图解CPU执行一段程序
程序执行
从打印出 Hello World 开始,程序如何运行起来,大家都很清楚。那么底层如何执行的呢,让我们一探究竟。
long main(){
long a = 1;
long b = 2;
return a + b;
}
来一段 C 语言作为例子, gcc -S 生成汇编代码,简化如下。
pushq %rbp
movq %rsp, %rbp
movq $1, -8(%rbp)
movq $2, -16(%rbp)
movq -16(%rbp), %rax
movq -8(%rbp), %rdx
addq %rdx, %rax
popq %rbp
ret
有点晕,让我们补个知识。在所有 cpu 体系架构中,每个寄存器通常都是有建议的使用方法的,而编译器也通常依照CPU架构的建议来使用这些寄存器,因而我们可以认为这些建议是编译器都遵守的。
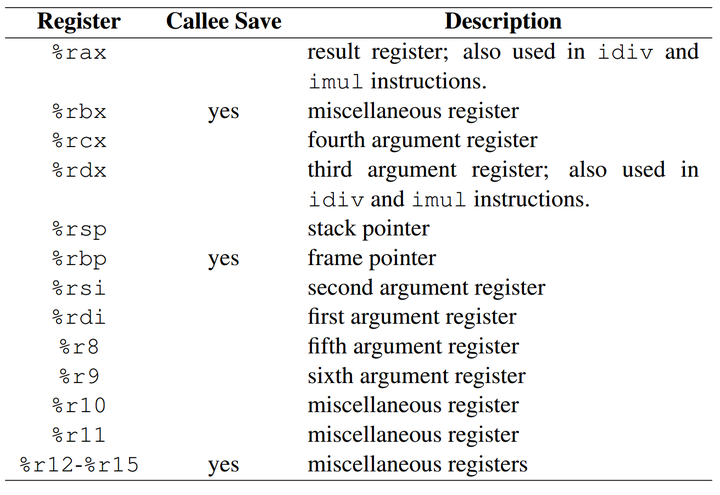
- %rax 通常用于存储函数调用的返回结果,同时也用于乘法和除法指令中。在imul 指令中,两个64位的乘法最多会产生128位的结果,需要 %rax 与 %rdx 共同存储乘法结果,在div 指令中被除数是128 位的,同样需要%rax 与 %rdx 共同存储被除数。
- %rsp 是堆栈指针寄存器,通常会指向栈顶位置,堆栈的 pop 和push 操作就是通过改变 %rsp 的值即移动堆栈指针的位置来实现的。
- %rbp 是栈帧指针,用于标识当前栈帧的起始位置
- %rdi, %rsi, %rdx, %rcx,%r8, %r9 六个寄存器用于存储函数调用时的6个参数(如果有6个或6个以上参数的话)。
- 被标识为 “miscellaneous registers” 的寄存器,属于通用性更为广泛的寄存器,编译器或汇编程序可以根据需要存储任何数据。
这里还要区分一下 “Caller Save” 和 ”Callee Save” 寄存器,即寄存器的值是由”调用者保存“ 还是由 ”被调用者保存“。当产生函数调用时,子函数内通常也会使用到通用寄存器,那么这些寄存器中之前保存的调用者(父函数)的值就会被覆盖。为了避免数据覆盖而导致从子函数返回时寄存器中的数据不可恢复,CPU 体系结构中就规定了通用寄存器的保存方式。
如果一个寄存器被标识为”Caller Save”, 那么在进行子函数调用前,就需要由调用者提前保存好这些寄存器的值,保存方法通常是把寄存器的值压入堆栈中,调用者保存完成后,在被调用者(子函数)中就可以随意覆盖这些寄存器的值了。如果一个寄存被标识为“Callee Save”,那么在函数调用时,调用者就不必保存这些寄存器的值而直接进行子函数调用,进入子函数后,子函数在覆盖这些寄存器之前,需要先保存这些寄存器的值,即这些寄存器的值是由被调用者来保存和恢复的。
看了这些文档介绍,回想下 图解CPU为何要乱序执行。CPU 执行单元并没有函数概念,只要指令和取值都准备好了,就可以执行。不过我们写程序一般都是一段程序(比如一个函数),外加信息作为上下文。翻译成指令,那肯定茫茫多,因此操作系统为了更好管理,设计了 Frame 用来封装一段相关联的代码。那么现在执行逻辑抽象如下。

程序执行模拟栈调用,我们结合图在看看刚才代码。
- 先把当前帧的信息保存起来, pushq %rbp
- 接着把要执行的帧赋给 %rpb, movq %rsp, %rbp
- 处理参数,先把参数读取入栈,然后再赋值给寄存器
- 取存和指令都满足了,那么就可以执行
- 把返回结果放入寄存器 %rax,和上一步可以一起完成, addq %rdx, %rax
- 执行完毕,把原来的栈信息取出,再放入 %rpb, popq %rbp
- 最后 ret 指令相当于 popq %rip,指向下一条指令
从栈调用来看,结合栈地址是从高到低,栈内参数位数对齐,紧密排布,那么相对的偏移量也是固定的。因此直接通过 %rbp 执行偏移取值,就可以完成变量的处理,因此我们也可以得出一个抽象栈内分布图如下。

总结
栈执行主要看 %rbp 指向谁,而 %rbp 又是通过 %rsp 赋值的,因此只要我们想办法把 %rsp 切换了就相当于换了执行单元的上下文环境。现在协程很流行,按照这个思路,大家是不是可以构思一下协程如何实现了~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号