
如何快速省钱落地一个商业大模型
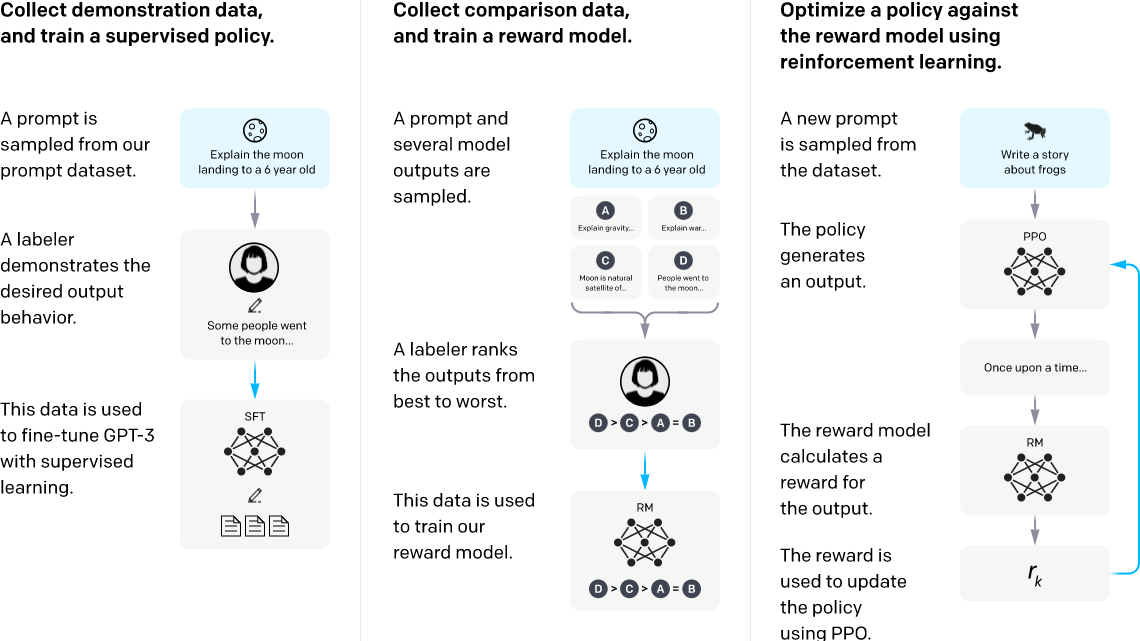 高快好省落地商业大模型
高快好省落地商业大模型
如果把基于规则的判定比作是对错的绝对分析,那么算法就是对一个没有对与错的可能性描述,比如A和B有没有关系。在通过实时计算,数仓分层等手段,数据的直观价值基本都会慢慢被挖掘出来,但是也很容易被对手模仿,跨领域分析就显得越来越重要,但不可能跨个领域就招个专家回来。从按调用付费的ChatGPT,到各有千秋的私有大模型,东风来了。
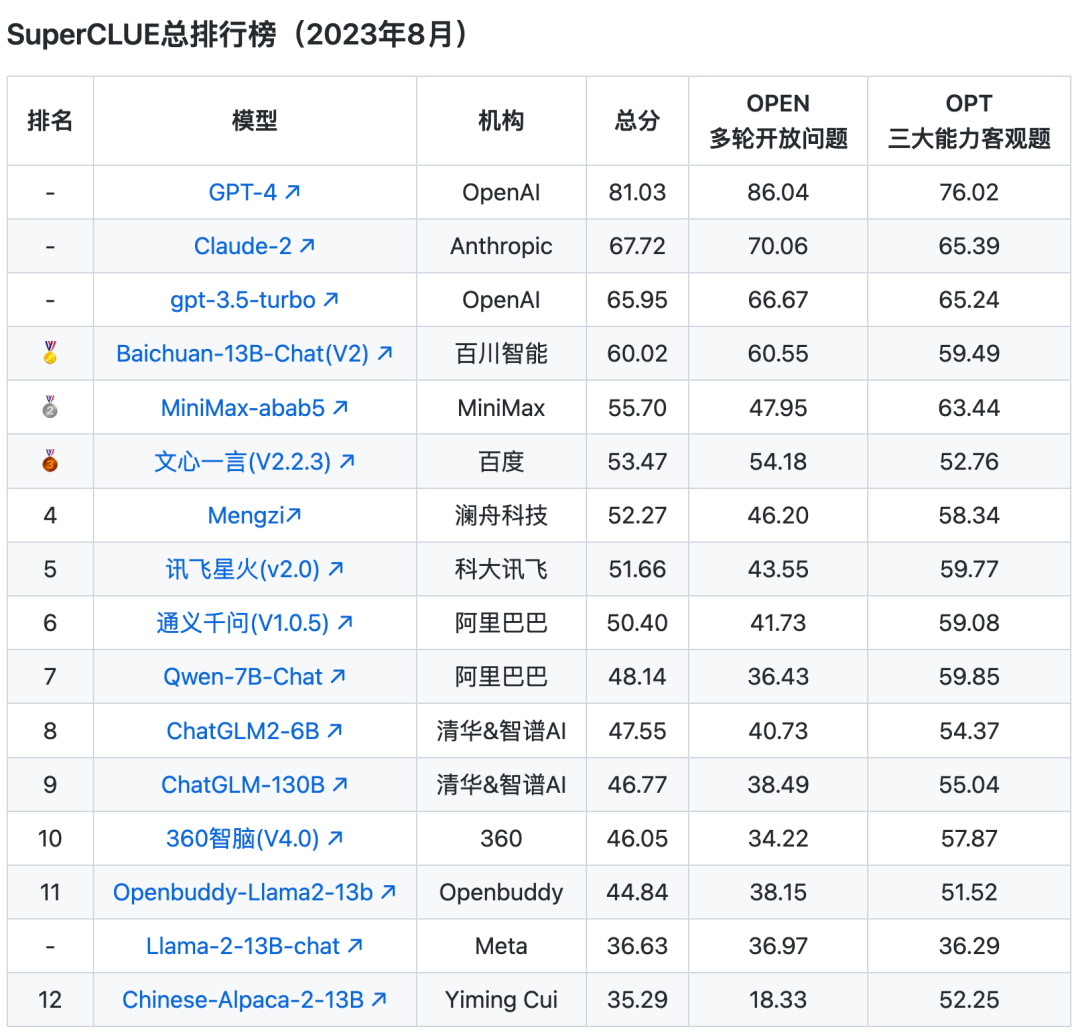
有人把大模型分为通用大模型、行业大模型、企业大模型,我觉得很贴切,行业大模型从数据训练到工程化落地,以及商业价值都有很高的性价比。其中企业独有的高质量行业数据,也是一个很大的门槛。
选择合适的切入点
首先我们选择一个切入点,其中数据质量、规模以及时间跨度也相对合适的最佳,比如TB级别数据,时间跨度超过3年(这里的3年需要参考相关领域的经验)。初步验证一个好的实践是,来个大内存GPU,当内存可以完整容纳整个模型的时候,可以实现数据并行,来提升速度。反之模型太大,要走模型并行,而模型并行同一时间只有一个GPU在运行,这可不是一个好开端。
开启训练

算法跑出来的结果往往和预期有很大差异,这是一个很容易夭折的点。这里有很多原因,比如大模型没选好,数据本身具有局限性,数据很不标准化等。分析可行性、找到闪光点、阻塞点,在一步步调整方向就不细说了。这里有个心得,企业有圈子,数据也有圈子,分析数据本身的特点,是找到切入点的捷径。
最小可用工程
工程化是个复杂的过程,TB级别数据,我们先说配置(又是一个夭折点):
- 三台虚拟机(SSD硬盘)组建 ES集群
- 一个GPU机器 (云上按月租)
如何快速将历史数据转化为模型可用的数据集,自建的ES集群坑不少,这里有些心得,可以供大家避坑:
- 避免出现更新,如果需要指标累计,可以分层加工
- 合理分索引,三台单个索引100G以内性能还可以
- ES参数很多,遇到性能问题,可以调调参数,这里有一些好用的参数
1、索引刷新间隔
index.refresh_interval = 30s
2、日志改为异步写入
{
"index.translog.durability": "async",
"index.translog.flush_threshold_size": "1024mb",
"index.translog.sync_interval": "30s"
}
3、初次同步,副本先改为0,后续在改为1
- 避免外网使用,外网认证情况下容易断链接,去掉认证可修复,慎重
- 使用composite进行分页的话,可以配合固定字段过滤,切分任务,性能更加(查崩429还是挺常见的,一旦出现可参考)
- 写崩429,有钱加机器,没钱悠着点
数据合规性
高质量的数据往往都是受限使用的,因此数据脱密又是一个红线以及夭折点,比如企业税号,授权也只能用15天。算法属于离线,如何完全脱密又能分析出其中关系,设计难度很大。通用的设计恐怕能挠秃,基于应用场景的话还是有一些方法可用,比如冗余存储,通过空间保留一定的关联度信息。
合适的存储
关系存储用图数据库会好一点,比如Neo4j,社区版单机性能就挺好,最好用新版,语法支持会好很多。查询语法很多,这里就略过;写入也是一个大点,支持唯一索引,以及批量操作,是个很关键点,参考语法如下:
# 节点唯一索引
CREATE CONSTRAINT person_name
FOR (p:Person) REQUIRE p.name IS UNIQUE
# 关系唯一索引
CREATE CONSTRAINT sequels IF NOT EXISTS
FOR ()-[sequel:SEQUEL_OF]-() REQUIRE (sequel.order) IS UNIQUE
# 批处理
UNWIND ['a1', 'a2', 'a3' ] as row
merge(p:Person {name: row})
小步快跑,持续迭代,别过于追求完美,市场不等人,满足一定条件就要立马投入市场。在数据不多的情况下,也有一些方法可以保证口碑,就是先选几个行业做着力点,一个个提升准确度,慢慢放大行业覆盖率。收到市场的反馈,再持续迭代。
来个数据标注师
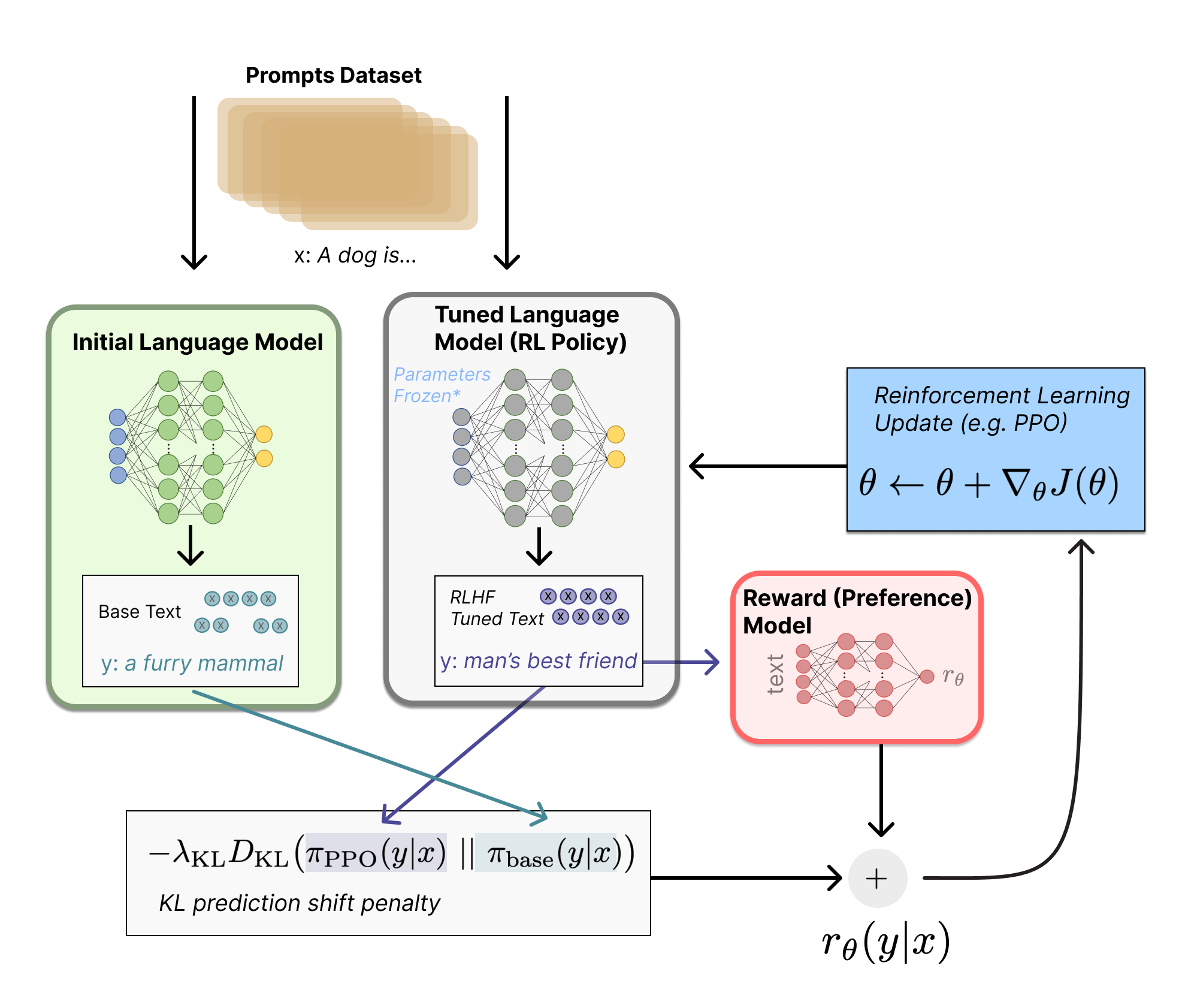
机器标注依然存在局限性,用强化学习加上人工反馈来调优,也就是RLHF,当前还是很必要的。我们一直在逐步缩小范围,这样更容易集中力量,拿出可让市场亮光的点,申请两个数据标注师就水到渠成。
形成闭环
单个质量把控完成,数据的覆盖情况以及在各个行业的展示效果一般也会有很大差异,扬长避短,逐步增加丰富度。通过市场宣传,吸收客户反馈,最终形成大闭环。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号