HDFS读文件详解
通过对客户端简单读取数据的源码(见图3.1)的执行进行跟踪,可以窥探到客户端是如何读取到数据的。
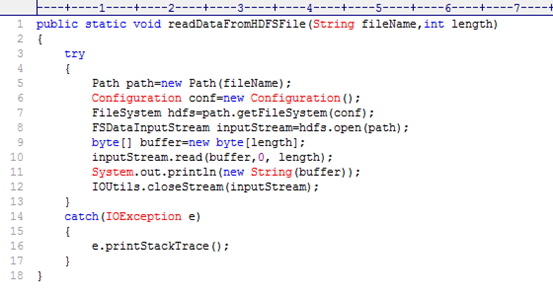
图3.1 客户端简单读取数据的源码
下面开始解释第5行到第12代码:
第5行:根据文件的名字fileName构造一个Path类的对象path。
第6行:初始化一个Configuration变量conf。
第7行:根据path的成员函数getFileSystem()传入参数conf获得文件系统hdfs变量。
以上三行根据文件名,得到一个FileSystem类的对象hdfs,其实hdfs是FileSystem子类DistributedFileSystem的一个对象。此处hdfs为何为DistributedFileSystem一个对象,由于和需求无关,故不作深入解释,你只需知道hdfs是根据conf变量和文件名fileName决定的就可以了。
第8行:文件系统变量hdfs调用open()方法传入参数path得到一个输入流。
此处对open方法进行详细解释。
3.1 hdfs.open()详解
3.1.1 FileSystem.open(path)
Hdfs.open(path)是调用基类FileSystem的open(path)函数,图3.2为FileSystem的open()函数:
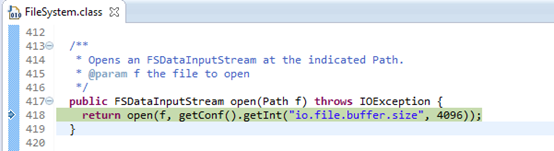
图3.2 FileSystem的open(path)函数
FileSystem.open(path)又调用FileSystem的抽象方法open(path, size)。
3.1.2 FileSystem.open(path, size)
图3.3为FileSystem的open(path, size)函数:
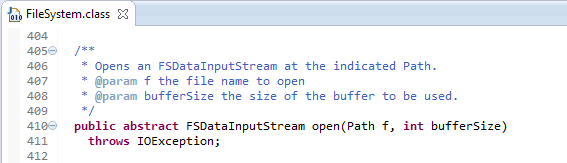
图3.3 FileSystem的抽象方法open(path, size)
抽象方法的实现是在子类中实现的,故实际调用的是子类的DistributedFileSystem实现的open(path, size)方法。
此处为何代码"FileSystem hdfs=path.getFileSystem(conf)"返回的是子类DistributedFileSystem的一个实例,这是根据path和conf共同决定的,具体分析,详见以后的分析,此处先不详述。
3.1.3 DistributedFileSystemd.open(path, size)
图3.4为DistributedFileSystem.open(path, size)的实现:
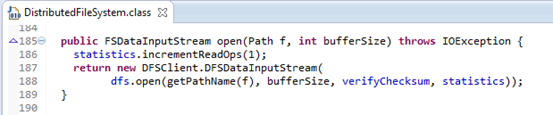
图3.4 DistributedFileSystemd的open(path, size)
图3.4中188行的dfs为DFSClient类的一个实例,DFSClient通过代理模式(用到了hadoop实现的RPC类)建立与NameNode的socket连接,具体细节不必深究,只需要知道DFSClient的功能即可。DFSClient的open(String src, int buffersize, boolean verifyChecksum, FileSystem.Statistics stats)方法返回一个DFSInputStream对象。
3.1.4 DFSClient.open(String src, int buffersize, boolean verifyChecksum, FileSystem.Statistics stats)
图3.5为DFSClient的open(String src, int buffersize, boolean verifyChecksum, FileSystem.Statistics stats)实现:
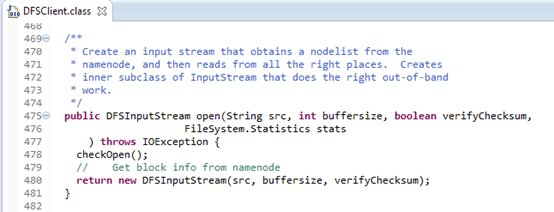
图3.5 DFSClient的open()方法
第478行检测clientRunning是否正在运行。
第480行根据DFSInputStream的构造函数:
DFSInputStream(String src, int buffersize, boolean verifyChecksum)构造一个DFSInputStream对象,DFSInputStream对象的构造详见3.1.5节。
3.1.5 DFS.checkOpen()
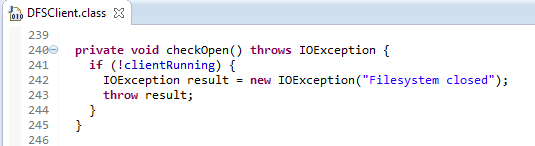
图3.6 DFS的checkOpen()方法
检测clientRunning是否正在运行,没有运行则抛出异常。
3.1.6 DFSInputStream.DFSInputStream(String src, int buffersize, boolean verifyChecksum)
DFSInputStream的构造函数见下图3.7:
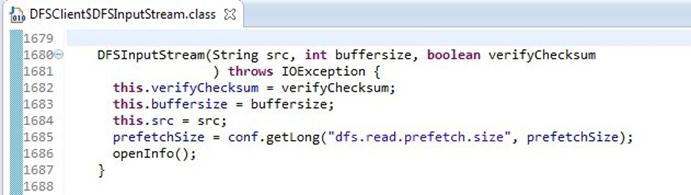
图3. 7 DFSInputStream构造函数
DFSInputStream构造函数的前四行(即1682、1683、1684、1685行),分别在初始化一些参数;第1686行的openInfo(),它内部建立了与NameNode 的连接,通过调用DFSClient的callGetBlockLocations(namenode, src, 0, prefetchSize)。
3.1.7 DFSInputStream.openInfo()
DFSInputStream. openInfo()详见下图3.8:
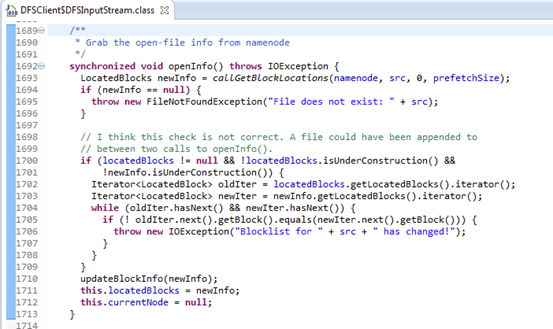
图3.8 DFSInputStream. openInfo()
图3.8的1693行调用DFSClient的方法callGetBlockLocations()。
callGetBlockLocations()函数的定义可以看出,它是调用了namenode 的getBlockLocations()方法;而namenode 的getBlockLocations()方法为:依据代理实现的对NameNode进行的远程过程调用,详见3.1.7节。
在第一次调用openInfo()时,DFSInputStream类的成员变量locatedBlocks为NULL,故不会执行图3.8的1700到1709这段代码。
第1710行updateBlockInfo(newInfo),在文件构造过程中,基于从datanode返回的block长度,更新最后一个block的大小。
第1711行,将DFSClient的callGetBlockLocations(namenode, src, 0, prefetchSize)方法返回的LocatedBlock变量赋给DFSClient的成员locatedBlocks。
3.1.8 DFSClient.callGetBlockLocations()
DFSClient的方法callGetBlockLocations()详见图3.9:
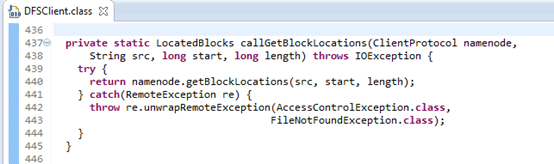
图3.9 DFSClient的callGetBlockLocations()
由图3. 9中callGetBlockLocations()函数的定义可以看出,它调用了namenode 的getBlockLocations()方法;而namenode 的getBlockLocations()方法为:依据代理实现的对NameNode进行的远程过程调用。namenode变量为一个ClientProtocol对象。
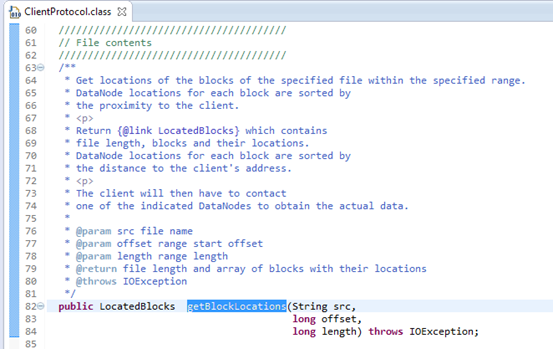
图3.10 ClientProtocol接口的getBlockLocations()
3.1.9 DFSInputStream.updateBlockInfo(LocatedBlocks newInfo)
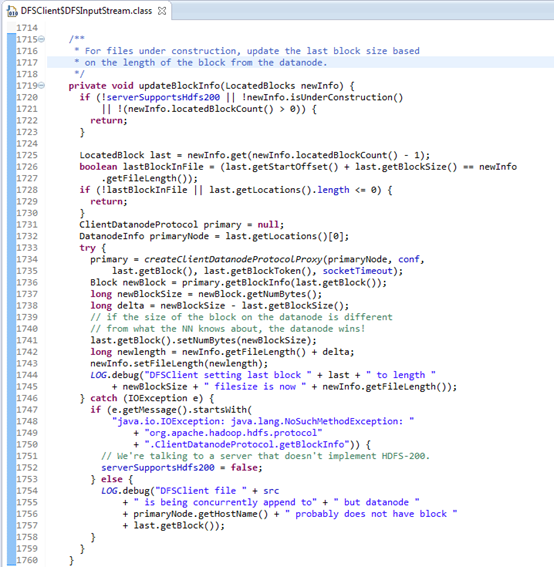
图3. 11 DFSInputStream.updateBlockInfo(LocatedBlocks newInfo)
DFSInputStream的updateBlockInfo(LocatedBlocks newInfo),在文件构造过程中,基于从datanode返回的block长度,更新最后一个block的大小。
3.2 FSDataInputStream.read()详解
下面通过对读文件简单例子的分析,得出最外层面向开发者的FSDataInputStream.read(byte b[], int off, int len)的本质,最后帮助修改,解决需求(指定DataNode进行数据块读取)。
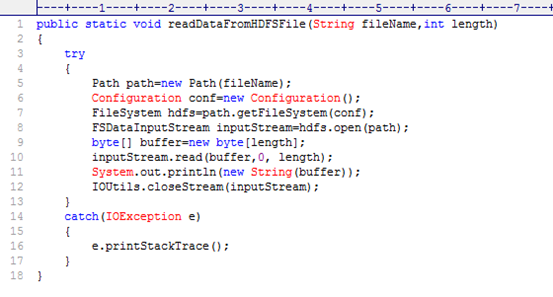
图3.12 客户端简单读取数据的源码
由图3.12第8行:
FSDataInputStream inputStream=hdfs.open(path);
可以看出open()函数返回了一个FSDataInputStream流对象,然后对这个流对象就行读操作,从表象看来确实如此,其实不然。
3.2.1 FSDataInputStream.read(byte b[], int off, int len)
究其实现可以看出,FSDataInputStream.read(byte b[], int off, int len)调用的是其父类DataInputStream的read(byte b[], int off, int len),图3.13为FSDataInputStream的继承关系:
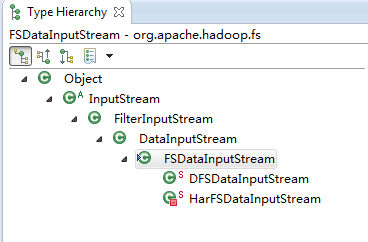
图3.13 FSDataInputStream继承关系
3.2.2 DataInputStream.read(byte b[], int off, int len)
而DataInputStream. read(byte b[], int off, int len)调用的是其成员的in的read(byte b[], int off, int len),见图3.14:

图3.14 DataInputStream. read(byte b[], int off, int len)
此处的read()需要特殊说明一下,in的read是从输入流in中读取长度为len的数据存放在b[] byte数组的off之后(包括off)的元素中,而不是我们通常所理解的那样。下面为英文解释:
The first byte read is stored into element b[off], the next one into b[off+1], and so on. The number of bytes read is, at most, equal to len. Let k be the number of bytes actually read; these bytes will be stored in elements b[off] through b[off+k-1], leaving elements b[off+k] through b[off+len-1] unaffected.
3.2.3 DataInputStream.in是什么
DataInputStream的成员in是什么呢,我们看其父类FilterInputStream,图3.15:
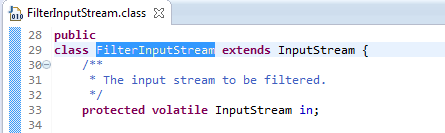
图3.15 FilterInputStream的成员变量in
追溯到FilterInputStream类就知道了:
FSDataInputStream.read(byte b[], int off, int len)调用其父类DataInputStream的read(byte b[], int off, int len);
DataInputStream的read(byte b[], int off, int len)调用的是其成员变量InputStream in的read方法(byte b[], int off, int len)。
此处又出现了一个问题,这个类型为InputStream的in(真正的输入流)是怎么传进来的。
3.2.4 真正的输入流in
下面通过DFSInputStream类的继承关系和hdfs.open(path)的部分过程详解真正的输入流的构造生成过程。
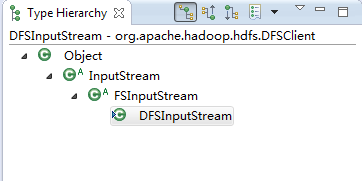
图3.16 DFSInputStream类继承关系
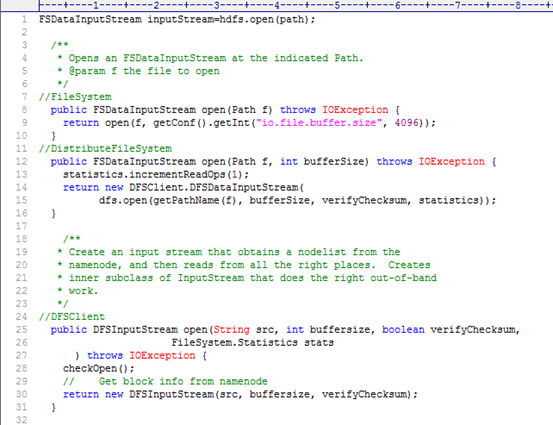
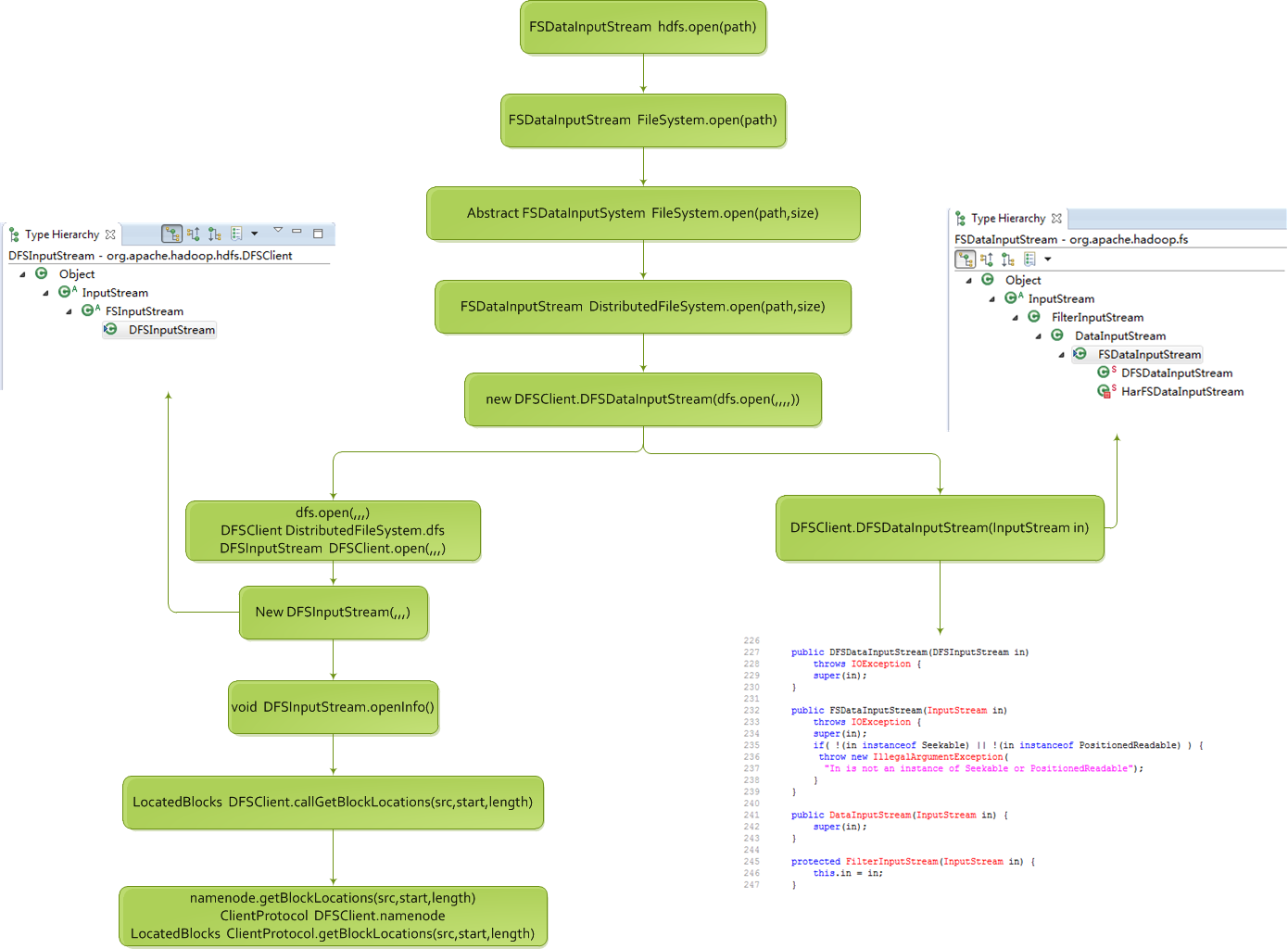
图3.17 hdfs.open()获得流过程
我们由图3.17的hdfs.open()获得流过程的代码由下向上看(也可借鉴3.1.3小节)。
第30行构造了一个DFSInputStream变量并返回(此处记为a,方便下面描述解释)。
第15行的dfs.open(……)的返回值就是上一行所述的构造的DFSInputStream变量a。
第14行是根据15行构造的DFSInputStream变量a作为DFSClient的内部类DFSDataInputStream的构造函数的参数,下图3.18为DFSDataInputStream的构造函数的执行过程:
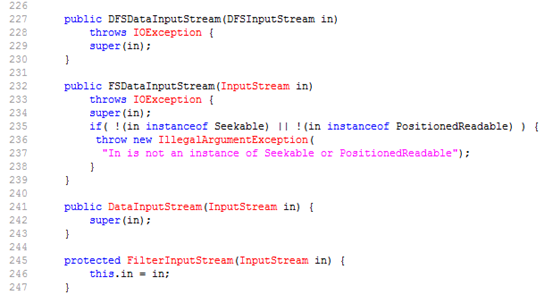
图3.18 DFSDataInputStream的构造函数的执行过程
由图3.18可以看出,执行到最后,其实是将DFSInputStream类的对象a赋给DFSDataInputStream类的成员变量in,类DFSDataInputStream类的成员变量in为InputStream类型。
故图3.17的第14行最后返回了一个(带有类型为DFSInputStream的输入流in的成员变量)DFSDataInputStream对象。
图3.17的第9行返回一个DFSDataInputStream对象。
图3.17的第8行返回一个DFSDataInputStream对象。
故图3.17的第1行:
FSDataInputStream inputStream=hdfs.open(path);
返回了一个(带有类型为DFSInputStream的输入流in的成员变量)DFSDataInputStream对象,到最后返回给它的直接父类FSDataInputStream的对象。下面一节对DFSInputStream的read()方法进行分析。
附件1
hdfs.open(path)执行流程: