
高性能定时任务设计
工作中一次性的延迟任务以及周期性的定时任务都是常遇到的,简单场景一个sleep就能胜任。如果一下子很复杂,总觉得四处都可以优化而又无法下手。抽象了下定时任务的数据流,方便有的放矢,个人建议,仅供参考:

时间是什么?
时间是指一种尺度,是物质运动的存在形式 ··· ··· ··· 打住打住。
咱们说的是操作系统上的时间,以Linux来说,是有 "几点几分" 这种人可以友好读取的时间的,叫做RTC时间。和咱们时钟类似,装上电池,关机也不会丢。不过有点小问题,就是读取比较慢,现在CPU跑的又很快,这种读取感觉顶不住呀。于是操作系统想了个办法,每次初始化,先通过RTC获取当前时间,然后通过稳定的计数,最后按照单位换算成时间。这种只在内存中存在的时间就是系统时间,比如基于HZ计数的 jiffies,和独立时钟硬件计数的 hrtimer。
什么是转换器?
因为操作系统是通过计数来计算时间的,加入现在是2点,想要在9点执行,就是延迟7个小时,换成秒 7 * 3600。一个简单的写法就诞生了。
sleep 7 * 3600
do task
好学的童靴举起了手?咱们为啥不直接sleep N个计数呢?
由于计算机时钟计数取决于硬件,以CPU来说,各种HZ都有。每次写任务还要根据各个不同硬件去计算,这普通人哪里顶得住。于是内核提供了一些辅助函数用于jiffies和毫秒以及纳秒之间的转换。
unsigned int jiffies_to_msecs(const unsigned long j);
unsigned int jiffies_to_usecs(const unsigned long j);
unsigned long msecs_to_jiffies(const unsigned int m);
unsigned long usecs_to_jiffies(const unsigned int u);
听了这么久,大白童靴皱起了眉头,我就想每周生成了报表,你给我整这是弄啥子?
于是咱们的转换器应运诞生了,目标就一个,把对人友好的时间定义转为延迟多少执行,以及下次执行需要再次延迟多少时间。
举个例子
python轻量级定时任务schedule,打开首页第一行介绍就是
Python job scheduling for humans. Run Python functions (or any other callable) periodically using a friendly syntax.
大家豁然大悟,正准备交流一番。这时小黑同学冷冷一笑,"我用过,任务一多卡的一逼"
如何组织任务集?
瞬间冷场,这时灯光一闪,一段源码投了上来
def get_jobs(self, tag: Optional[Hashable] = None) -> List["Job"]:
···
if tag is None:
return self.jobs[:]
else:
return [job for job in self.jobs if tag in job.tags]
def get_next_run(self, tag: Optional[Hashable] = None) -> Optional[datetime.datetime]:
···
return min(jobs_filtered).next_run
对于大量数据来说,当Tick到来时想要找到最先要执行的,换成成时间戳,就是过期时间最小的。以列表组织数据,min方法是O(N)。那么有没有更高效的数据组织结构,咱们的要求如下:
- 稳定而快速的查找;
- 快速地插入和删除;
- 支持排序;
经过筛选,有几个数据结构都满足,比如树堆,红黑树,跳表,分层时间轮等。这也是大家比较常用的,其中分层时间轮类似页表,是O(1)操作,linux的定时任务、kafka的延迟任务都是高性能代表。树堆就是最小时间堆,可以基于数组,列表实现,实现起来简单,比如Java的DelayQueue。
Tick与空转
假设咱们想要的精度是1秒,简单的就是每次取出最小值,判定是否到期,是则继续,否则sleep等待。不过有个问题就是,每次操作时间是不确定的,sleep之后操作系统并不是立即执行,而是需要调度(比如CFS)也是需要一定时间的。那么操作系统是咋处理的,咱们看下图
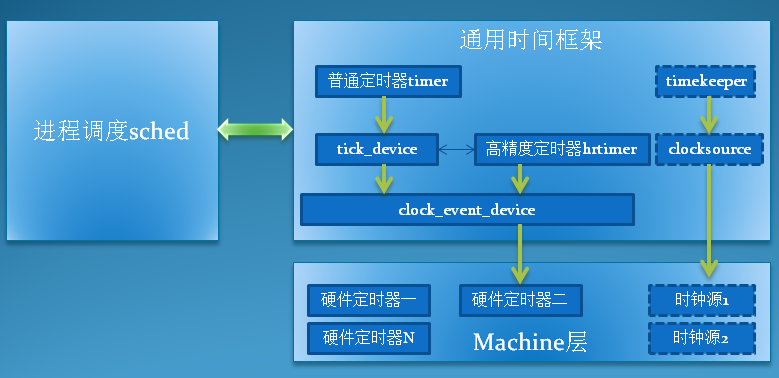
引自 Linux时间子系统之四:定时器的引擎:clock_event_device
有个思路,咱们注册一个特殊任务,每秒到了都通知咱们。这样每次收到Tick就是下一秒,咱们直接与最小值对比就行了。O(1)的分层时间轮必须得说,每次来了,就检测当前桶,取出桶内数据,全执行就行了,Linux定时任务就是这么实现的。但是任务很有可能都集中在某些桶,导致很多都是空桶,这样不就是白激动一场,都是空转呀。(其他结构每次Tick到来,比较最小值是否过期,没命中也是空转。)
但是能因为这个问题,就放弃O(1)吗?那肯定是不行的!
咱们换个思路,如果只把有任务的桶注册上去呢。首先大部分任务都集中在某些桶,因此整体注册的桶也不会很多,资源占用也不会很多,kafka延迟任务就是这么做的,借助DelayQueue实现Tick通知。
空转引申
既然空桶不注册,是不是可以移除,只把有任务的桶串联在一起。如果有新任务加入,先看看原先桶是不是能满足,不行就新增个桶,把桶插入原先的序列中,并且注册到定时器上。这么一阵操作,感觉空间一下子都省了下来了,但是问题来了,不用的桶都移除了,那么查找还能O(1)吗?Linux高精度定时器hrtimer就是这么做的,采用红黑树进行组桶,桶内也采用红黑树进行排序,这样能内存申请就轻松多了。
DelayQueue
操作系统能直接注册定时器,咱们虽然没有直接接口,但是也很容易封装一个。跳表与红黑树也不是内置,但是堆排序就算自己实现也很简单。咱们可以先实现一个优先级队列,然后再用锁通信wait和notify就能搞定。
- 读,先取出最小值进行过期判定,已过期就消费,然后继续。否则获取最小值与当前时间的差值,进行wait
- 写,写之前先取出最小值;然后插入,在取出最小值。如果不同,则说明有更小值的来了,通知消费者结束等待,重新判定。
- 队列为空,消费者直接等待即可
这样一个自给自足的Python DelayQueue就实现了,参考 https://github.com/maycap/dqueue
过期队列与执行器
如果是本地执行,一个queue,多线程直接消费就能搞定,轻松实现并发。如果任务需要多台机器,那么选择一个MQ,实现分布式消费。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号