极客兔兔七天系列学习笔记--GeeCache
首先我们来归结分布式缓存的主要组成:
- 分布式,每个结点自身能提供缓存服务,也能向其他节点请求服务。
- 缓存,缓存的策略众多,GeeCache采用的是LRU策略。
缓存
LRU
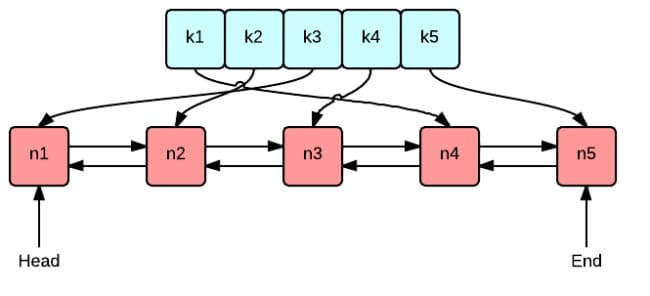
核心是两个数据结构,字典和双向链表。其中,字典存储键和值的映射关系,查找对应值的复杂度为O(1)。然后具体存储值的是双向链表,onEvicted是记录被移除时的回调函数。
type Cache struct {
maxBytes int64
nbytes int64
ll *list.List
cache map[string]*list.Element
onEvicted func(key string, val Value)
}
type Value interface {
Len() int
}
// 在自动剔除节点时,我们需要key去删除map中的元素
type entry struct {
key string
value Value
}
我们观察到,Value是一个接口,这样就可以实现任意类型值的存储。
并发控制
我们对cache再封装一层,产生cache接口体,实现可并发读写和字节存取。
点击查看代码
type cache struct {
mu sync.Mutex
lru *lru.Cache
cahceBytes int64
}
type Group struct {
mainCache *cache
name string
getter Getter
peers PeerPicker
loader singleflight.Group
}
var (
mu sync.RWMutex
groups = make(map[string]Group)
)
如果我们简单搭建一个服务端,通过获取url中的key值向Group调用Get方法,流程如下:
1. 查看有无缓存。
2. 若无缓存则查询key对应值在哪一节点。
3. 若在本地节点直接通过Getter调用本地服务获取,并将对应键值加入缓存。
4. 否则发起Get请求获取值。
<details>
<summary>点击查看代码</summary>
func (g *Group) Get(key string) (value ByteView, err error) {
if key == "" {
return ByteView{}, errors.New("key is required")
}
if value, ok := g.mainCache.get(key); ok {
return value, nil
}
return g.load(key)
}
func (g *Group) load(key string) (value ByteView, err error) {
viewi, err := g.loader.Do(key, func() (interface{}, error) {
if g.peers != nil {
if peer, ok := g.peers.PickPeer(key); ok {
if value, err := g.getFromPeer(peer, key); err == nil {
return value, nil
}
log.Println("[GeeCache] failed to get from peer")
}
}
return g.getLocally(key)
})
if err == nil {
return viewi.(ByteView), nil
}
return
}
func (g *Group) getLocally(key string) (value ByteView, err error) {
bytes, err := g.getter.Get(key)
if err != nil {
return ByteView{}, err
}
value = ByteView{b: cloneBytes(bytes)}
g.populateCache(key, value)
return
}
</details>
那么就有一个关键点,如何管理这些节点,并将key映射到某一节点,并且要求节点崩溃时造成的损失最小?
#### 一致性哈希
思路很简单,我们将数组变成有序环状,每一个真实节点都将产生众多虚拟节点,将他们的哈希值插入环中,保证数据不发生倾斜。这样,每个key对应的哈希值都位于环上某一区间,我们取第一个大于等于此哈希值的虚拟节点,通过map查找得到真实节点的位置。即使某一节点崩溃,也只是部分key的节点位置发生变动。
简单来说,**哈希环只是一个查找环**,同时记录节点位置。
```go
type Map struct {
replicas int
keys []int
// 哈希值到真实节点的映射
hashMap map[int]string
hash Hash
}
func (m *Map) Add(keys ...string) {
for _, key := range keys {
for i := 0; i < m.replicas; i++ {
hash := int(m.hash([]byte(strconv.Itoa(i) + key)))
m.keys = append(m.keys, hash)
m.hashMap[hash] = key
}
}
sort.Ints(m.keys)
}
func (m *Map) Get(key string) string {
if len(m.keys) == 0 {
return ""
}
hash := int(m.hash([]byte(key)))
idx := sort.Search(len(m.keys), func(i int) bool {
return m.keys[i] >= hash
})
return m.hashMap[m.keys[idx%len(m.keys)]]
}
HTTP服务
type HTTPPool struct {
self string
basePath string
mu sync.Mutex
peers *consistenthash.Map
httpGetters map[string]*HTTPGetter
}
HTTPPool要维护众多节点,同时充当服务端;HTTPGetter实际是对某一节点的Get请求的封装,实际上是客户端。他们分别实现了以下两个接口:
点击查看代码
type PeerPicker interface {
PickPeer(key string) (peer PeerGetter, ok bool)
}
// PeerGetter is the interface that must be implemented by a peer.
type PeerGetter interface {
Get(group string, key string) ([]byte, error)
}
func (h *HTTPPool) ServeHTTP(w http.ResponseWriter, r *http.Request) {
if !strings.HasPrefix(r.URL.Path, h.basePath) {
panic("HTTPPool serving unexpected path: " + r.URL.Path)
}
h.Log("%s %s", r.Method, r.URL.Path)
parts := strings.SplitN(r.URL.Path[len(h.basePath):], "/", 2)
if len(parts) != 2 {
http.Error(w, "bad request", http.StatusBadRequest)
}
groupName := parts[0]
key := parts[1]
group := GetGroup(groupName)
if group == nil {
http.Error(w, "no such group", http.StatusNotFound)
return
}
viewi, err := group.Get(key)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
w.Header().Set("Content-Type", "application/octet-stream")
w.Write(viewi.ByteSlice())
}
func (h *HTTPGetter) Get(group, key string) ([]byte, error) {
u := fmt.Sprintf("%v%v/%v", h.baseUrl, url.QueryEscape(group), url.QueryEscape(key))
resp, err := http.Get(u)
if err != nil {
return nil, err
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
return nil, errors.New(fmt.Sprintf("server returned %v", resp.Status))
}
bytes, err := ioutil.ReadAll(resp.Body)
if err != nil {
return nil, fmt.Errorf("reading response body: %v", err)
}
return bytes, nil
}
附:缓存击穿
缓存击穿:一个存在的key,在缓存过期的一刻,同时有大量的请求,这些请求都会击穿到 DB ,造成瞬时DB请求量大、压力骤增。
singleflight的思路如下:当同时有大量针对同一key的大量请求时,我们只允许一个请求访问DB,暂时拦截并保留其他请求。等到key值返回时,一并处理。
我们要记录请求,同时针对每个请求,要暂时保存相关状态:
type call struct {
wg sync.WaitGroup
val interface{}
err error
}
type Group struct {
mu sync.Mutex // protects m
m map[string]*call
}
func (g *Group) Do(key string, fn func() (interface{}, error)) (interface{}, error) {
g.mu.Lock()
if g.dict == nil {
g.dict = make(map[string]*call)
}
// 剩下的 N-1个并发请求拦截在这里等待直接返回结果,防止穿透
if call, ok := g.dict[key]; ok {
g.mu.Unlock()
call.wg.Wait()
return call.val, call.err
}
call := &call{}
g.dict[key] = call
call.wg.Add(1)
g.mu.Unlock()
call.val, call.err = fn()
call.wg.Done()
g.mu.Lock()
defer g.mu.Unlock()
delete(g.dict, key)
return call.val, call.err
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号