Hadoop异常解决:本地MapReduce程序无法和云端DataNode通信
问题
在本地写了一个Java程序,操作云端的HDFS文件系统,执行ls没有问题。
在本地写了另外一个Java程序,连接云端的HDFS做MapReduce操作,报错如下。
片段1:在开始做map 0% reduce 0%操作时,报了一个Connection refused。
2020-10-31 09:32:09,858 INFO [org.apache.hadoop.mapreduce.Job] - map 0% reduce 0%
2020-10-31 09:32:11,120 WARN [org.apache.hadoop.hdfs.BlockReaderFactory] - I/O error constructing remote block reader.
java.net.ConnectException: Connection refused: no further information
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:531)
at org.apache.hadoop.hdfs.DFSClient.newConnectedPeer(DFSClient.java:3444)
at org.apache.hadoop.hdfs.BlockReaderFactory.nextTcpPeer(BlockReaderFactory.java:777)
at org.apache.hadoop.hdfs.BlockReaderFactory.getRemoteBlockReaderFromTcp(BlockReaderFactory.java:694)
at org.apache.hadoop.hdfs.BlockReaderFactory.build(BlockReaderFactory.java:355)
at org.apache.hadoop.hdfs.DFSInputStream.blockSeekTo(DFSInputStream.java:635)
at org.apache.hadoop.hdfs.DFSInputStream.readWithStrategy(DFSInputStream.java:844)
at org.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:896)
at java.io.DataInputStream.read(DataInputStream.java:100)
at org.apache.hadoop.util.LineReader.fillBuffer(LineReader.java:180)
at org.apache.hadoop.util.LineReader.readDefaultLine(LineReader.java:216)
at org.apache.hadoop.util.LineReader.readLine(LineReader.java:174)
at org.apache.hadoop.mapreduce.lib.input.LineRecordReader.skipUtfByteOrderMark(LineRecordReader.java:143)
at org.apache.hadoop.mapreduce.lib.input.LineRecordReader.nextKeyValue(LineRecordReader.java:183)
at org.apache.hadoop.mapred.MapTask$NewTrackingRecordReader.nextKeyValue(MapTask.java:556)
at org.apache.hadoop.mapreduce.task.MapContextImpl.nextKeyValue(MapContextImpl.java:80)
at org.apache.hadoop.mapreduce.lib.map.WrappedMapper$Context.nextKeyValue(WrappedMapper.java:91)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:145)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:787)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:243)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
片段2:Failed to connect to /127.0.0.1:50010 for block,无法连接到127.0.0.1:50010这个地址的服务。
2020-10-31 09:32:11,123 WARN [org.apache.hadoop.hdfs.DFSClient] - Failed to connect to /127.0.0.1:50010 for block,
add to deadNodes and continue. java.net.ConnectException: Connection refused: no further information
java.net.ConnectException: Connection refused: no further information
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:531)
at org.apache.hadoop.hdfs.DFSClient.newConnectedPeer(DFSClient.java:3444)
at org.apache.hadoop.hdfs.BlockReaderFactory.nextTcpPeer(BlockReaderFactory.java:777)
at org.apache.hadoop.hdfs.BlockReaderFactory.getRemoteBlockReaderFromTcp(BlockReaderFactory.java:694)
at org.apache.hadoop.hdfs.BlockReaderFactory.build(BlockReaderFactory.java:355)
at org.apache.hadoop.hdfs.DFSInputStream.blockSeekTo(DFSInputStream.java:635)
at org.apache.hadoop.hdfs.DFSInputStream.readWithStrategy(DFSInputStream.java:844)
at org.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:896)
at java.io.DataInputStream.read(DataInputStream.java:100)
at org.apache.hadoop.util.LineReader.fillBuffer(LineReader.java:180)
at org.apache.hadoop.util.LineReader.readDefaultLine(LineReader.java:216)
at org.apache.hadoop.util.LineReader.readLine(LineReader.java:174)
at org.apache.hadoop.mapreduce.lib.input.LineRecordReader.skipUtfByteOrderMark(LineRecordReader.java:143)
at org.apache.hadoop.mapreduce.lib.input.LineRecordReader.nextKeyValue(LineRecordReader.java:183)
at org.apache.hadoop.mapred.MapTask$NewTrackingRecordReader.nextKeyValue(MapTask.java:556)
at org.apache.hadoop.mapreduce.task.MapContextImpl.nextKeyValue(MapContextImpl.java:80)
at org.apache.hadoop.mapreduce.lib.map.WrappedMapper$Context.nextKeyValue(WrappedMapper.java:91)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:145)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:787)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:243)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
127.0.0.1是localhost的IP,50010这个端口是啥呢?我去云端看一下,使用netstat命令发现这个端口跑的是DataNode的进程。
初步分析
首先,我们来回顾一下Map Reduce流程。看下面的图:
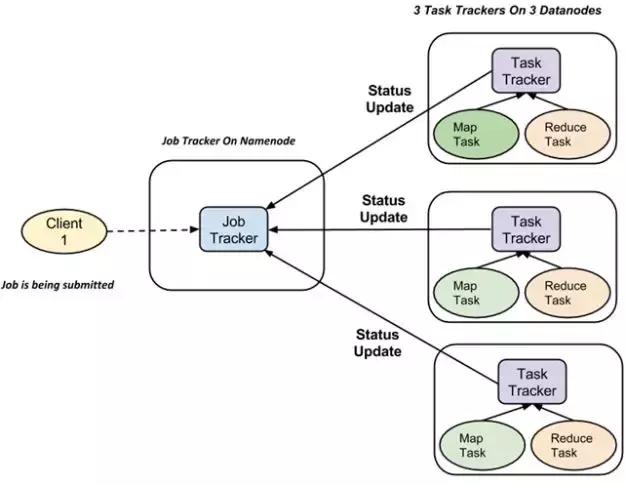
Client(本地的Java程序)提交一个任务(MapReduce操作)到Job Tracker,然后由Job Tracker和DataNode交互,不断更新自己的作业状态,最后把结果存到HDFS上。
这里的Job Tracker是啥呢?(在Hadoop生态圈,任务调度的角色应该是Yarn)笔者认为在这里应该是本地起的"Dummy"的Job Tracker。(因为我本地和云端都没起Yarn)
回去查log如下:
2020-10-31 09:32:08,672 INFO [org.apache.hadoop.mapreduce.lib.input.FileInputFormat] - Total input paths to process : 1
2020-10-31 09:32:08,694 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - number of splits:1
2020-10-31 09:32:08,747 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - Submitting tokens for job: job_local1490971204_0001
2020-10-31 09:32:08,850 INFO [org.apache.hadoop.mapreduce.Job] - The url to track the job: http://localhost:8080/
2020-10-31 09:32:08,851 INFO [org.apache.hadoop.mapreduce.Job] - Running job: job_local1490971204_0001
可以看到,在本地,Java程序已经做好了Split,然后把Job提交在了local的Job Tracker上。访问一下URLhttp://localhost:8080/,发现打不开。(这个端口应该是要起Yarn才有用的)
结合以上,我们可以得出初步结论:Java程序可以和NameNode通信,但是无法和DataNode建立连接。因为DataNode返回的是127.0.0.1:50010。
我们要做的修改是,让DataNode返回正确的Hostname,而不是IP。这样,本地的Java程序才能解析。
强制使用Hostname
首先,在Java程序中,加入如下语句:
configuration.set("dfs.client.use.datanode.hostname", "true");
其次,在HDFS端,修改$HADOOP_HOME/etc/hadoop/hdfs-site.xml,加入如下语句:
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
<description>Whether clients should use datanode hostnames when
connecting to datanodes.
</description>
</property>
意思是,让客户端总是使用DataNode的Hostname进行连接。(保险起见,两处都要改,有的时候只改一处发现还是不行)
重启一遍试试,发现还是报错。
但是不急,看看Console log,发现其实是有效果的。Clients端想要PING的变成了localhost,原先是127.0.0.1。
2020-10-31 10:06:28,077 WARN [org.apache.hadoop.hdfs.DFSClient] - Failed to connect to localhost/127.0.0.1:50010 for block,
add to deadNodes and continue. java.net.ConnectException: Connection refused: no further information
java.net.ConnectException: Connection refused: no further information
这里的问题是,DataNode(错误地)挂在了localhost上。
修改Hostname
首先,我们去服务器看一下,到底Hostname是啥?打开DataNode的log,发现有如下语句:
2020-10-31 09:31:43,492 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Configured hostname is localhost
确确实实是localhost!
然后,我回去看一下$HADOOP_HOME/etc/hadoop/slaves的配置,里面配的是hadoop001。
再去看一下/etc/hosts的内容,发现是这么配的:
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.19.183.99 maxc maxc
127.0.0.1 maxc maxc
127.0.0.1 localhost localhost
0.0.0.0 hadoop000 hadoop000
0.0.0.0 hadoop001 hadoop001
使用hostname命令,找到Linux服务器的真实Hostname是maxc。
所以,机器的真实Hostname是maxc,而我们又创建了两个虚拟的Hostname,hadoop000和hadoop001,用来起Hadoop。
猜想:Hadoop通过hadoop001的IP地址0.0.0.0,想要找到机器的真实Hostname,但是,由于配得有点问题,最终找到了localhost。
这里,我们有两种改法:
- 修改Linxus系统的Hostname mapping,使得Hadoop能根据默认的DNS寻址找到hadoop001
- 直接指定DataNode的Hostname为hadoop001
方案一
(临时)修改hosts如下,但是Reboot服务器会覆盖hosts内容,改动失效。
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.19.183.99 hadoop001 hadoop001
172.19.183.99 hadoop000 hadoop000
172.19.183.99 maxc maxc
127.0.0.1 localhost localhost
方案二
查看DataNode的源码,我们发现,Hadoop是用getHostName方法去查找Hostname的:
private static String getHostName(Configuration config)
throws UnknownHostException {
String name = config.get(DFS_DATANODE_HOST_NAME_KEY);
if (name == null) {
name = DNS.getDefaultHost(
config.get(DFS_DATANODE_DNS_INTERFACE_KEY,
DFS_DATANODE_DNS_INTERFACE_DEFAULT),
config.get(DFS_DATANODE_DNS_NAMESERVER_KEY,
DFS_DATANODE_DNS_NAMESERVER_DEFAULT));
}
return name;
}
进而定位到DFS_DATANODE_HOST_NAME_KEY这个静态常量:
public static final String DFS_DATANODE_HOST_NAME_KEY = "dfs.datanode.hostname";
而且代码中加了注释说://Following keys have no defaults,所以我一开始查文档的时候死活没找到哪里可以设置Hostname的地方。(恍然大悟状~)
-> https://hadoop.apache.org/docs/r2.7.1/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
所以,我们可以在$HADOOP_HOME/etc/hdfs-site.xml加入如下片段:
<property>
<name>dfs.datanode.hostname</name>
<value>hadoop001</value>
</property>
重启再试,成功!
总结
- 首先,根据Console log,发现DataNode返回的是IP;
- 于是,我们强制Client-DataNode交互使用Hostname;
- 其次,根据DataNode log,发现使用的Hostname不对;
- 于是,我们查看源码,找到修改Hostname的地方。
经验教训:遇到问题不要怕,冷静分析。搜索看3-5篇post没有解决问题的话,直接根据log查源码,快速定位问题。
参考
- Hadoop Map/Reduce执行流程详解 https://www.jianshu.com/p/352db00b6d7a
- Hadoop配置文件参数详解 https://blog.csdn.net/starskyboy/article/details/80879697
- 外网无法访问云主机HDFS文件系统 https://my.oschina.net/gordonnemo/blog/3017724

 浙公网安备 33010602011771号
浙公网安备 33010602011771号