
【架构思考】巧用Java读写锁ReadWriteLock重构系统
问题
工作中遇到一个棘手的 BUG 。为方便理解,首先介绍下,涉及模块的流程简化如下:
Start -> Node -> Cache/DB -> Query_Engine
系统是按批次 Batch 处理数据,开始时,把一个批次的数据都发到某个 Node 上去,进行处理,完了之后存进 Cache/DB ,接着再加载到 Query_Engine 中。
这里使用的 Query_Engine 是 Dremio 。它是一个基于列式存储的 OLAP 系统,支持多种数据源(如 Oracle , Hadoop , S3 ,或者直接从文件读取,如 Parquet , JSON )。系统中用的是 Parquet 文件。
使用 Dremio 的好处是跑一些复杂的 query 会非常快,且可以结合一些可视化工具,如 Power BI , Tableau 生成报表直接面向用户。
考虑分布式的情况,两个 Batch 分别跑在两个 Node 上,最终写进 DB ,因为 Txn 是行级别的(为什么后面说),所以数据一条一条写入,有可能发生错位。
Node_1,写入一条数据,DB_KEY为1
Node_2,写入一条数据,DB_KEY为2
Node_1,写入一条数据,DB_KEY为3
Node_2,写入一条数据,DB_KEY为4
Batch_1 -> Node_1 -> DB: 1,3,5,7
Batch_2 -> Node_2 -> DB: 2,4,6,8
数据错位,本来也没什么问题,但是,当数据 flow 到 Query_Engine 的时候,为了防止反复 load ,会按照 DB_KEY 进行判断。
比如, Node_2 处理完了,触发 Query_Engine 加载数据。它会加载所有 DB_KEY<=8 的。
但是,这时,有可能 Node_1 的 DB_KEY=7 的这个块,并没有完成 Txn ,还不在数据库中,所以就没有被加载到 Query_Engine 中。
而当 Node_1 处理完了,触发 Dremio 加载数据时,由于它的最大 DB_KEY=7 ,系统认为已经加载过了,不会重复加载。
所以,最终的结果是, DB_KEY=7 的这条数据被漏掉了。
Txn
看到这个问题,第一反应,这个 Txn 为什么是行级别的?一条一条插入?如果是按照 Batch 级别做事务,不就能避免这个问题了吗?
经过分析发现
- 首先,一个 Batch 做成一整个事务,代价很大,回滚成本很高,因为 Batch 里面的数据量可能非常大。
- 其次,从设计和业务层面上讲,这里的数据有点特殊,在 Batch 层面做事务,需要考虑后续去重问题,因为 Node_1 和 Node_2 可能产生完全一样的一条数据,唯一差别就是 DB_KEY 不同。现在的设计,我们做的是事先去重,去重发生在两个层面,主要是缓存,然后在数据库中做最终一致性检查,如果有重复的, catch 住 Exception 进行额外处理。由于是一条一条 persist ,如果 Node_1 已经写入了(缓存或者数据库), Node_2就不会再 persist 了。
解决1 - 短期
从短期来看,我们需要快速解决问题,那么一个思路就是:改动 Query_Engine 端的逻辑,在数据表中新加一个属性 Node_Id ,用来标记这条数据是由哪个 Node 处理的。
然后在 load 到 Query_Engine 时,不是按照 DB_KEY 进行 load ,而是按照 Node_Id 来 load 。从而保证各个 Node 的数据完全被加载进去。
但是这样做的弊端是,新加了一个 business 不用的属性,增大了存储量。而且加载时由于数据不连续,也比较慢。
解决2 - 中期
从中期上看,这里的问题主要在于:写操作时,各个 Node 互相独立,没有影响。但是读操作时,特别是获取 MAX_DB_KEY 的时候,需要保证各个 Node 的写入已经完成。
我们可以引入 Java 中的 ReadWriteLock ,然后反向使用。
在 persist 的时候,加共享锁 readLock() ,各个 Node 可以随意写。
在 read MAX_DB_KEY 的时候,加独占锁 writeLock() ,需要其它 Node 都写完了才可以进行。
示例代码如下:
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class App {
private static final ReentrantReadWriteLock rwlock = new ReentrantReadWriteLock();
private static final Lock rlock = rwlock.readLock();
private static final Lock wlock = rwlock.writeLock();
private static int count = 0;
public static void main(String[] args) {
for (int i=1; i<=10; i++) {
Thread t1 = new Thread(new NodeWrite());
t1.setName("Node 1[" + i + "] Write");
Thread t2 = new Thread(new NodeWrite());
t2.setName("Node 2[" + i + "] Write");
t1.start();
t2.start();
}
Thread t3 = new Thread(new NodeRead());
t3.setName("*** Node 3 Read");
Thread t4 = new Thread(new NodeRead());
t4.setName("*** Node 4 Read");
t3.start();
t4.start();
}
static class NodeWrite implements Runnable {
public void run() {
while (rwlock.isWriteLocked()) {
System.out.println(Thread.currentThread().getName() + " waiting ... ");
}
rlock.lock();
try {
Long duration = (long) (Math.random() * 10000);
System.out.println(Thread.currentThread().getName() + " " + ++count + "; Time Taken " + (duration/1000) + " seconds.");
Thread.sleep(duration);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
rlock.unlock();
}
}
}
static class NodeRead implements Runnable {
public void run() {
wlock.lock();
try {
Long duration = (long) (Math.random() * 1000);
System.out.println(Thread.currentThread().getName() + " " + count + "; Time Taken " + (duration) + " mili seconds.");
Thread.sleep(duration);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
wlock.unlock();
}
}
}
}
结果如下:
Node 3 在 Read 时,保证所有 1-6 的数据都被 load 进去了。
Node 4 在 Read 时,保证所有 7-20 的数据都被 load 进去了。
Node 1[1] Write 1; Time Taken 1 seconds.
Node 2[2] Write 2; Time Taken 0 seconds.
Node 1[3] Write 3; Time Taken 4 seconds.
Node 2[3] Write 4; Time Taken 2 seconds.
Node 2[5] Write 5; Time Taken 8 seconds.
Node 1[6] Write 6; Time Taken 5 seconds.
*** Node 3 Read 6; Time Taken 585 mili seconds.
Node 2[8] Write 7; Time Taken 2 seconds.
Node 1[9] Write 8; Time Taken 0 seconds.
Node 2[9] Write 9; Time Taken 5 seconds.
Node 2[1] Write 10; Time Taken 7 seconds.
Node 1[2] Write 11; Time Taken 1 seconds.
Node 1[4] Write 12; Time Taken 0 seconds.
Node 2[4] Write 13; Time Taken 8 seconds.
Node 1[5] Write 14; Time Taken 2 seconds.
Node 1[7] Write 15; Time Taken 3 seconds.
Node 2[7] Write 16; Time Taken 8 seconds.
Node 1[8] Write 17; Time Taken 7 seconds.
Node 1[10] Write 18; Time Taken 2 seconds.
Node 2[10] Write 19; Time Taken 1 seconds.
Node 2[6] Write 20; Time Taken 6 seconds.
*** Node 4 Read 20; Time Taken 927 mili seconds.
解决3 - 长期
从长远来看,我们考虑把事先去重,变成事后去重。
基于现有的框架,系统的处理能力已经到了一个瓶颈。为了向大数据处理方向转型,需要一步步对系统进行优化。
其中一个变化就是把计算和IO分离。
现有的框架如下:
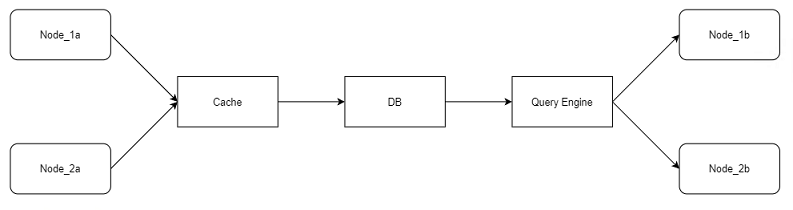
计算和IO是糅合在一起的。做一段计算a,做一段存储,然后再做一段计算b,循环往复。
新的框架如下:
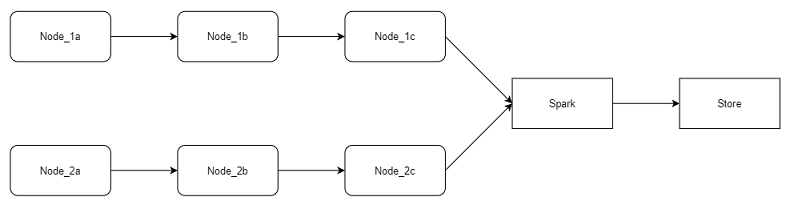
把计算a,b,c放在一起做,完了最后一起存储。
当然,针对这个问题,我们会在做完所有计算后,先利用 Spark 做一遍去重,然后再存储。
前者是一个基于模块化设计的应用,适用于中小量的数据处理,优点是层次分明。而后者,是一个典型的适用于大数据框架的应用。
总结
遇到问题分层次和阶段解决是非常有效的。这里的问题是按照 DB_KEY 读取数据时发生遗漏。
- 那么最简单的做法是换一个条件,不按照 DB_KEY 读取,而是使用 NODE_ID 读取。
- 经过分析,按照 DB_KEY 读取效率更高,那么我们可以采用 ReadWriteLock 保证数据完整性。
- 从长期看,我们可以考虑重构系统,使用最新的技术解决问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号