
linux 运维笔记
cat
cat是一个文本查看工具,查看一个文件的内容用cat比较简单,其中最简单的用法就是cat后面直接加文件名
[root@centos7 ~]# cat /etc/fstab
cat 的语法结构
cat [OPTION]... [FILE]...
常用选项
-n 对输出的所有行编号
-A 显示输出文件中所有隐藏的符号
tac
tac 是将一个文件从最后一行开始倒过来输出到屏幕,tac实际上就是cat反过来写,这个命令并不是很常用。
rev
rev是指将一个文件的内容的每一行从最后一个字符到开始的字符反过来显示
more 和 less
相比cat和tac来说,more和less就好用多了,首先前面的两个打开大文件的时候会一次性打开输出到屏幕,而后者打开后可以利用快捷键一点点的往下看。
less的功能和more相似,但是使用more无法向前翻页,只能往后翻页
head 和 tail
head和tail通常使用在只需要读取文件的前几行和后几行中使用(默认显示前十行和后十行)
head 的语法结构
head -n# file
tail 的语法结构
tail -n# file
wc
wc的功能是统计文件中的单词数 行数 字节数,并将统计结果输出到屏幕上
wc 的语法结构
wc [OPTION]... [FILE]...
常用选项
-l 统计行数
-w 统计单词数
-c 统计字符数
cut
cut以某种方式按照指定的格式对文件的行进行切割
cut的语法结构
cut [OPTION]... [FILE]...
常用选项
-d 自定义分隔符
-f 与-d一起使用,指定显示那个区域
sort
sort 将文件的每一行相互比较,比较原则是从首字符向后,最后将他们按升序排序输出到屏幕
sort的语法结构
sort [OPTION]... [FILE]...
常用选项
-n 依照数值的大小进行排休
-r 以相反的顺序进行排序
-t 指定分隔符
-k 配合-t使用,指定显示那个字段
uniq
uniq 检查及删除文件中重复的行,一般配合sort使用
uniq的语法结构
uniq [OPTION]... [INPUT [OUTPUT]]
常用选项
-u 显示不重复的行
-d 显示重复的行,仅显示一行
-c 在每行旁边显示该行重复的次数
find
find命令用于在指定的目录下查找文件,如果不使用参数,find默认在当前目录下查找子目录和文件,并将查找到的子目录和文件全部显示
find的语法结构
find option path
常用选项
find / -amin -10 # 查找在系统中最后10分钟访问的文件
find / -atime -2 # 查找在系统中最后48小时访问的文件
find / -empty # 查找在系统中为空的文件或者文件夹
find / -group cat # 查找在系统中属于groupcat的文件
find / -mmin -5 # 查找在系统中最后5分钟里修改过的文件
find / -mtime -1 #查找在系统中最后24小时里修改过的文件
find / -nouser #查找在系统中属于作废用户的文件
find / -user fred #查找在系统中属于fred这个用户的文件
locate
跟find类似,不过这个不是实时查找,Locate查找实在自己的数据库中查找,如果刚建的文件或目录没有立即同步到数据库,Locate就会找不到
优点是查找到数据的时间快,缺点,数据不是实时更新的
updatedb 更新Locate数据库
压缩 解压缩和归档
compress/uncompress:.z
gzip/gunzip:.gz
bzip2/bunzip2:.bz2
xz/unxz:.xz
zip/unzip
tar,cpio
正则表达式
1 关于正则表达式
处理字符串时,有很多较为复杂的字符串用普通的字符串处理无法完成,比如说可能验证一个“email"的合法性,为此需要查看好多不容易查到的规则,这正是正则表达式的
用武之地,正则表达式是功能强大而简明的字符组,其中可以包含大量的逻辑,特别值得一提的是正则表达式相当简短
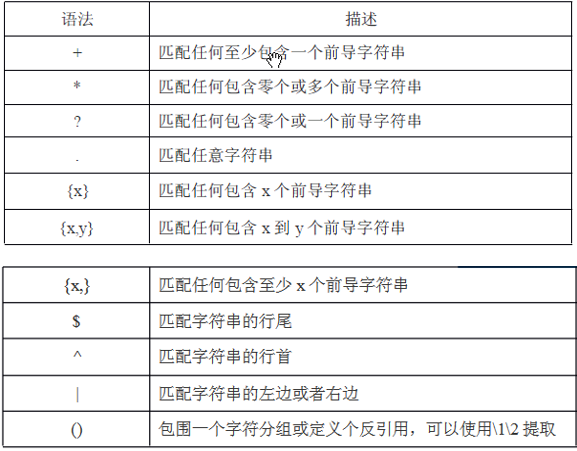
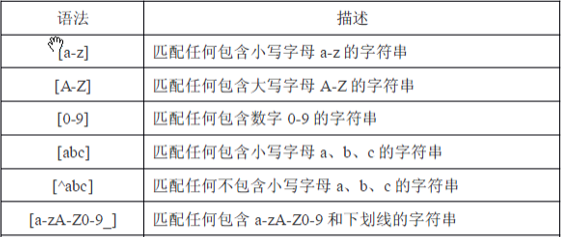
2 正则表达式的元素
grep
作为linux中最为常用的三大文本(grep sed awd)处理之一,掌握其用法是很有必要的
grep家族一共有三个 grep egrep fgrep
grep 的语法结构
grep [OPTIONS] PATTERN [FILE...]
常用选项
-o 只显示匹配到的字符串
-v 只打印没有被匹配的,匹配到的反而不打印
-i 忽略大小写
-n 显示行号
-E 开启扩展的正则表达式 等同于egrep
注:
默认情况下,正则表达式的匹配工作是贪婪模式,也就是说尽可能长的去匹配。
所有的正则字符在匹配的时候需要用 “\”去转义
egrep
用法同grep相同,只是这个是扩展的正则表达式,正则字符不需要再去使用“\"去转义了

sed
sed 是流编辑器,能够完美的配合正则表达式使用。处理时,把当前处理的行加载到模式空间,然后用sed命令在模式空间处理后,输出到屏幕。紧接着处理下一行,这样不断
重复,知道处理到文件的最后一行。处理完后原文件内容没有改变,除非你重定向或者使用了 -i 选项
sed 的语法结构
sed [OPTION]... {script-only-if-no-other-script} [input-file]...
常用选项
-i 修改原文件
-n 显示处理后的结果
-r 匹配的内容可以使用正则表达式匹配
定址
定址用于决定对那些行进行编辑,定址的形式可以以数字,正则表达式或二者结合使用,如果没有定址,sed 默认处理文件的每一行
定址是一个数字,则表示行号,$表示最后一行
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
打印第一行到第十行的内容
地址是以逗号分隔开的,那么处理这几行的内容需要加上逗号,范围也可以用数字,正则表达式以及二者的结合
打印/etc/passwd 文件以 root 开头到 lp 开头的中间的行
命令

变量
$BASHPID 显示当前bash进程的PID号
$PPID 显示当前进程的父进程PID号
删除变量
unset VLNAME
定义环境变量
export NAME=VALUE (如果想长久有效,可写在文件 (/etc/profile.d/) 中
位置变量
$NUMBER
例:
$0 指的是脚本本身
$1 指的是脚本的第一个参数
$2 指的是脚本的第二个参数
$# 参数的个数
$* 打印出所有参数(如果用$*传递给下一个脚本当参数,它会把参数当成一个整体)
$@ 打印出所有参数 (如果用$@传递给下一个脚本当参数,它会把参数当成每个独立的参数)
bash运算符

算术运算符
算术运算符是指在程序中执行加,减,乘,除等数学运算的算术符,shell中经常使用的数学运算符如下
+:对两个变量做加法。 -:对两个变量做减法。
*:对两个变量做乘法。 /:对两个变量做除法。
%:取模运算,第一个变量除以第二个变量求余数。 +=:加等于,在自身基础上加第二个变量。
-=:减等于,在第一个变量的基础上减去第二个变量。 *=:乘等于,在第一个变量的基础上乘以第二个变量。
/=:除等于,在第一个变量的基础上除以第二个变量。 %=:取模赋值,第一个变量对第二个变量取模运算,再赋值给第一个变量
在使用这些运算符的时候需要注意,例如
在做 1+2 的运算的时候,我们可以使用 let 或 $[ ] 来做运算
例如我们在做1+2运算的时候,
let b=1+2 ; echo $b
echo $[1+2]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号