景设计不同的DSL,比如API更新,我们可以采用JSON,参考如下:
{
'name': 'my_card',
'rules': [
{
'name': 'A类拦截',
'conditions': [
['number_condition', 'year_sales', '<', 300000],
['number_condition', 'tax_evasion_count', '>', 0],
],
'logic': 'any',
'decision': '该公司命中A类拦截,予以拒绝'
}
]
}
这样整个规则变成了可配置,在设计个产品出来,一个规则引擎产品就这么诞生了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号