
图解CPU为何要乱序执行
流水线执行
脑补 CPU 执行是这样。

不过几乎所有的冯·诺伊曼型计算机的CPU,其工作都可以分为 5 个阶段:取指令、指令译码、执行指令、访存取数、结果写回。

1. 取指令阶段
取指令(Instruction Fetch,IF)阶段是将一条指令从主存中取到指令寄存器的过程。 程序计数器 PC 中的数值,用来指示当前指令在主存中的位置。
2. 指令译码阶段
取出指令后,计算机立即进入指令译码(Instruction Decode,ID)阶段。 在指令译码阶段,指令译码器按照预定的指令格式,对取回的指令进行拆分和解释,识别区分出不同的指令类别以及各种获取操作数的方法。
3. 执行指令阶段
在取指令和指令译码阶段之后,接着进入执行指令(Execute,EX)阶段。 此阶段的任务是完成指令所规定的各种操作,具体实现指令的功能。
4. 访存取数阶段
根据指令需要,有可能要访问主存,读取操作数,这样就进入了访存取数(Memory,MEM)阶段。
5. 结果写回阶段
作为最后一个阶段,结果写回(Writeback,WB)阶段把执行指令阶段的运行结果数据“写回”到某种存储形式:结果数据经常被写到CPU内部寄存器中,以便被后续的指令快速地存取;在有些情况下, 结果数据也可被写入相对较慢、但较廉价且容量较大的主存。许多指令还会改变程序状态字寄存器中标志位 的状态,这些标志位标识着不同的操作结果,可被用来影响程序的动作。
在指令执行完毕、结果数据写回之后,若无意外事件(如结果溢出等)发生,计算机就接着从程序计数器PC中取得下一条指令地址,开始新一轮的循环,下一个指令周期将顺序取出下一条指令。

指令重排
我们引现在CPU Nehalem 微架构如下,揭开它的神秘面纱。
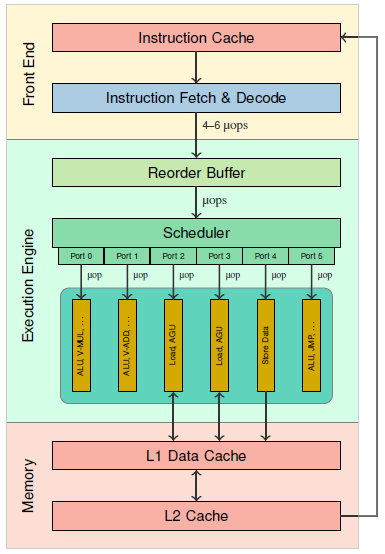
乍一看不明觉厉,我们从出现频率高的 μop | Micro Operation(micro-op)入手。它是类 RISC (精简指令集或简单指令集)处理器导致的一项设计,从 Pentium Pro 开始在 IA 架构出现。处理器接受的是 x86 指令(CISC 指令,复杂指令集),而在执行引擎内部执行的却不是x86 指令。
RISC 架构的特点就是指令长度相等,执行时间恒定(通常为一个时钟周期),因此处理器设计起来就很简单,可以通过深长的流水线达到很高的频率,IBM 的 Power6 就可以轻松地达到 4.7GHz 的起步频率。和 RISC 相反,CISC 指令的长度不固定,执行时间也不固定,因此 Intel 的 RISC/CISC 混合处理器架构就要通过解码器 将 x86 指令翻译为 uop,从而获得 RISC 架构的长处,提升内部执行效率。
x86 指令大部分简单指令可以翻译为一对一翻译,复杂的可能 1 ~ 4 条 μops。解码器是按位数取指的,在经过译码,因此每次可能产生多条 μops。计算机执行符合局部性原理,这里不仅指同个指令可能重复执行,也指内存访问。而内存访问显然是比较慢的,对多条指令重新排序,把访存相关的堆一起,显然是可以提升效率的。
ROB(Re-Order Buffer,重排序缓冲区)是一个非常重要的部件,它是将乱序执行完毕的指令们按照程序编程的原始顺序重新排序的一个队列,以保证所有的指令都能够逻辑上实现正确的因果关系。
并行执行
Nehalem 具备 6 个执行端口,每个执行端口具有多个不同的单元以执行不同的任务,然而同一时间只能有一条指令(uop)进入执行端口,因此也可以认为 Nehalem 有 6 个“执行单元”,在每个时钟周期内可以执行最多 6 个操作(或者说,6 条指令)。
然而这些执行端口并不都是用于计算,实际上,有三个执行端口是专门用来执行内存相关的操作的,只有剩下的三个是计算端口。其余三个用来存取单元,一个用于所有的 Load 操作(地址和数据),一个用于 Store 地址,一个用于 Store 数据。
据统计 Load 操作占据了通常程序的 1/3 左右,并且 Load 操作可能会导致巨大的延迟(在命中的情况下,Nehalem 则为 4 个时钟周期。L1 未命中时则会访问 L2 缓存,一般为 10~12 个时钟周期。访问 L3 通常需要 30~40 个时钟周期,访问主内存则可以达到最多约 100 个时钟周期)。所以CPU执行会尽可能使用已 Load 到寄存器的数据,一些编译器优化也是如此操作,把一些经常使用的数值直接写入寄存器,都是一个道理。
会出现啥问题?
乱序执行本身不会产生问题(寄存器重命名等),保证单个 CPU 执行快速高效。为啥还有 volatile 这个经典问题呢?别急,我们先总结下 CPU 为了加速执行引入的手段。
- 指令细分,流水线执行
- 多堆硬件,指令重排并行执行
- 原地访问,尽量不访存
这里有意跳过超线程/同步多线程(HT/SMT)技术,因为 同步多线程(SMT,Simultaneous Multithreading)为额外线程也增加了对应的上下文晶体管,不会产生影响。
流水线执行
指令拆分之后,可能会分为多条指令,不是原子操作。那么问题就来了,比如多线程同时执行 i++ ,刚执行 100 条指令,突然线程切换了。等到回来继续执行,假设执行到回写,这就冲突了,不管丢弃还是强刷,结果肯定不对了。为了保证原子性操作,互斥资源可以上锁,同时只让一个 CPU 执行。
乱序执行
先看经典案例
// CPU0
void foo() {
a = 1;
b = 1;
}
// CPU1
void bar() {
while (b == 0) continue;
assert(a == 1);
}
我们分析下,在这个代码块中,CPU0 执行 foo 函数,CPU1 执行 bar 函数。但在对变量 a 和 b 进行赋值的时候,有两种情况会导致它们的赋值顺序被打乱。
- CPU 乱序执行,因为 a 和 b 是无关的
- 在写回时,有可能 b 所对应的缓存行会先于 a 所对应的缓存行进入独占状态,也就是说 b 会先写入缓存
这里有人会疑问,那 MESI 一致性协议干啥去了?
这是因为 MESI 在 Share 状态下,如果一个核想独占缓存进行修改,就需要先给所有 Share 状态的同伴发出 Invalid 消息,等所有同伴确认并回复它“Invalid acknowledgement”以后,它才能把这块缓存的状态更改为 Modified,这是保持多核信息同步的必然要求。这个过程相对于直接在核内缓存里修改缓存内容,非常漫长。这也就会导致,某个核请求独占时间比较长。因此操作系统并没有严格遵守,而是提供内存屏障轻量级实现最终一致性。
原地访问
都没访问内存,寄存器是 CPU 独占的,MESI 又没严格实现,另个 CPU 访问过期数据管它啥事。
总结
CPU 为了加快执行引入了流水线、堆硬件、指令重排、并行执行、原地访问等技术。而 MESI 很重量级,操作系统并未实现,提供了轻量级的内存屏障。引发了原子问题,以及并发问题,可以通过 Lock 和 volatile 解决。
题外
这样是不是记得更牢了,遇到问题如何选择也有依据了~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号