【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 18—Photo OCR 应用实例:图片文字识别
Lecture 18—Photo OCR 应用实例:图片文字识别
18.1 问题描述和流程图 Problem Description and Pipeline
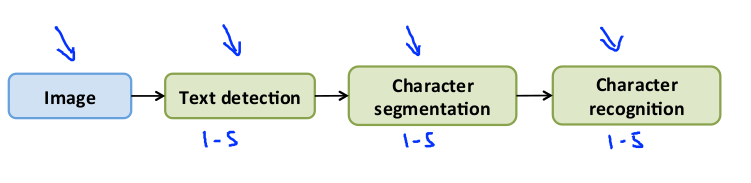
图像文字识别需要如下步骤:

1.文字侦测(Text detection)——将图片上的文字与其他环境对象分离开来
2.字符切分(Character segmentation)——将文字分割成一个个单一的字符
3.字符分类(Character classification)——确定每一个字符是什么
如果用任务流程图来表达这个问题,每一项任务可以由一个单独的小队来负责:
18.2 滑动窗口 Sliding Windows
滑动窗口是一项用来从图像中抽取对象的技术。
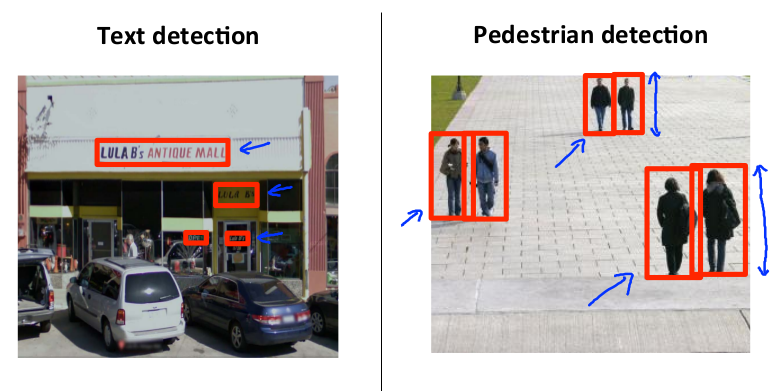
假使需要在图片中识别行人,首先用许多固定尺寸的图片来训练一个能够准确识别行人的模型。

之后使用训练模型时用的图片尺寸对预测图片进行剪裁,将切片交给模型判断其是否为行人,然后滑动剪裁区域,剪裁切片后再交给模型判断,直至将图片全部检测完。
然后按比例放大剪裁的区域,以新的尺寸对图片进行剪裁,将新剪裁的切片按比例缩小至模型采纳的尺寸,交给模型判断,如此循环。



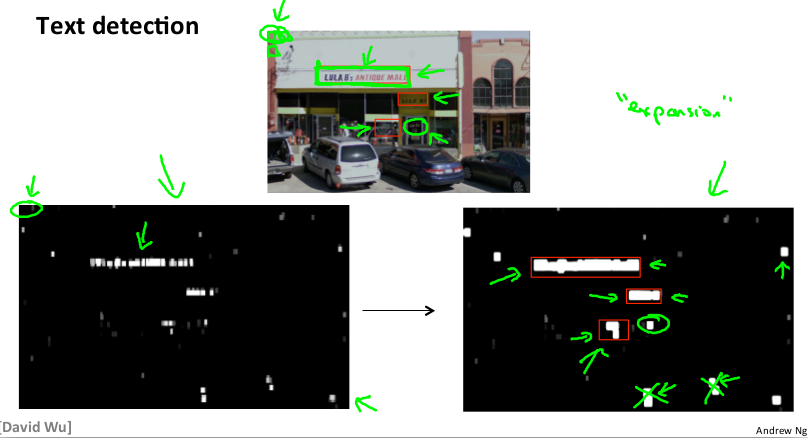
滑动窗口技术也被用于文字识别,首先训练模型使其能够区分字符与非字符,然后,运用滑动窗口技术识别字符。一旦完成了识别,将识别得出的区域进行一些扩展,然后将重叠的区域进行合并。

接着以宽高比作为过滤条件,过滤高度比宽度更大的区域(因为单词的长度通常比高度要大)。下图中绿色区域是识别出的文字区域,红色区域是被忽略的。
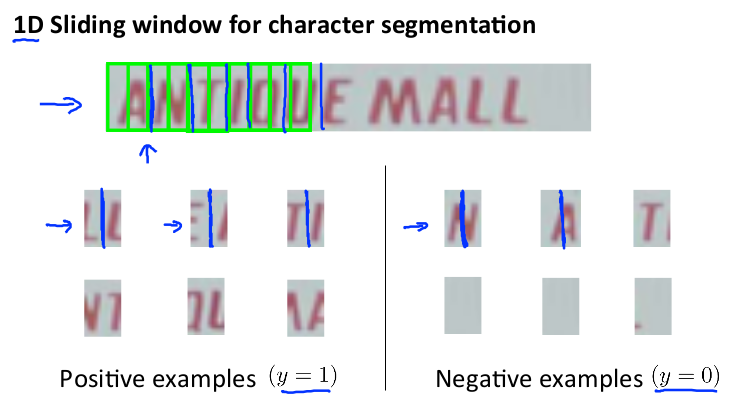
下一步是训练模型分割字符,需要的训练集为单个字符的图和两个相连字符之间的图。模型训练完后,仍然使用滑动窗口技术来进行字符识别。
最后是字符分类阶段,利用神经网络、支持向量机或者逻辑回归算法训练一个分类器即可。
18.3 获取大量数据和人工数据 Getting Lots of Data and Artificial Data
以文字识别应用为例,一种方法是从网站下载各种字体,利用不同的字体配上各种不同的随机背景,创造出一些用于训练的实例,能够获得一个无限大的训练集。这属于从零开始创造实例。


另一种方法是,对已有的数据进行修改,例如将其进行扭曲、旋转、模糊处理。只要认为实际数据有可能和处理后的数据类似,便可以用这样的方法来创造大量的数据。
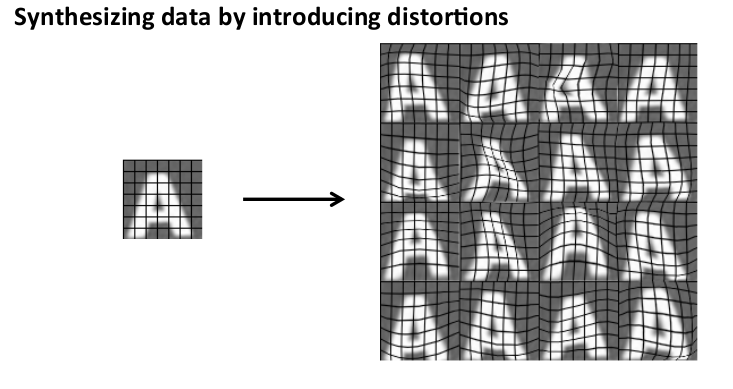
某些处理起不到增加数据集的作用,例如加入高斯噪声、将单个图片复制多份等

在增大数据集之前,必须确保当前训练的已经是一个低偏差的模型。不然增大数据集也没有用
有关获得更多数据的几种方法: 1.人工数据合成;2.手动收集、标记数据;3.众包

18.4 上限分析 What Part of the Pipeline to Work on Next
如何知道哪一部分最值得花时间和精力去改善呢?可以使用流程图进行上限分析,流程图中每一部分的输出都是下一部分的输入。
在上限分析中,我们选取一部分,手工提供 100%正确的输出结果,然后看应用的整体效果提升了多少。假使当前总体效果为 72%的正确率:
1) 如果让文字检测部分100%正确,系统的总体效果从 72%提高到了89%。这意味着很值得投入时间精力来提高我们的文字检测的准确度
2) 接着让字符切分结果100%正确,系统总体效果只提升了 1%,这意味着字符切分部分可能已经足够好了
3) 最后让字符分类100%正确,系统总体效果又提升了10%,这意味着我们可能也会应该投入更多的时间和精力到分类这部分

另一个上限分析的例子,人脸识别:
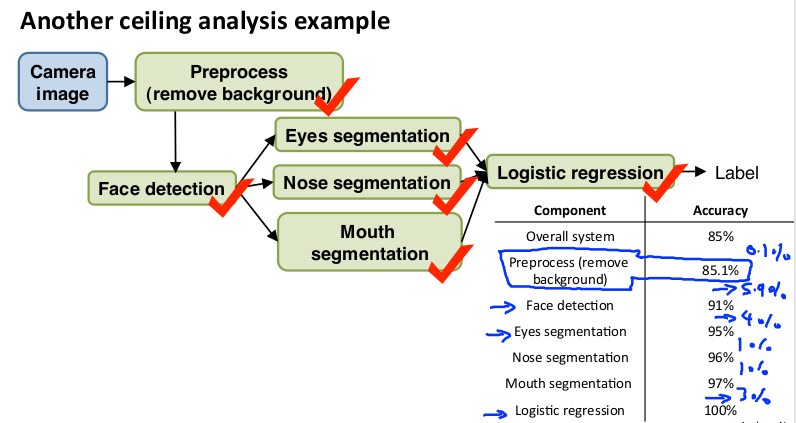
其中最值得优化的是:脸部检测Face detection,眼部分割Eyes segmentation 和 逻辑回归Logistic regression 三个部分。
建议不要根据直觉,而是使用上限分析判断应该改进哪个模块。当把精力花在最值得优化的那个模块上,会让整个系统的表现有显著的提高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号