java多线程
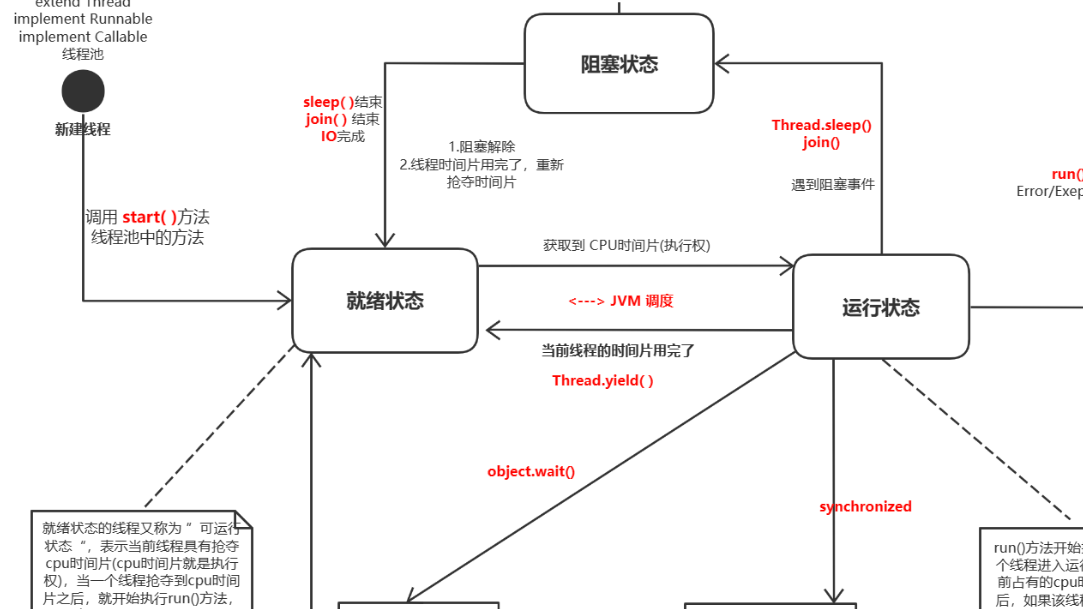 java多线程面试总结
java多线程面试总结
java中创建线程方式:
继承Thread类;
实现Runnable接口;
Callable接口:可以拿到任务的结果;
线程池:
不建议用Executors的方式创建线程池;
为什么:newFixThreadPool:LinkedBlockingQueue,(这个队列是无数的),线程池线程数量少,但是进来的线程数量多,导致OOM。
线程池的状态:
RUNNING:正常运行;SHUTDOWN:正在关闭状态,线程池不会接受新任务,但是会吧队列中的任务处理完;STOP:停止状态,线程池不会接受新任务,也不会处理队列中的任务;TIDYING:TERMINATED。
线程池核心参数:
corePoolSize:核心线程数;
maximmPoolSize:最大线程数目;
workQueue:阻塞队列;
keepAliveTime:针对救急线程;
handle:拒绝策略;
Sychronized和ReentrantLock不同点:
| sychronized | ReentrantLock |
|---|---|
| Java中的关键字 | JDK提供的一个类 |
| 自动加锁与释放锁 | 需要手动加锁和释放锁 |
| JVM层面的锁 | API层面的锁 |
| 非公平锁 | 公平锁和非公平锁 |
| 锁的是对象,锁信息保存在对象头中 | int类型和state标识来标识锁状态 |
| 底层有锁升级过程 | 没有锁升级过程 |
ThreadLocal有哪些应用场景?它底层是如何实现的?
-
Threadlocal是Java中所提供的线程本地存储机制,可以利用该机制将数据
缓存在某个线程内部,该线程可以在任意时刻、任意方法中获取缓存的数据 -
Threadlocal底层是通过 ThreadLocalMap来实现的,每个 Thread对象(注意不是ThreadLocal对象)中都存在一个 Threadlocalmap,Map的key为 Threadlocal对象,Map的value为需要缓存的值。
-
可能导致内存泄漏,(因为是线程池指向),每次使用之后需要使用remove释放掉。
ReentrantLock分为公平锁和非公平锁,那底层分别是如何实现的?
首先不管是公平锁和非公平锁,它们的底层实现都会使用AQS来进行排队,它们的区别在于线程在使用lock0方法加锁时
- 如果是公平锁,会先检查AQS队列中是否存在线程在排队,如果有线程在排队,则当前线程也进行排队
- 如果是非公平锁,则不会去检查是否有线程在排队,而是直接竞争锁。
Tomcat为什么要自定义类加载器:
针对每一个类,都有一个自定义类加载器,不同的类判别:名字和类加载器,隔离应用。
线程安全的理解:
多个线程运行时,运行结果是否正确,相互之间是否会造成干扰。
守护线程:
JVM的后台线程,垃圾回收线程。
一直在运行,所有线程运行结束之后,结束运行。
死锁:
互斥、占有并等待、非剥夺、循环等待。
谈谈你对AQS的理解,AQS如何实现可重入锁?
- AQS是一个JAVA线程同步的框架。是JK中很多锁工具的核心实现框架。
- 在AQS中,维护了一个信号量 state和一个线程组成的双向链表队列。其中,这个线程队列,就是用来给线程排队的,而 state就像是一个红绿灯,用来控制线程排队或者放行的。在不同的场景下,有不用的意义。
- 在可重入锁这个场下, state就用来表示加锁的次数。0标识无锁,每加次锁, state就加1。释放锁 state就减1。
线程池的底层工作原理:
线程池内部是通过队列+线程实现的,当我们利用线程池执行任务时,
- 如果此时线程池中的线程数量小于 core poolsize,即使线程池中的线程都处于空闲状态,也要创建新的线程来处理被添加的任务。
- 如果此时线程池中的线程数量等于 corepoolsize,但是缓冲队列 workqueue未满,那么任务被放入缓冲队列。
- 如果此时线程池中的线程数量大于等于 corepoolsize,缓冲队列 workqueue满,并且线程池中的数量小于 maximum Poolsize,建新的线程来处理被添加的任努。
- 如果此时线程池中的线程数量大于 corepoolsize,缓冲队列 workqueue满,并且线程池中的数量等于 maximum Poolsize,那么通过 handler所指定的策略来处理此任
- 当线程池中的线程数量大于 corepoolsize时,如果某线程空闲时间超过 keepalivetime,线程将被终止。这样,线程池可以动态的调整池中的线程数
core不足,来了新任务,创建新线程;
core足够,队列未满,来了新任务,加入队列;
core满了,队列满了,来了新任务,创建新线程。
HashMap的put方法:
-
根据key通过
哈希算法的“与运算”得到数组下标; -
如果数组下标位置为空,将key和value封装成Entry对象(1.7位Entry,1.8位Node对象);
-
如果不为空:
1.7:是否需要扩容(是否存在key),生成Entry对象,头插法;
1.8:判断是红黑树Node还是链表Node:
红黑树;
链表:尾插法,大于等于8个,需要插入,转换成红黑树。
最后判断是否扩容。
1.7、1.8HashMap区别:
1.7:数组+链表;头插法;
1.8:数组+链表+红黑树;尾插法(判断链表节点个数);
HashMap的扩容机制:
https://zhuanlan.zhihu.com/p/114363420
Colections.synchronized...
Lock vs Synchronized:
都是悲观锁;可重入锁(可以给多个对象加多道锁)
lock:接口,java实现,自己释放(wait、signal)
支持获取等待状态、公平锁、可打断、可超时、多条件变量
有多个场景的实现:ReentranLock,ReentrantReadWriteLock
synchronized:关键字,c++实现;自动释放,
乐观锁和悲观锁:
悲观锁:获取锁失败的线程,进入阻塞状态,(实际上,获取的锁被占用时,或尝试重复操作)
乐观锁:需要多CPU的支持,如果碰到锁被占用,一直尝试。
CAS保证了原子性:
compareAndSet:
比如说,n = o + 5;
U.compareAndSetInt(account, BALANCE,o,n);
如果初始值o为10,那么这个会比较是否是15,如果是,那么返回true,如果不是,那么返回False,这样保证了操作的原子性,也就是如果其他线程干扰导致结果不同,那么就返回false,这种情况适用于乐观锁,不断尝试直到获取成功。
但是存在ABA问题,(先+5,再-5,好像没变一样,但是实际其他线程干扰了),使用版本号问题解决。
concurrentHashMap:
1.7:扩容是指segment下面的小数组,segment并不扩容;
1.8:链表扩容迁移时,需要重新创建链表,因为如果碰见查找的时候,应该查找原来的链表,如果按照原链表迁移,那么查找会出现问题,比如它的next节点等等发生改变。
put的时候,在put链表的时候,会阻塞。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)