【从零单排】大白话讲索引 - Index
为什么要索引
查询数据库,当数据量很大时,往往很慢,为了加快查询速度,程序员们想了一个办法,就是建立索引。但是天下没有免费的午餐,当插入新的数据时,系统会自动更新索引,所以在空间(storage)和时间(update time)上有一定地额外的开销。
总结:为什么要索引?是为了查的更快。
索引的原理
索引是建立在表的一列或多个列上的辅助对象,目的是加快访问表中的数据
那么,索引是怎么加速查询的呢?
举例,我们想要查询到分数大于80分的学生的信息。
select * from student where score > 80;
数据库就会去student这个表一条一条地找,看满不满足条件(即全表搜索)。这不就是穷举法吗?显然是挺笨重的。如果我们能对score排个序,不就可以用二分法查了吗?索引干的其实就是这个活。
create index score_index on student(score);

创建索引时,我们把每一条数据的Score和DB_Loaction(RowID)抽取出来,放在某个数据结构中(比如B树)。
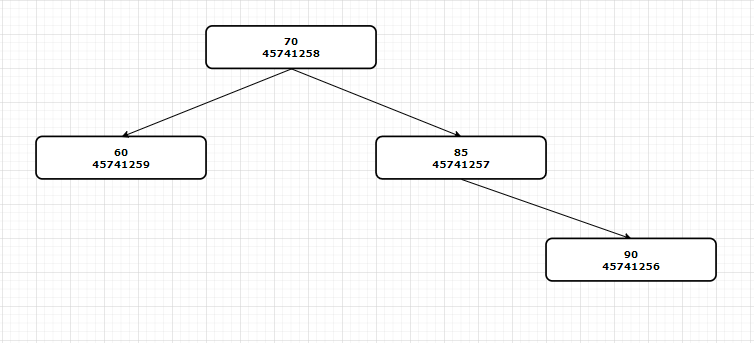
当查询score > 80时,我们就去B树中查,时间复杂度为LOG(N)。找到之后,再根据DB_Loaction直接定位到该条记录返回结果。
索引的类型 - 基础
当我们谈论到索引类型时,会碰到各种各样的概念,很容易混淆。下面我就分为基础和进阶两种,一一解读。
唯一索引
唯一索引即unique index,即创建索引的列里面没有重复的值(但可以是null)。
create unique index some_index on some_table(some_column)
注:Oracle自动在表的主键列上创建唯一索引。
单一索引与组合索引
单一索引:即只对于某一列(column)建立索引
create index some_index on some_table(some_column)
组合索引:即对于多列(column)建立索引
create index some_index on some_table(column_1,column_2)
适用场景:单一索引与组合索引是一组相关联的概念。在建立索引时,首先要考虑查询语句是什么样的,如果只有某一个判断条件经常出现(比如date=20200501),就用单一索引。如果某几个判断条件经常一起出现(比如age>20 and sex='male'),那么就用组合索引。
注:对于组合索引,and是有效的;or是无效的,还是会全表搜索。
索引的类型 - 进阶
B树索引
B树是Oracle默认的索引类型。想要理解索引,一定要理解B树(具体地说,是平衡多路查找树 Balanced B Tree)是怎么构成的。
这里贴个链接,讲得很详细:从B树、B+树、B*树谈到R 树。
反向键索引
反向键索引反转列键值的每个字节。从而实现索引的均匀分配,避免B树不平衡。创建索引时使用reverse关键字。
create index some_index on some_table (some_column) reverse
举例:
ID:001,002,003,004
反转:100,200,300,400
适用场景:通常适用于连续增长的值。
位图索引
位图索引即bitmap index,下面举例解释。
比如我们想要在type这个列上建立位图索引。type这个列一共会有三个值:small,medium,large。对于每一个值(比如small),建立一个数据结构(比如bitmap_small),存的是ROWID+Flag。Flag的取值为1或0,具体的计算:是根据该ROWID对应的行的type是否为相应值(比如small)。
在该例中,一共会建立三个位图:
bitmap_smallbitmap_mediumbitmap_large
那么,当需要寻找type='small'的数据时,直接去bitmap_small这个数据结构中找为1的值对应的ROWID,几乎可以直接命中。
创建索引时使用bitmap关键字。
create bitmap index some_index on some_table(some_column)
适用场景:适用于条目多,取值类别少,不经常更新的列。
基于函数的索引
即基于一列上的函数创建的索引
create index some_index on table(some_function(some_column))
举例
select * from student where upper(name)='Alice'
注:函数索引中可以使用'len','trim','substr','upper'(每行返回独立结果),不能使用如'sum','max','min','avg'等聚合函数。
索引的分区
对于表,有分区(Partition),对于索引,也有分区。分区的原因很简单,把一个大的索引切分成很多小的片段,可以访问地更快。
一般来说,可以分为local和global两大类。语法如下:
create index some_index on some_table(some_column) local
create index some_index on some_table(some_column) global
Local - All index entries in a single partition will correspond to a single table partition (equipartitioned).
Global - Index in a single partition may correspond to multiple table partitions.
具体的细节看这篇:Partitioned Tables And Indexes
索引失效的情况
1.使用不等于操作符:not,<>,!=
2.使用null进行判断
3.使用函数
4.比较不匹配的数据类型
怎么建立索引
比如,有一个表叫members,定义如下:
create table members(
member_id int generated by default as identity,
first_name varchar2(100) not null,
last_name varchar2(100) not null,
gender char(1) not null,
dob date not null,
email varchar2(255) not null,
primary key(member_id)
);
创建时,系统自动会在主键member_id上建立一个index。下面,我们再在last_name这个column上建立一个index:
create index members_last_name_i on members(last_name);
查询建立好的index:
select
index_name,
index_type,
visibility,
status
from
all_indexes
where
table_name = 'MEMBERS';
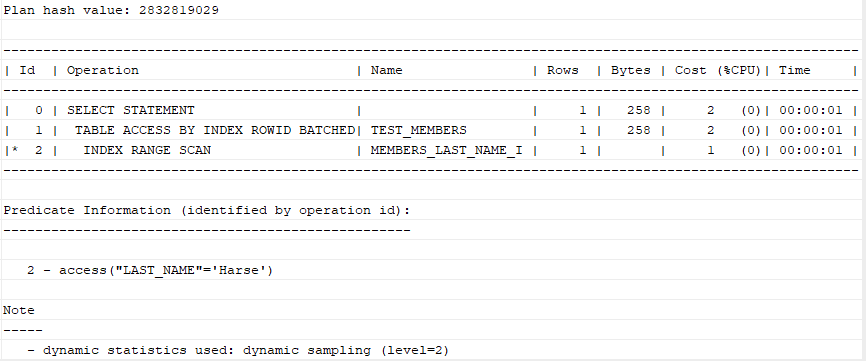
查看query效率:
explain plan for
select * from test_members
where last_name = 'Harse';
select
plan_table_output
from
table(dbms_xplan.display());
结果如下:
参考了这篇文章Oracle Create Index

 浙公网安备 33010602011771号
浙公网安备 33010602011771号