

第三章:决策树
自说原理:决策数是用训练集训练出一棵树,树怎么分叉是由属性(特征决定),测试集的属性按照这个树一直走下去,自然就分类了。一般树的深度越小越好,那如何选属性作为根节点,又选择哪一个属性作为第二个分叉点尼?
这就用到了信息熵与信息增益的知识。ID3中选择信息增益大的,C4.5中选择增益率大的。以书中的数据集为例:
| 属性1 no surfacing | 属性2 flippers | 标签 | |
| 1. | 1 | 1 | Y |
| 2. | 1 | 1 | Y |
| 3. | 1 | 0 | N |
| 4. | 0 | 1 | N |
| 5. | 0 | 1 | N |
决策数的算法有很多,ID3,C4.5,CART等等,按照ID3的步骤如下:
1)算数据集的香农熵(也就是信息熵)。![]() ,这里其实计算只与标签这一列有关系,此处因为只有两类,所以n=2。H=-0.4log20.4-0.6log20.6=0.97(这个算下来相当于就是不用任何属性瞎猜的不确定度,越大越不好。)
,这里其实计算只与标签这一列有关系,此处因为只有两类,所以n=2。H=-0.4log20.4-0.6log20.6=0.97(这个算下来相当于就是不用任何属性瞎猜的不确定度,越大越不好。)
2)这里有两个属性,先按照哪个属性划分尼?这得算各自属性的信息增益。选择信息增益大的。比如算属性1的信息增益,得按照属性1的值先将数据集划分,属性1有两个取值{1,0}。属性11中有{【1,Y】,【1,Y】,【0,N】}。属性10中有{【1,N】,【1,N】}。
然后计算属性1的信息增益,属性11返回的子数据集,算信息熵是Ent1=-2/3log22/3-1/3log21/3;属性10返回的子数据集,算信息熵是Ent2=-1log21;G=0.97-(3/5*Ent1+2/5*Ent2)
故这里程序中分为两步:1)求属性划分的子数据集
2)算信息增益选择最好的数据集划分方式
3)不断的递归,直到属性用完,或者每一个分支下都变成纯的数据。如果用完所有的属性,还不纯,该叶子节点得少数服从多数。
4)将1)~3)构建的树进一步操作变成分类器,即输入无标签的测试集,可以进行预测。
对于这些步骤,分别对应的代码(子函数)如下,首先为了调试方便,自营一个数据集:
1 def createDataSet(): 2 dataSet = [[1, 1, 'yes'], 3 [1, 1, 'yes'], 4 [1, 0, 'no'], 5 [0, 1, 'no'], 6 [0, 1, 'no']] 7 labels = ['no surfacing', 'flippers'] 8 return dataSet, labels
步骤1:
from math import log
1 def calcShannonEnt(dataSet): 2 ''' 3 算数据集的信息熵(也就是根据结果的类别占比,算不确定度) 4 :param dataSet:训练数据集(带标签) 5 :return:信息熵值H 6 ''' 7 # 求list的长度,表示计算参与训练的数据量 8 numEntries = len(dataSet) 9 # 计算分类标签label出现的次数 10 labelCounts = {} 11 for featVec in dataSet: 12 # 将当前实例的标签存储,即每一行数据的最后一个数据代表的是标签 13 currentLabel = featVec[-1] 14 # 为所有可能的分类创建字典,如果当前的键值不存在,则扩展字典并将当前键值加入字典。每个键值都记录了当前类别出现的次数。 15 if currentLabel not in labelCounts.keys(): 16 labelCounts[currentLabel] = 0 17 labelCounts[currentLabel] += 1 18 19 # 对于 label 标签的占比,求出 label 标签的香农熵 20 shannonEnt = 0.0 21 for key in labelCounts: 22 # 使用所有类标签的发生频率计算类别出现的概率。 23 prob = float(labelCounts[key])/numEntries 24 # 计算香农熵,以 2 为底求对数 25 shannonEnt -= prob * log(prob, 2) 26 return shannonEnt
步骤2)中的1):
1 def splitDataSet(dataSet, index, value): 2 ''' 3 求属性划分后的子数据集 4 :param dataSet: 数据集(带标签) 5 :param index: 列数(从0开始),比如按照第一个属性划分,那这个index=0 6 :param value:该属性(作为划分标准的属性)下的某一个值 7 :return: 8 ''' 9 # -----------切分数据集的第一种方式 start------------------------------------ 10 retDataSet = [] 11 for featVec in dataSet: 12 # index列为value的数据集【该数据集需要排除index列】 13 # 判断index列的值是否为value 14 if featVec[index] == value: 15 # chop out index used for splitting 16 # [:index]表示前index行,即若 index 为2,就是取 featVec 的前 index 行 17 reducedFeatVec = featVec[:index] 18 ''' 19 请百度查询一下: extend和append的区别 20 list.append(object) 向列表中添加一个对象object 21 list.extend(sequence) 把一个序列seq的内容添加到列表中 22 1、使用append的时候,是将new_media看作一个对象,整体打包添加到music_media对象中。 23 2、使用extend的时候,是将new_media看作一个序列,将这个序列和music_media序列合并,并放在其后面。 24 result = [] 25 result.extend([1,2,3]) 26 print result 27 result.append([4,5,6]) 28 print result 29 result.extend([7,8,9]) 30 print result 31 结果: 32 [1, 2, 3] 33 [1, 2, 3, [4, 5, 6]] 34 [1, 2, 3, [4, 5, 6], 7, 8, 9] 35 ''' 36 reducedFeatVec.extend(featVec[index+1:]) 37 # [index+1:]表示从跳过 index 的 index+1行,取接下来的数据 38 # 收集结果值 index列为value的行【该行需要排除index列】 39 retDataSet.append(reducedFeatVec) 40 # -----------切分数据集的第一种方式 end------------------------------------ 41 42 # # -----------切分数据集的第二种方式 start------------------------------------ 43 # retDataSet = [data for data in dataSet for i, v in enumerate(data) if i == axis and v == value] 44 # # -----------切分数据集的第二种方式 end------------------------------------ 45 return retDataSet
比如这里的测试的数据集传入,index=0,value=1,得到的结果是: [[1, 'y'], [1, 'y'], [0, 'n']]
步骤2)中的2):
1 def chooseBestFeatureToSplit(dataSet): 2 """chooseBestFeatureToSplit(选择最好的特征) 3 Args: 4 dataSet 数据集 5 Returns: 6 bestFeature 最优的特征列的序号(int) 7 """ 8 # 求有多少个属性 9 numFeatures = len(dataSet[0]) - 1 10 # label的信息熵 11 baseEntropy = calcShannonEnt(dataSet) 12 # 初始化最优的信息增益值(越大越好), 和最优的Featurn编号 13 bestInfoGain, bestFeature = 0.0, -1 14 # iterate over all the features 15 for i in range(numFeatures): 16 # 获取第i个属性下的所有值 17 featList = [example[i] for example in dataSet] 18 # 获取剔重后的集合,使用set对list数据进行去重 19 uniqueVals = set(featList) 20 # 创建一个临时的信息熵 21 newEntropy = 0.0 22 # 遍历某一列的value集合,计算该列的信息熵 23 # 遍历当前特征中的所有唯一属性值,对每个唯一属性值划分一次数据集,计算数据集的新熵值,并对所有唯一特征值得到的熵求和。 24 for value in uniqueVals: 25 subDataSet = splitDataSet(dataSet, i, value) 26 prob = len(subDataSet)/float(len(dataSet)) 27 newEntropy += prob * calcShannonEnt(subDataSet) 28 # gain[信息增益]: 划分数据集前后的信息变化, 获取信息熵最大的值 29 # 信息增益是熵的减少或者是数据无序度的减少。最后,比较所有特征中的信息增益,返回最好特征划分的索引值。 30 infoGain = baseEntropy - newEntropy 31 print('属性',i,'的信息增益infoGain=', infoGain, ' 标签的信息熵=', baseEntropy,' Ent和=', newEntropy) 32 if (infoGain > bestInfoGain): 33 bestInfoGain = infoGain 34 bestFeature = i 35 return bestFeature
步骤3):
1 import operator 2 from math import log 3 4 def majorityCnt(classList): 5 """当属性用完,叶节点还是不纯时,得少数服从多数 6 Args: 7 classList label列的集合 8 Returns: 9 bestFeature 最优的特征列 10 """ 11 classCount = {} 12 for vote in classList: 13 if vote not in classCount.keys(): 14 classCount[vote] = 0 15 classCount[vote] += 1 16 # 倒叙排列classCount得到一个字典集合,然后取出第一个就是结果(yes/no),即出现次数最多的结果 17 sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True) 18 # print 'sortedClassCount:', sortedClassCount 19 return sortedClassCount[0][0] 20 21 def createTree(dataSet, labels): 22 ''' 23 训练生成一棵数,只不过不是树状,是字典一层一层的 24 :param dataSet:训练数据集 25 :param labels:按顺序存放属性名字的列表 26 :return:一棵用一层一层字典表示的数 27 ''' 28 classList = [example[-1] for example in dataSet] 29 # 如果数据集的最后一列(标签列)的第一个值出现的次数=整个集合的数量,也就说只有一个类别,就只直接返回结果就行 30 # 第一个停止条件:所有的类标签完全相同,则直接返回该类标签。 31 if classList.count(classList[0]) == len(classList): 32 return classList[0] 33 # 如果数据集只有1列,那么最初出现label次数最多的一类,作为结果 34 # 第二个停止条件:使用完了所有特征,仍然不能将数据集划分成仅包含唯一类别的分组。 35 if len(dataSet[0]) == 1: 36 return majorityCnt(classList) 37 38 # 选择最优的列,得到最优列对应的label含义 39 bestFeat = chooseBestFeatureToSplit(dataSet) 40 # 获取label的名称 41 bestFeatLabel = labels[bestFeat] 42 # 初始化myTree 43 myTree = {bestFeatLabel: {}} 44 # 注:labels列表是可变对象,在PYTHON函数中作为参数时传址引用,能够被全局修改 45 # 所以这行代码导致函数外的同名变量被删除了元素,造成例句无法执行,提示'no surfacing' is not in list 46 del(labels[bestFeat]) 47 # 取出最优列,然后它的branch做分类 48 featValues = [example[bestFeat] for example in dataSet] 49 uniqueVals = set(featValues) 50 for value in uniqueVals: 51 # 求出剩余的标签label 52 subLabels = labels[:] 53 # 遍历当前选择特征包含的所有属性值,在每个数据集划分上递归调用函数createTree() 54 myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels) 55 # print 'myTree', value, myTree 56 return myTree
测试:
data,lab = createDataSet()
mytree = createTree(data, lab)
print(mytree)
结果是:{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}这其实就是一棵树。
对于这个返回的结果不像实际的树状那么直观,而决策树的一大优点就是直观,书中3.2节中用matplotlib进行画数型图直观化。这里省略了。
步骤4):
def classify(inputTree, featLabels, testVec): """利用也训练出的树进行预测分类 Args: inputTree 决策树模型,也就是以有的树,这里是createTree函数返回的结果myTree featLabels Feature标签对应的名称列表 testVec 测试输入的数据 Returns: classLabel 分类的结果值,需要映射label才能知道名称 """ # 获取tree的根节点对于的key值 firstStr = list(inputTree.keys())[0] # 通过key得到根节点对应的value secondDict = inputTree[firstStr] # 判断根节点名称获取根节点在label中的先后顺序,这样就知道输入的testVec怎么开始对照树来做分类 featIndex = featLabels.index(firstStr) # 测试数据,找到根节点对应的label位置,也就知道从输入的数据的第几位来开始分类 key = testVec[featIndex] valueOfFeat = secondDict[key] # print('+++', firstStr, 'xxx', secondDict, '---', key, '>>>', valueOfFeat) # 判断分枝是否结束: 判断valueOfFeat是否是dict类型 if isinstance(valueOfFeat, dict): classLabel = classify(valueOfFeat, featLabels, testVec) else: classLabel = valueOfFeat return classLabel
注意步骤3)中的labels列表是可变对象,在PYTHON函数中作为参数时传址引用,能够被全局修改。在调试时注意。
data,lab = createDataSet()
mytree = createTree(data, lab)
x = classify(mytree,['no surfacing', 'flippers'],[1,1])
print(x)
结果是:yes
此处生出另一个问题就是,每次预测都要训练,是很费事的,所以想办法将训练好的树存储起来。
def storeTree(inputTree, filename): import pickle # -------------- 第一种方法 start -------------- fw = open(filename, 'wb') pickle.dump(inputTree, fw) fw.close() # -------------- 第一种方法 end -------------- # -------------- 第二种方法 start -------------- with open(filename, 'wb') as fw: pickle.dump(inputTree, fw) # -------------- 第二种方法 start -------------- def grabTree(filename): import pickle fr = open(filename,'rb') return pickle.load(fr)
>>trees.storeTree(myTree,'1.txt')
>>trees.grabTree('1.txt')
到此基本ID3搞定了。完整的可以看这里(Python3运行略有错误,在上面的代码我已经改正)。但是好像有缺少剪枝什么的。
以上是自写决策树模块,但是sklearn中也有决策数模块,具体使用方法看这里(别人的文章,哈哈)
这里我也简单用sklearn中的决策树模块预测了上一章中的花蕊数据集。
这之前与上一章基本一样,所以比较省略
 主要是这一张截图部分不同
主要是这一张截图部分不同
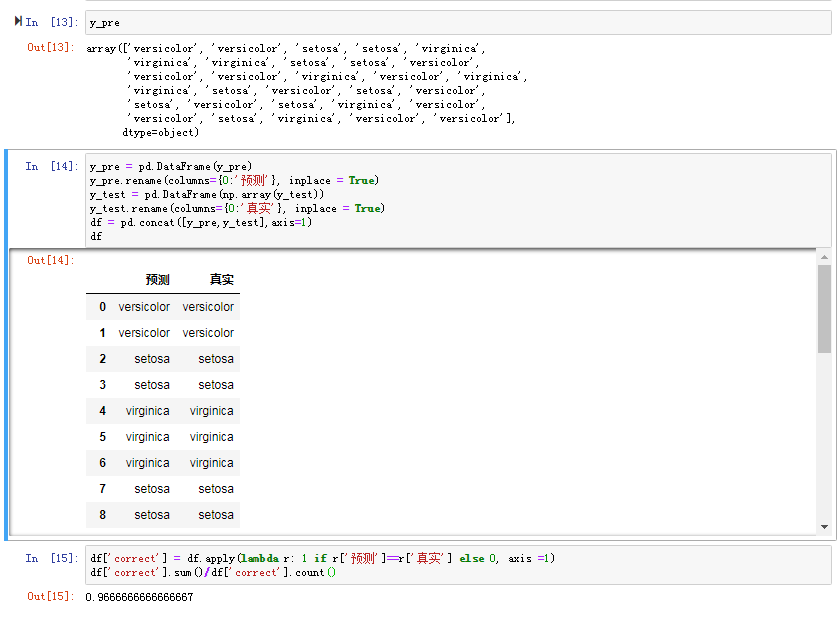
这里没有将数据归一化准确率就高达0.96666,上一章kNN没有归一化时准确率是0.9。这样看似乎是决策树好,但是用上一章的归一化方法处理后,决策树其它参数不变,其预测准确率又变成了0.9333333333333333

 浙公网安备 33010602011771号
浙公网安备 33010602011771号