【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 5 Octave Tutorial
Lecture 5 Octave教程
5.1 基本操作 Basic Operations
5.2 移动数据 Moving Data Around
5.3 计算数据 Computing on Data
5.4 绘制数据图 Plotting Data
5.5 控制语句: for, while, if 语句
5.6 向量化 Vectorization
5.1 基本操作
参考视频: 5 - 1 - Basic Operations (14 min).mkv
5.1.1 简单运算
不等于符号的写法是这个波浪线加上等于符号 ( ~= ),而不是等于感叹号加等号( != )
1 1 == 1 % 判断相等
2 1 ~= 2 % 判断不等
3 1 && 0 % 求逻辑与
4 1 || 0 % 求逻辑或
5 xor(1, 0) % 求异或
简化命令行
PS1('>> ');
分号 semicolon 不打印结果
>> a = 3; %semicolon supressing output
浮点数的输出
1 >> a = pi;
3 >> a
5 a = 3.1416
6 >> disp(a);
8 3.1416
9 >> disp(sprintf('2 decimals: %0.2f', a))
11 2 decimals: 3.14
12 >> disp(sprintf('6 decimals: %0.6f', a))
14 6 decimals: 3.141593
控制输出格式的长短
1 >> format long
3 >> a
5 a = 3.141592653589793
6 >> format short
8 >> a
10 a = 3.1416
5.1.2 向量和矩阵
1 >> A = [1 2; 3 4; 5 6]
5 1 2
6 3 4
7 5 6
9 >> A = [1 2;
11 3 4;
13 5 6]
17 1 2
18 3 4
19 5 6
21 >> v = [1 2 3]
25 1 2 3
27 >> v = [1; 2; 3]
31 1
32 2
33 3
通过步长生成行向量
1 >> v = 1:0.1:2
3 v =
5 Columns 1 through 4:
7 1.0000 1.1000 1.2000 1.3000
9 Columns 5 through 8:
11 1.4000 1.5000 1.6000 1.7000
13 Columns 9 through 11:
15 1.8000 1.9000 2.0000
17 >> v = 1:6
21 1 2 3 4 5 6
全是1, 或者全是0 的矩阵
1 >> v = ones(2,3)
5 1 1 1
6 1 1 1
8 >> v = ones
10 v = 1
11 >> v = ones(3)
15 1 1 1
16 1 1 1
17 1 1 1
19 >> v = 2*ones(2,3)
23 2 2 2
24 2 2 2
26 >> w = zeros(1,3)
30 0 0 0
使用eye() 函数生成单位矩阵(eye is a pun for identity)
1 >> I = eye(6)
7 1 0 0 0 0 0
8 0 1 0 0 0 0
9 0 0 1 0 0 0
10 0 0 0 1 0 0
11 0 0 0 0 1 0
12 0 0 0 0 0 1
矩阵大小
1 >> A = [1 2; 3 4; 5 6]
5 1 2
6 3 4
7 5 6
15 >> sz = size(A) % 矩阵大小
19 3 2
21 >> size(sz)
25 1 2
27 >> size(A,1) % 矩阵行数
29 ans = 3
30 >> size(A,2) % 矩阵列数
32 ans = 2
48 >> length(A) % length输出矩阵最大维的大小
50 ans = 3
获取元素
1 >> A = [1 2; 3 4; 5 6; 7 8; 9 10]; 2 >> A(3,2) % 获取一个元素 3 6 4 >> A(2, :) % 获取一行元素,冒号指所有列 5 3 4 6 >> A([1 3], :) % 返回 1、3 两行的元素 7 1 5 8 2 6 9 >> A(2:4, :) % 返回 2、3、4 三行元素(注意和上一个的区别) 10 3 4 11 5 6 12 7 8 13 14 >> A(2:3) % 这里很奇怪,是从上到下依次返回 15 3 5 16 >> A(2:5) 17 3 5 7 9 18 >> A(1:10) 19 1 3 5 7 9 2 4 6 8 10
矩阵转置
1 21> A'
2 ans =
3 1 3 5
4 2 4 6
6 22> (A')'
7 ans =
8 1 2
9 3 4
10 5 6
5.1.3 矩阵赋值和拼接
矩阵赋值
1 >> A(:,2) = [10; 11; 12] % 给A的第二列赋值 2 A = 4 1 10 5 3 11 6 5 12
扩充矩阵
1 >> A = [A , [100; 101; 102]] % 给矩阵添加一列 2 A = 4 1 10 100 5 3 11 101 6 5 12 102 8 >> A = [A ; [100 101 102]] % 给矩阵添加一行 9 A = 11 1 10 100 12 3 11 101 13 5 12 102 14 100 101 102
矩阵转换成列向量
1 >> A(:) % 冒号含义很特殊,将A中所有元素都放于一个列向量中 2 ans = 4 1 5 3 6 5 7 100 8 10 9 11 10 12 11 101 12 100 13 101 14 102 15 102
拼接两个矩阵
1 >> A = [1 2; 3 4; 5 6] 2 A = 4 1 2 5 3 4 6 5 6 8 >> B = [11 12; 13 14; 15 16] 9 B = 11 11 12 12 13 14 13 15 16 15 >> C = [A B]% “横”着连接18 1 2 11 12 19 3 4 13 14 20 5 6 15 16 23 >> C = [A, B]% “横”着连接24 C = 26 1 2 11 12 27 3 4 13 14 28 5 6 15 16 30 >> C = [A; B]% “竖”着连接31 C = 33 1 2 34 3 4 35 5 6 36 11 12 37 13 14 38 15 16
5.1.4 随机数
取随机数,定义维度,随机数大小总在0到1之间
1 >> w = rand(3,3)
3 w =
5 0.19782 0.42514 0.10275
6 0.83117 0.66312 0.37967
7 0.27300 0.92920 0.62790
生成一个一行三列的 高斯随机分布
1 >> w = randn(1,3)
3 w =
5 -0.025352 0.023321 1.729415
生成一个一行10000列,均值为6的高斯随机分布矩阵
>> w = - 6 + sqrt(10) * (randn(1,10000));
使用hist()函数展示直方图
hist(w)
生成50个条的直方图
hist(w, 50)
5.2 移动数据
参考视频: 5 - 2 - Moving Data Around (16 min).mkv
pwd 指令:得到Octave默认路径;
cd 指令:change direction 即改变路径,自己指定路径,但路径名中不要包含汉字
ls 指令:列出默认路径中包含的所有路径或者文件
load test.dat : 加载文件中的数据到test变量中
load('test.dat') : 同上
test : 显示test变量里的数据内容
who/whos : 列出目前Octave工作空间中包含的所有变量
clear test : 删除工作空间的变量test
V = test(1 : 10) : 取test中的前十个赋值给变量v
save hello.mat V : 将变量V保存在hello.mat文件中,注意当再次加载进来时,变量的名称仍然是V 而非文件名hellosave hello.txt V -ascii: 存为可以看的 txt 文件
从文件中加载数据到变量
1 >> ls % 查看路径下的文件
5 Directory of D:\myc_learn\machine_learning\code\week2
6
7 [.] [..] featuresX.dat priceY.dat
8 2 File(s) 658 bytes
9 2 Dir(s) 770,788,524,032 bytes free
12 >> load featuresX.dat % 使用load 加载房屋特征文件
19 >> featuresX % 打印featuresX
20 featuresX =
22 2343 3
23 4343 6
24 2222 3
25 1245 2
26 2345 5
27 2234 2
28 2123 6
... ...
72 >> size(featuresX) % 矩阵大小
73 ans =
75 47 2
77 >> load('priceY.dat') % 加载文件
78 >> size(priceY)
79 ans =
81 47 1
使用who 和whos 查看都有哪些变量
1 >> who
2 Variables in the current scope:
4 A ans featuresX priceY sz
6 >> whos
7 Variables in the current scope:
9 Attr Name Size Bytes Class
10 ==== ==== ==== ===== =====
11 A 3x2 48 double
12 ans 1x2 16 double
13 featuresX 47x2 752 double
14 priceY 47x1 376 double
15 sz 1x2 16 double
17 Total is 151 elements using 1208 bytes
删除变量
1 >> clear featuresX
2 >> who
3 Variables in the current scope:
5 A ans priceY sz
保存变量到文件
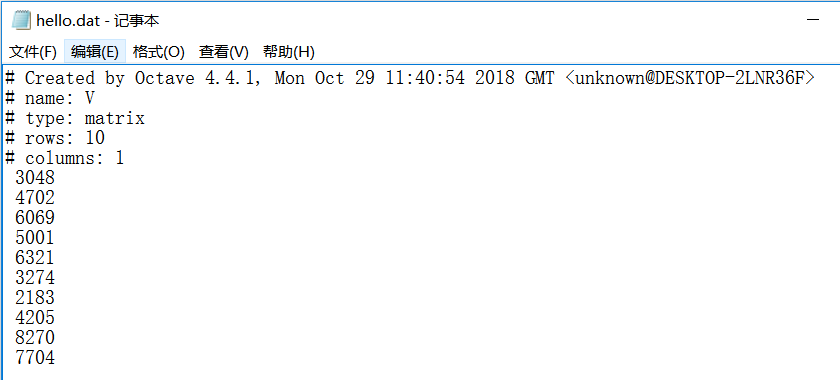
1 >> V = priceY(1:10) % 将priceY的前10个元素赋值给V
2 V =
4 3048
5 4702
6 6069
7 5001
8 6321
9 3274
10 2183
11 4205
12 8270
13 7704
15 >> save hello.mat V % 将V保存到文件hello.dat中
16 >> clear V % 清除变量V
18 >> whos % 查看都有哪些变量
19 Variables in the current scope:
21 Attr Name Size Bytes Class
22 ==== ==== ==== ===== =====
23 A 3x2 48 double
24 ans 1x2 16 double
25 priceY 47x1 376 double
26 sz 1x2 16 double
28 Total is 57 elements using 456 bytes
保存的 hello.mat 是二进制格式。 如果保存成 dat 格式,文件中数据如下:
从文件中加载回变量V
1 >> load hello.mat
2 >> whos
3 Variables in the current scope:
5 Attr Name Size Bytes Class
6 ==== ==== ==== ===== =====
7 A 3x2 48 double
8 V 10x1 80 double
9 ans 1x2 16 double
10 priceY 47x1 376 double
11 sz 1x2 16 double
13 Total is 67 elements using 536 bytes
16 >> V
17 V =
19 3048
20 4702
21 6069
22 5001
23 6321
24 3274
25 2183
26 4205
27 8270
28 7704
保存成可以看的 txt 文件
1 save hello.txt V -ascii

因为用到房屋价格数据,干脆用Octave生成了一些随机数,粘贴进了文件 priceY.dat 里
1 A = 10000 * rand(1,47) % 生成47个0-1的随机数,并且乘以10000
2 disp(sprintf('%0.0f\n',A)) % 打印成整数形式
5.3 计算数据
参考视频: 5 - 3 - Computing on Data (13 min).mkv
5.3.1 矩阵相乘
矩阵相乘 矩阵点乘
1 1> A = [1 2; 3 4; 5 6]
7 3> C = [1 1 ; 2 2]
12 4> A * C % 矩阵相乘
14 5 5
15 11 11
16 17 17
8 B =
9 11 12
10 13 14
11 15 16
14 5> A .* B % 矩阵点乘 各元素逐一相乘
16 11 24
17 39 56
18 75 96
在每个元素上操作
A .^ 2 % 每个元素取平方
1 ./ A % 取倒数
5.3.2 向量计算
最大值
1 23> a = [1 15 2 0.5]
5 24> val = max(a)
6 val = 15
8 25> [val, ind] = max(a) % ind 返回最大值位置
9 val = 15
10 ind = 2
向量逻辑判断
1 a < 3 % 对每个元素进行逻辑判断
3 1 0 1 1
5 find(a < 3) % 在上面进行逻辑判断的基础上,返回结果为真的索引
7 1 3 4
向量常用函数
sum(a) % 所有元素求和
prod(a) % 所有元素相乘
floor(a) % round down 向下取整
ceil(a) % round up 向上取整
round(a) % 四舍五入
std(a) % 求标准差
mean(a) % 求平均值
abs([-1;2;-3]) % 取绝对值
log(v) % 取log
exp(v) % 取e为底的指数, e=2.71828
向量运算
1 12> v
3 1
4 2
5 3
14 15> -v
16 -1
17 -2
18 -3
20 16> v + ones(length(v), 1)
22 2
23 3
24 4
26 18> ones(3,1)
28 1
29 1
30 1
32 19> v + ones(3,1)
34 2
35 3
36 4
38 20> v + 1
40 2
41 3
42 4
5.3.1 矩阵最大值
随机矩阵中的最大值
1 >> rand(3)
3 0.64927 0.22644 0.61599
4 0.87125 0.68797 0.60553
5 0.69778 0.25321 0.12596
7 >> max(rand(3), rand(3)) % 随机矩阵中的最大值
9 0.51841 0.89632 0.75562
10 0.21897 0.68484 0.75206
11 0.97807 0.73515 0.75578
求矩阵的行最大值、列最大值 element-wise comparison
1 >> A
3 8 1 6
4 3 5 7
5 4 9 2
7 >> max(A) % 返回每一列的最大值
9 8 9 7
11 >> max(A,[],1) % 返回每一列的最大值
13 8 9 7
15 >> max(A,[],2) % 返回每一行的最大值
17 8
18 7
19 9
两种求矩阵中所有元素最大值的方法
1 >> max(max(A))
2 ans = 9
3 >> max(A(:))
4 ans = 9
5.3.1 矩阵相乘
A = magic(3) % 生成一个magic squares。其行、列、对角线 元素和等于同一个数
[r,c] = find(A>=7) %返回符合条件元素的行坐标和列坐标
sum(A,1) % 矩阵每一列相加
sum(A,2) % 矩阵每一行相加
A .* eye(9) % 矩阵主对角线的值
sum(sum(A .* eye(9))) % 主对角线求和
flipud(eye(9)) % 次对角线的值
sum(sum(A .* flipud(eye(9)))) % 次对角线求和
1 33> A = magic(3)
3 8 1 6
4 3 5 7
5 4 9 2
7 34> [r,c] = find(A>=7) % 返回符合条件元素的行坐标和列坐标
8 r =
9 1
10 3
11 2
13 c =
14 1
15 2
16 3 % 即(1,1)(3,2)(2,3)三个元素>=7
矩阵列相加,行相加
1 >> A = magic(9)
3 47 58 69 80 1 12 23 34 45
4 57 68 79 9 11 22 33 44 46
5 67 78 8 10 21 32 43 54 56
6 77 7 18 20 31 42 53 55 66
7 6 17 19 30 41 52 63 65 76
8 16 27 29 40 51 62 64 75 5
9 26 28 39 50 61 72 74 4 15
10 36 38 49 60 71 73 3 14 25
11 37 48 59 70 81 2 13 24 35
13 >> sum(A,1) % 矩阵每一列相加
15 369 369 369 369 369 369 369 369 369
17 >> sum(A,2) % 矩阵每一行相加
19 369
20 369
21 369
22 369
23 369
24 369
25 369
26 369
27 369
矩阵主对角线的值
1 >> A .* eye(9) % 矩阵主对角线的值
4 47 0 0 0 0 0 0 0 0
5 0 68 0 0 0 0 0 0 0
6 0 0 8 0 0 0 0 0 0
7 0 0 0 20 0 0 0 0 0
8 0 0 0 0 41 0 0 0 0
9 0 0 0 0 0 62 0 0 0
10 0 0 0 0 0 0 74 0 0
11 0 0 0 0 0 0 0 14 0
12 0 0 0 0 0 0 0 0 35
14 >> sum(sum(A .* eye(9))) % 主对角线求和
15 ans = 369
矩阵次对角线的值
1 >> flipud(eye(9)) % 次对角线的值
6 0 0 0 0 0 0 0 0 1
7 0 0 0 0 0 0 0 1 0
8 0 0 0 0 0 0 1 0 0
9 0 0 0 0 0 1 0 0 0
10 0 0 0 0 1 0 0 0 0
11 0 0 0 1 0 0 0 0 0
12 0 0 1 0 0 0 0 0 0
13 0 1 0 0 0 0 0 0 0
14 1 0 0 0 0 0 0 0 0
16 >> sum(sum(A .* flipud(eye(9)))) % 次对角线求和
17 ans = 369
5.4 绘制数据图
参考视频: 5 - 4 - Plotting Data (10 min)
5.4.1 绘制曲线
1、画一个sin曲线
1 >> t = [0:0.01:0.98];
2 >> y1 = sin(2 * pi * 4 * t);
3 >> plot(t,y1);
2、画一个cos曲线
1 >> y2 = cos(2 * pi * 4 * t);
2 >> plot(t,y2);

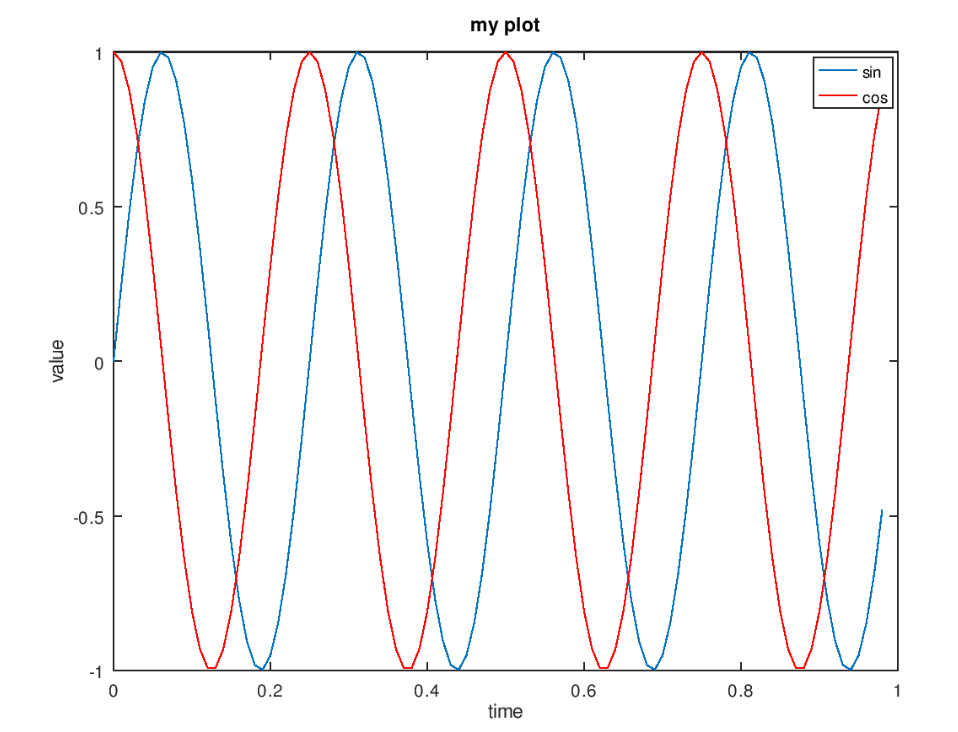
3、将两个曲线合并在一起
1 >> plot(t,y1);
2 >> hold on
3 >> plot(t,y2,'r');

4、给图像添加信息
1 > xlabel('time') % X轴标签
2 >> ylabel('value') % Y轴标签
3 >> legend('sin','cos') % 添加曲线名称
4 >> title('my plot') % 添加标题
5、保存到文件
1 >> print -dpng 'myPlot.png'
2 >> ls
3 Directory of D:\myc_learn\machine_learning\code\week2
5 [.] 5.m hello.dat myPlot.png
6 [..] featuresX.dat hello.txt priceY.dat
9 >> close
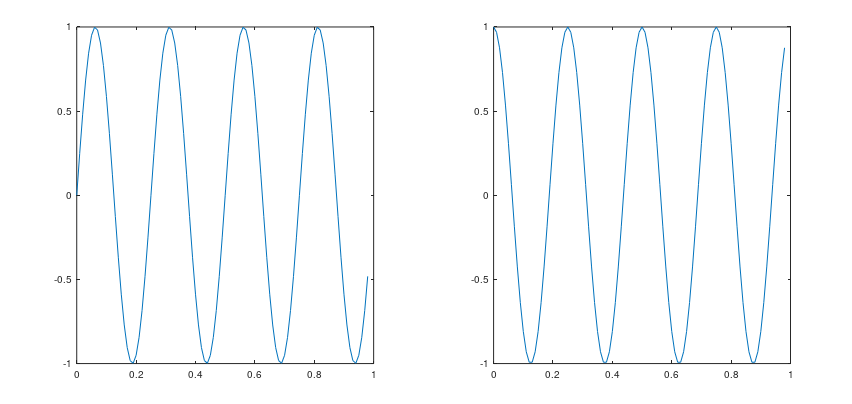
6、绘制多张图
绘制多张图,需要指定将哪个曲线放在哪个图中。否则会一直绘制在当前窗口,覆盖之前的图形
1 >> figure(1); plot(t,y1); % 在figure1中绘制
2 >> figure(2); plot(t,y2); % 在figure2中绘制
7、将两个图显示在一张图片中
1 >> subplot(1,2,1); % 将图片划分为两个格子,访问第一个格子
2 >> plot(t,y1) % 画第一个图像
3 >> subplot(1,2,2); % 访问第二个格子
4 >> plot(t,y2) % 画第二个图像
8、改变坐标轴范围
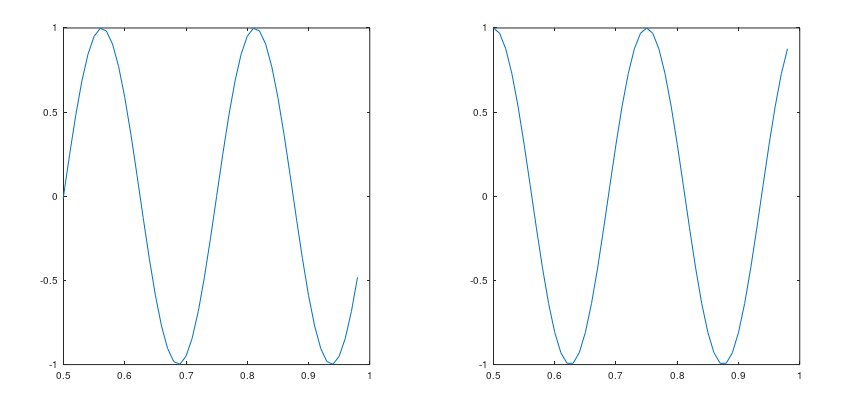
1 >> axis([0.5 1 -1 1])
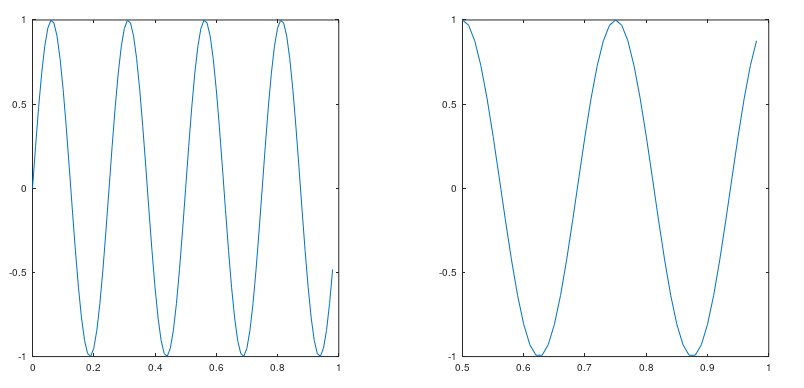
点击一下第一张图片,再运行一下上面那行代码,图变为:
9、清空和关闭图片
1 >> clf % 清空
2 >> close % 关闭
5.4.2 绘制可视化矩阵
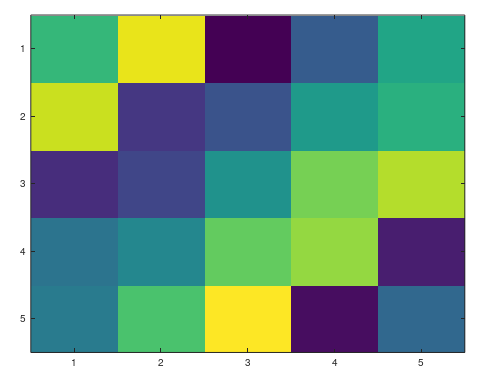
1、生成矩阵图
根据矩阵的值生成图像,不同的颜色对应矩阵中不同的值
1 >> A = magic(5)
2 A =
3 17 24 1 8 15
4 23 5 7 14 16
5 4 6 13 20 22
6 10 12 19 21 3
7 11 18 25 2 9
8 >> imagesc(A)
2、显示颜色条
1 >> colorbar
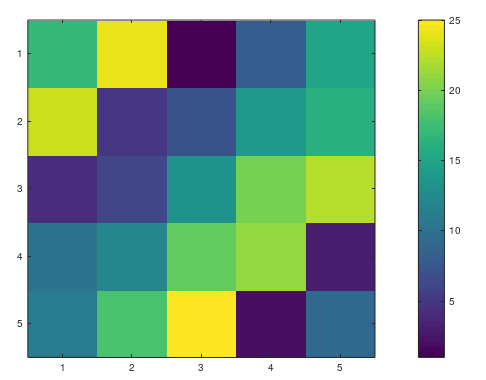
或者直接使用下面的一行代码:
1 >> imagesc(magic(5)), colorbar;
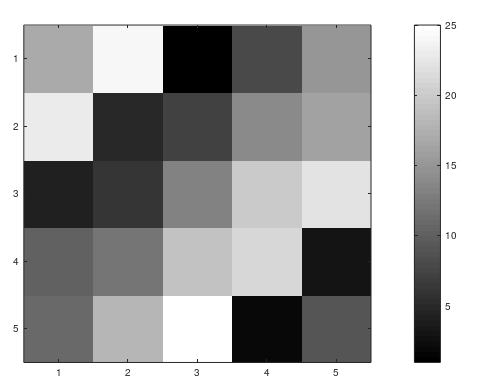
3、生成灰度图
1 >> imagesc(A), colorbar, colormap gray;
生成一个15行15列灰度图
1 >> imagesc(magic(15)),colorbar,colormap gray;
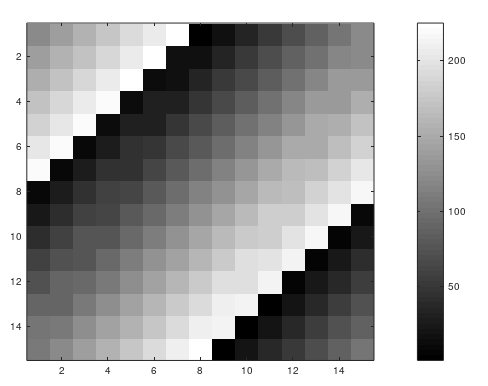
以 imagesc(magic(15)),colorbar,colormap gray; 为例。
这种几个逗号隔开的命令一起运行的方式,叫做逗号连接函数调用 comma chaining of function calls 或 comma chaining commands 。
比如赋值操作可以写成:a=1, b=2, c=3;
5.4.3 散点图
1 plot(x,y,'rx', 'MarkerSize', 10);
2 xlabel('Population of City in 10,000s');
3 ylabel('Profit in $10,000s');
4 title('POPULATION AND PROFIT');
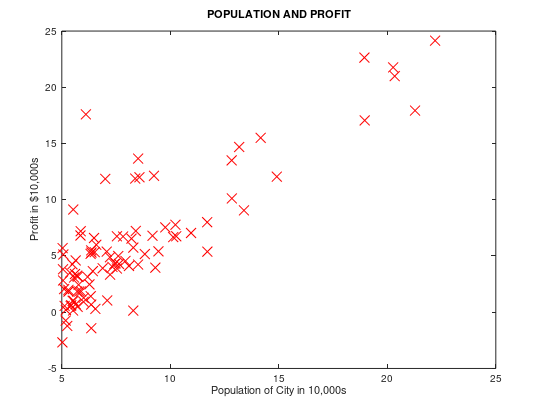
图像绘制在Octave官方文档的 15.2.1 Two-Dimensional Plots ,图形属性设置在15.3.3.4 Line Properties。
如果想设置某个属性,直接写属性名,后面跟一个值。plot (x, y, property, value, …)
例如 plot (x, y, 'linewidth', 2, …);

5.5 控制语句: for, while, if 语句
参考视频: 5 - 5 - Control Statements_ for, while, if statements (13 min).mkv
1、for 循环 通过 index 访问列向量
1 >> v = zeros(10,1)
2 v =
3 0
4 0
5 0
6 0
7 0
8 0
9 0
10 0
11 0
12 0
13 >> for i = 1 : 10,
14 v(i) = 2 ^ i;
15 end;
16 >> v
17 v =
18 2
19 4
20 8
21 16
22 32
23 64
24 128
25 256
26 512
27 1024
2、for 循环 直接访问列向量元素
1 >> indices = 1 : 10;
2 >> indices
3 indices =
4 1 2 3 4 5 6 7 8 9 10
5 >> for i = indices,
6 disp(i);
7 end;
8 1
9 2
10 3
11 4
12 5
13 6
14 7
15 8
16 9
17 10
3、while 循环访问列向量
1 >> i = 1;
2 >> while i <= 5,
3 v(i) = 100;
4 i = i + 1;
5 end;
6 >> v
7 v =
8 100
9 100
10 100
11 100
12 100
13 64
14 128
15 256
16 512
17 1024
4、while(true) 和 break
1 >> i = 1 ;
2 >> while(true),
3 v(i) = 999;
4 i = i + 1;
5 if i == 6,
6 break;
7 end;
8 end;
9 >>
10 >> v
11 v =
12 999
13 999
14 999
15 999
16 999
17 64
18 128
19 256
20 512
21 1024
5、if else 语句
1 >> v(1) = 2;
2 >> if v(1) == 1,
3 disp('The value is one');
4 elseif v(1) == 2,
5 disp('The value is two');
6 else,
7 disp('The value is not one or two');
8 end;
9 The value is two
6、自定义函数 function
定义函数 squareThisNumber(x),内容如下:
1 function y = squareThisNumber(x)
2 y = x^2;
3 endfunction
将函数保存为squarethisnumber.m,注意此时是小写。
这时候调用函数 squareThisNumber(2) 提示找不到函数
1 >> squareThisNumber(2);
2 error: 'squareThisNumber' undefined near line 1 column 1
3 >>
4 >> ls
5 [.] featuresX.dat priceY.dat
6 [..] hello.dat squarethisnumber.m
将文件命名为函数一致squareThisNumber.m(大小写也一致),这时候调用函数成功
1 >> ls
2 [.] featuresX.dat priceY.dat
3 [..] hello.dat squareThisNumber.m
4 >> squareThisNumber(2);
5 >> a = squareThisNumber(2);
6 >> a
7 a = 4
这说明:Octave 是大小写敏感的,文件名必须和函数名大小写一致。
7、多个返回值的函数
Octave 函数有和其他语言不一样的地方是可以返回多个值。定义方法squareAndCubeThisNumber(x)如下:
1 function [y1, y2] = squareAndCubeThisNumber(x),
2 y1 = x ^ 2;
3 y2 = x ^ 3;
4 endfunction
调用:
1 >> a = squareAndCubeThisNumber(2) % 接受了第一个返回值
2 a = 4
3 >> [a, b] = squareAndCubeThisNumber(2) % 接受两个返回值
4 a = 4
5 b = 8
8、更复杂的函数
保存下面的函数到costFunctionJ.m中
1 function J = costFunctionJ(X, y, theta),
2 % X is the "design matrix" containing our training examples
3 % y is the class labels
4
5 m = size(X, 1); % number of training examples, size of rows
6 predictions = X * theta; % predictions of hapothesis on all m examples
7 sqrErrors = (predictions - y) .^ 2; % squared errors .^ 指的是对数据中每个元素平方
8
9 J = 1 / (2 * m) * sum(sqrErrors);
10
11 endfunction

针对上边的数据集初始化矩阵。调用函数,计算代价函数的值。
1 >> X = [1 1; 1 2 ; 1 3];
2 >> y = [1;2;3];
3 >> theta = [0;1]; % Θ为0,1 h(x)=x 此时完全拟合数据,代价函数的值为0
4 >> j = costFunctionJ(X,y,theta)
5 j = 0
1 >> theta = [0;0]; % Θ 为0,0 h(x)=0 此时不能拟合数据
2 >> j = costFunctionJ(X,y,theta)
3 j = 2.3333
4
5 >> (1^2 + 2^2 + 3^2) / (2*3) % 代价函数的值
6 ans = 2.3333
5.6 向量化 Vectorization
参考视频: 5 - 6 - Vectorization (14 min).mkv
下面是向量化的小例子,如果将所有u(j) 、所有v(j)、所有w(j)都看成列向量,则公式变为为向量加法 u = 2v + 5w
![]()
再复杂一些,在线性回归中 h(x) 的公式如下:

假设此时n=2,只有两个特征。将其向量化:
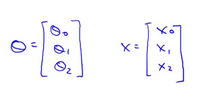
在Octave中,如果使用for循环实现,则为左边的代码。使用看做向量相乘,则只需要右边一行代码:
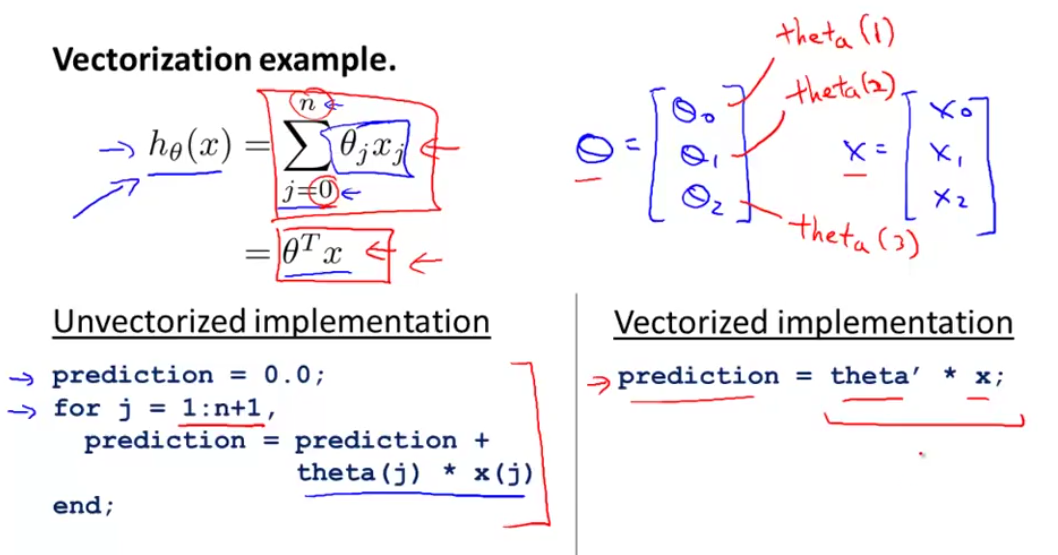
在C++中,for循环和向量化方法的对比如下:

当 n = 2 时,梯度下降的公式如下:

实现这三个方程的方式之一,是用一个 for 循环,让 j 分别等于 0、1、2 来更新 Θj。
因为三个参数是同步更新,可以用向量化的方法来实现。我们使用 δ 替代公式中下面这项(注意最右边 x 没有下标):

则δ是一个 n+1 维向量(在这里是3维)

α 是一个实数,α δ 也是 n+1 维向量
x(i) 是一个 n+1 维向量(在这里是3维)

公式变为一个向量减法:
Θ := Θ - α δ
有时我们使用几十或几百个特征量来计算线性归回,当使用向量化地实现线性回归,通常运行速度就会比 for 循环快的多
digram 对角线
plot 制图
semicolon 分号
column vector 列向量
row vector 行向量

 浙公网安备 33010602011771号
浙公网安备 33010602011771号