
【架构思考】分布式模块与中心化缓存的使用演进
随着需求不断增加,业务量不断增大,应用/系统/框架也需要不断升级,迭代。
今天就讲一讲我们系统中非常重要的一环,缓存的演进。
原初
整个系统的简化模型如下:源文件Source把输入传给应用模块Module,进行处理,Module会和缓存Cache进行一些数据交互,最后输出到Store进行存储。
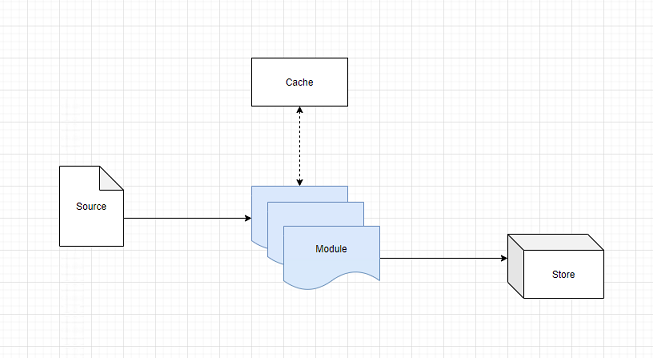
其中,应用模块Module和缓存模块Cache交互如下:一个典型的例子是,三个module同时处理同一天的数据。发送get请求给Cache。
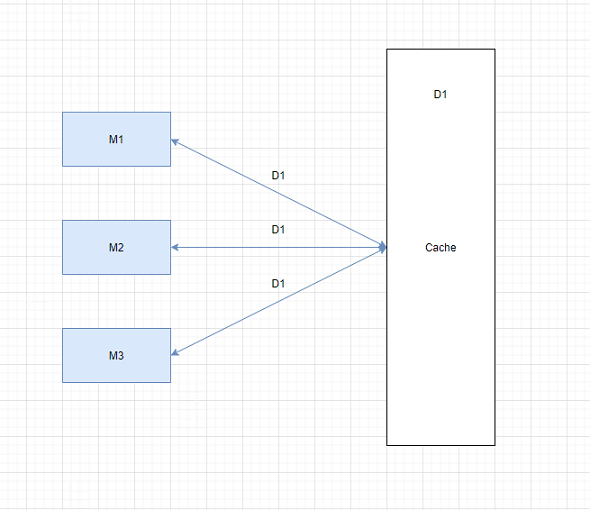
(注:Cache端处理请求,单线程,多线程都可以,这里是设置成单线程的。)
问题1
情景:在Cache开始工作前,有一个启动阶段。module会发送消息给Cache,要求 load 某一天的数据,这样后面处理的时候,就可以直接使用了。
流程可以总结为4步:
M1把 DATE 置为 refreshingM1发送消息给Cache,要求刷某一天的数据Cache完成之后,发送消息给M1,告诉它完成了M1把 DATE 置为 done
(注:这个 DATE 是一个记录标志位 flag 的 Region ,在 client side 和 server side 都进行了配置,由 Cache 负责同步。)
如下图:
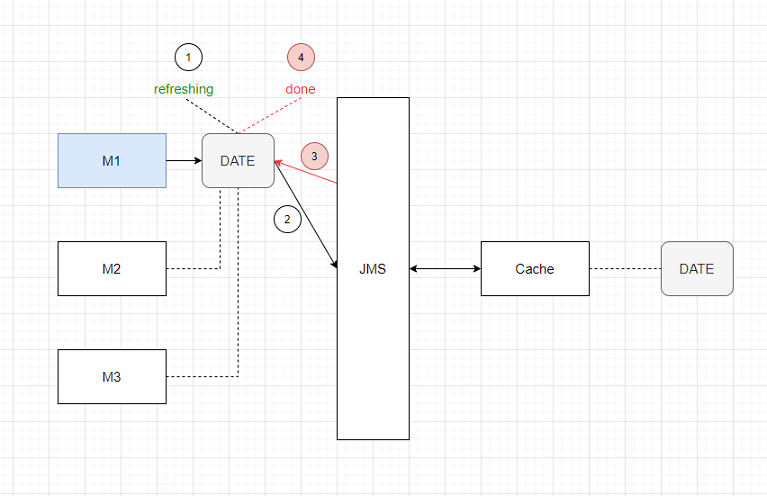
这里,有一个问题:如果 第3步 失败了,那么 第4步 也就无法完成。整个系统就会一直卡住不动,直到消息超时,M1会挂掉,但是M2,M3还是傻傻地等在那儿。
即,集群中一个模块的 failure 扩散到了整个集群,导致整个不工作。
解决1
为了解决这个问题,我们把流程改进一下,把标志位 DATE 的控制放到了 Cache Server 端。
M1发送消息给Cache,要求刷某一天的数据Cache把 DATE 置为 refreshingCache完成之后,把 DATE 置为 doneCache发送消息给M1,告诉它完成了
如下图:
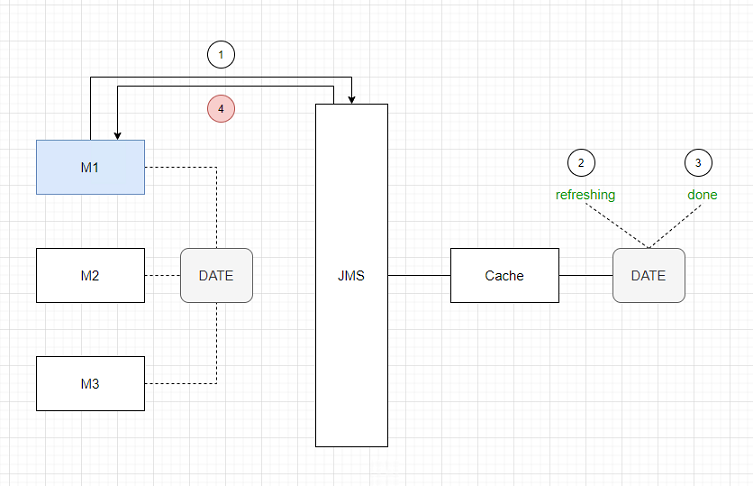
这样,即使第4步失败了,没有关系,M1会挂掉,但是M2,M3会继续运行下去。
即,集群中一个模块的 failure 得以 contain 在该模块内部,而不会扩散到整个集群。
新的需求与问题2
随着系统的发展,我们有了新的需求,即处理多天的数据。如下图:
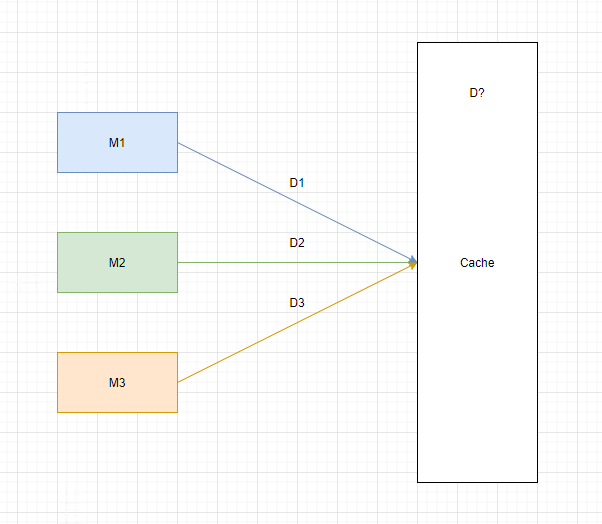
三个module分别处理不同日期的数据。但是,Cache中只能存一天的数据。(考虑到机器的内存,多天的可能放不下。)
这里就存在一个竞争的问题。如果不做特殊处理,会导致Cache频繁 switch context ,造成资源浪费,甚至数据错误。
解决2.1
这其实是一个典型的类似 race condition 的问题。一个解决方案是:三个人竞争上岗,谁抢到锁谁用。
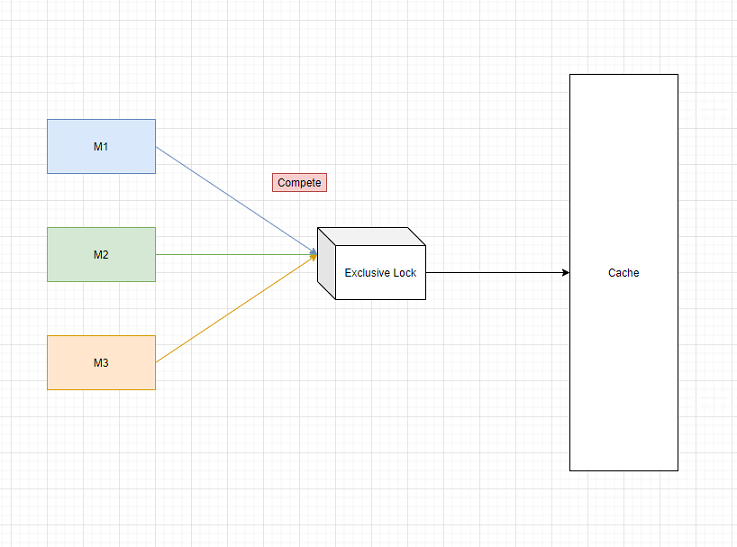
(这里的难点在于,不同 server 上的 不同 moudle 竞争一个同一个资源,如何选择和配置这个中心化的资源。)
具体实现起来,一种方案是,使用DB的表实现独占锁,把这个表的隔离级别设置成 REPEATABLE_READ 或者 SERIALIZABLE 。
解决2.2
上面的方案当然可行,还有没有其它的方案呢?
分析下来,整个系统的瓶颈在于Cache,因为Cache中只能 load 一天的数据,所以,即使三个module分别处理不同日期的数据,但其实并不能做到并行,实际还是串行的。
所以,另一种方案是,使用 单线程Queue + 锁。如下图:
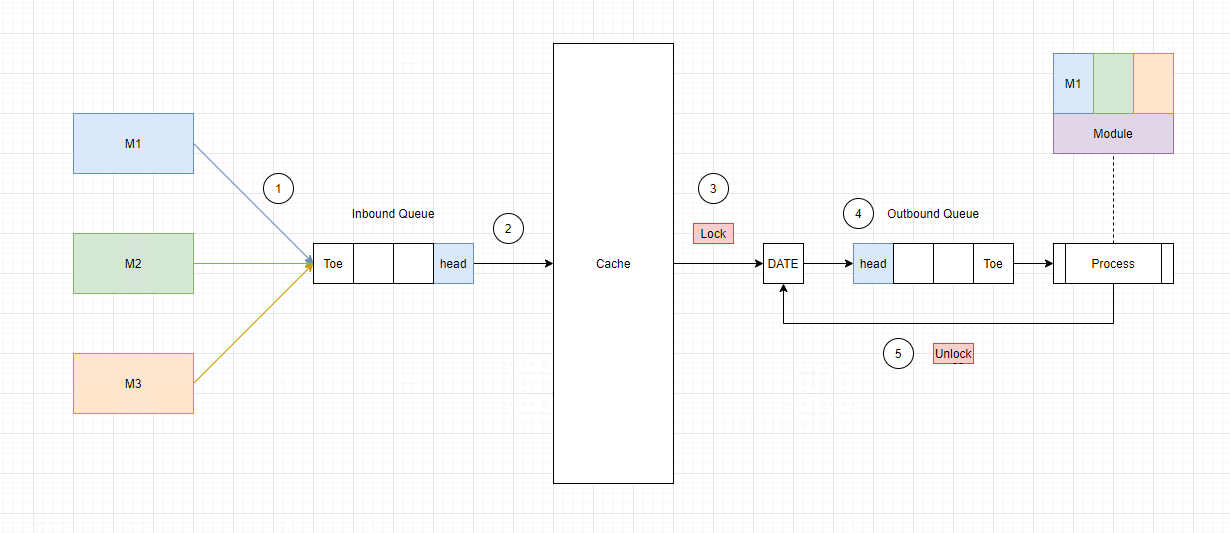
M1,M2,M3发送消息到 Inbound Queue 中Cache按照顺序,依次处理- 当处理某一天的时候,
Cache会 lock 这一天的标志位 DATE - 然后
Cache把消息放到 Outbound Queue 中 M1收到消息,开始处理这一天的数据,当处理完成时 unlock
首先, Inbound Queue 和 Outbound Queue 形成了闭环,保证了运行不会发生错漏。其次,单线程解决了竞争问题。最后, Lock 操作可以放在 client 端,也可以放在 server 端,这里采用的是改动最小的设计。
解决3
上面的方案可行,但还是有瓶颈,这个瓶颈是由于现有的Cache架构难以满足日益变化的需求导致的。如果要进一步优化,可以重新架构如下:
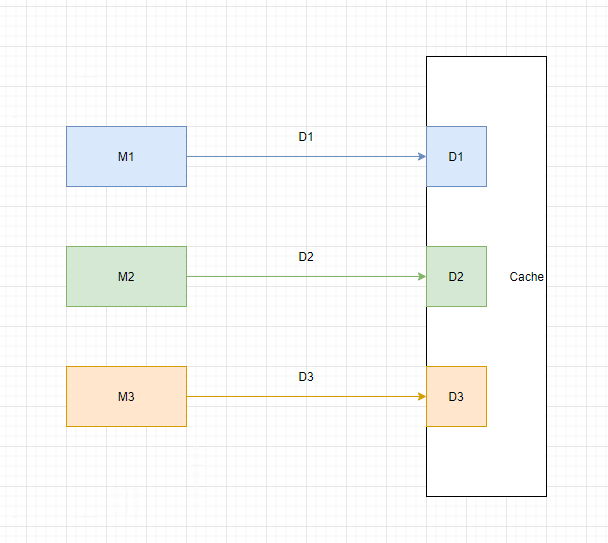
在Cache中 load 多天的数据,按需分配,随用随拿,做到真正的并行。但是这有两个前提条件:
- 物理层面,申请到更大内存的机器。
- 软件层面,对
Cache模块进行优化,减少不必要的内存占用。
总结
程序就像人一样,有一个慢慢成长的过程。一开始,为了快速立项,很多地方会采取捷径,反正怎么 work 怎么来。但是逐渐地,随着项目的扩大,参与的人越来越多,项目需要整合,重构,以适应新的变化和节奏。
能够静下心来,磨练技术,伴随着系统一起改进与成长是一件非常美好的事。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号