
Spark笔记05 - 部署
- Understanding Cluster
- Deploying to a Cluster
- Spark Submit Job
Understanding Cluster
在运行Spark时,有两种模式,一种是Local,一种是Cluster。顾名思义,前者是单点的,后者是集群的。对于不同的模式,在写代码的时候还是有区别的。
- Print RDD
如果调用如下方法,那么是在各个的executor上打印出结果,而不是在driver上打印出所有的结果:
rdd.foreach(println)
rdd.map(println)
如果想要显示所有结果,需要用collect():
rdd.collect().foreach(println)
上述方法有个缺陷是太耗时了,所以如果只是为了看下数据的话可以使用采样方法take()只看一部分:
rdd.take(100).foreach(println)
- Accumulator
再举一例,想要统计data的总和,运用如下代码实现。但需要注意的一点是,这里的counter是“局部”变量,而不是“全局”变量,每个executor上都有一个counter,最终需要再reduce求和。
var counter = 0
var rdd = sc.parallelize(data)
// Wrong: Don't do this!!
rdd.foreach(x => counter += x)
println("Counter value: " + counter)
如果不reduce可以吗?也可以,这里就需要用到Spark自带的Accumulator,相当于是全局变量。
总结:在写代码的时候,一定要时刻想着,如果跑在Cluster上行不行?因为有些时候Local能跑,Cluater不一定能跑。而Cluster能跑,Local一定能跑。
Deploying to a Cluster
首先,需要打好包上传到服务器上。如果是Scala/Java,就是jar;如果是Python,那就是zip或者egg。
然后,需要在服务器上运行对应命令启动。举例如下:
# Run on a Spark standalone cluster in client deploy mode
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
其中,很两个很重要的参数
--master <master-url>: The master URL for the cluster--deploy-mode <deploy-mode>: Whether to deploy your driver on the worker nodes (cluster) or locally as an external client (client) (default: client)
为了方便理解,需要重新缕一缕Spark中master、worker、executor和driver的关系。
master和worker节点
- master节点常驻master守护进程,负责调度和worker节点通信。
- worker节点常驻worker守护进程,负责管理executor进程。
一台机器可以同时作为master和worker节点。比如三台机器,A是master+worker,BC是worker。
driver和executor进程
- driver进程
- 负责启动main()函数并且构建sparkContext对象。
- 并向集群管理者(master)申请spark应用所需的资源,也就是executor。
- 然后将应用拆分为多个stage,并创建对应tasks。
- 然后将各个任务分配到executor中执行。
- 最后再将结果汇总起来。
- executor进程
- 负责执行task,并返回结果给driver。
Driver可以起在master节点上,也可以起在worker节点上,由deploy-mode决定,如下:
client_mode中,Driver起在提交request的worker上

cluster_mode中,Driver起在master上
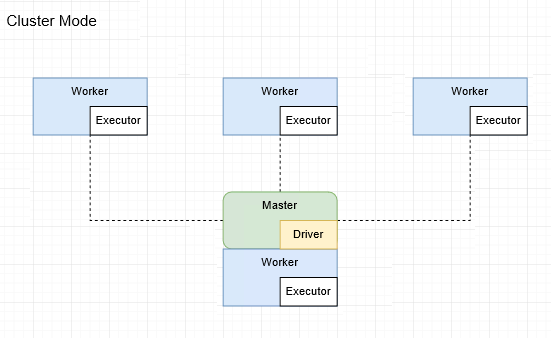
由此,也带来一个区别
- cluster mode,适用于生产环境,因为便于横向扩展,当需要时,可以多起几个worker,然后快速提交计算需求,如果中途断开也不要紧。但是有一个坏处是看log不方便。
- client mode适用于开发环境,因为driver,executor一体,便于看log。不过需要注意的是提交了request不能中途断开,否则就无法得到计算结果。
至于YARN,MESOS,其实是把driver和executor包装起来放在一个框架中,自身扮演了master的角色,负责居中调度。
下面是各种deploy模式的参数介绍:
Spark Standalone

Mesos (Apache)

Yarn (Hadoop)

Spark Submit Job
Spark submit 在 Server 端的提交任务示例:
./bin/spark-submit
--class org.apache.spark.examples.SparkPi \ # 应用程序的主类
--master yarn \ # master 的地址,提交任务到哪里执行,如:spark://host:port, yarn, local
--deploy-mode cluster \ # 在本地 (client) 启动 driver 或在 cluster 上启动,默认是 client
--driver-memory 4g \ # Driver内存,默认 1G
--executor-memory 2g \ # 每个 executor 的内存,默认是1G
--executor-cores 1 \ # Executor的cpu core的数量
--queue my_queue \ # 运行在YARN的哪个队列上
--num-executors 3 \ # Executor的数量
examples/jars/spark-examples*.jar \ # 需要依赖的包
10

 浙公网安备 33010602011771号
浙公网安备 33010602011771号