【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 11—Machine Learning System Design 机器学习系统设计
Lecture 11—Machine Learning System Design
11.1 垃圾邮件分类
本章中用一个实际例子: 垃圾邮件Spam的分类 来描述机器学习系统设计方法。首先来看两封邮件,左边是一封垃圾邮件Spam,右边是一封非垃圾邮件Non-Spam:
垃圾邮件有很多features。如果我们想要建立一个Spam分类器,就要进行有监督学习,将Spam的features提取出来,而希望这些features能够很好的区分Spam。
事实上,对于spam分类器,通常选取spam中词频最高的100个词来做feature。
为了构建分类器算法,可能有很多策略:
1. 收集更多的数据,让我们有更多的垃圾邮件和非垃圾邮件的样本
2. 基于邮件的路由信息开发一系列复杂的特征
3. 基于邮件的正文信息开发一系列复杂的特征,包括考虑截词的处理
4. 为探测刻意的拼写错误(把 watch 写成 w4tch)开发复杂的算法
11.2 误差分析 Error Analysis
构建一个学习算法的推荐方法为:
1. 从一个简单的能快速实现的算法开始,实现该算法并用交叉验证集数据测试这个算法
2. 绘制学习曲线,决定是增加更多数据,或者添加更多特征,还是其他选择
3. 进行误差分析:人工检查交叉验证集中我们算法中产生预测误差的实例,看看这些实例是否有某种系统化的趋势
例如下图中,对100个分类错误的邮件进行人工分析,左边区分了它们的类型分布,右边分析没有被正确分类的原因。

在误差分析的时候,不能单纯依靠直觉gut feeling ,而是用数字体现。
例如,对于discount/discounts/discounted/discounting 是否被视为都含有discount这个feature。如果看作含有这个feature,结果有3%的error;如果不看做有这个feature,则有5%的error。以此进行比较。
注:使用Porter stemmer 这种软件可以合并类似的单词,但是也可能引发错误。
11.3 类偏斜的误差度量 Error Metrics for Skewed Classes
Skewed Classes:一个分类问题,结果仅有两类y=0和y=1,其中一类样本非常多、另一类非常少。
对于偏斜数据集,如果单纯考虑准确率accuracy,会导致有时候模型预测的结果,还不如全部判断为1或者全部判断0 的结果好。 所以需要引入另外一些辅助度量指标
考虑一个二分问题,即将实例分成正类(positive)或负类(negative)。对一个二分问题来说,会出现四种情况:
1. 正确肯定(True Positive,TP):预测为真,实际为真
2. 正确否定(True Negative,TN):预测为假,实际为假
3. 错误肯定(False Positive,FP):预测为真,实际为假
4. 错误否定(False Negative,FN):预测为假,实际为真
这样就可以建立一个Error Metrics(下图左),并定义precision和recall,如下图所示: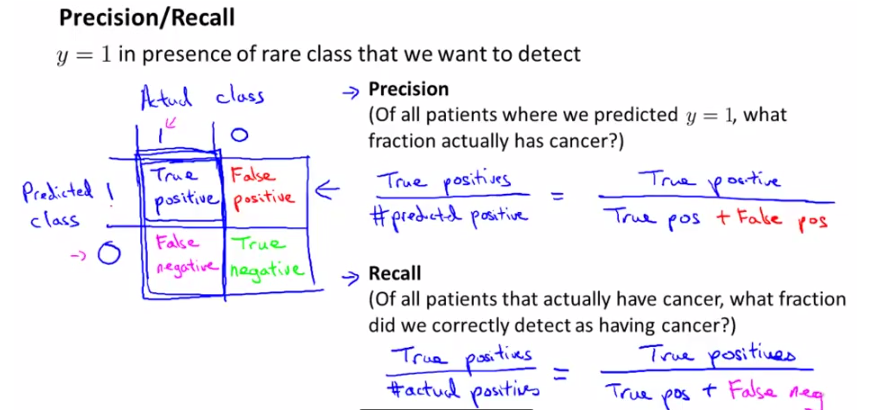

计算公式:

precision: 正确预测的正样本/所有预测为正样本的
recall:正确预测正样本/真实值为正样本的;
假设有一个spam分类任务,测试集只有1%为spam邮件(y=1),99%为non-spam邮件(y=0)。
(1)如果全都分类为non-spam 非垃圾邮件:
precision=0/(0+1)=0,recall=0/(0+99)=0,accurancy=(0+99)/100*100% = 99%
可以看出虽然acuracy 很高,但是recall 和 precision都是0,模型不合格。
(2)如果全都分类为spam 垃圾邮件:
precision=1/(99+1)*100%=1%, recall=1/(1+0)*100%=100%, accurancy=(1+0)/100*100% = 1%
precision 和 accuracy 都很低,模型也不合格。
所以,无论数据集是否偏斜,需要满足precision 和 recall 都很高才可以保证该算法的实用性。
11.4 查准率Precision 和 查全率Recall 之间的权衡
分类结果在0-1之间,所以我们需要选择一个阈值,大于阈值的分类为1,小于阈值的分类为0。
precision-recall 和阈值的关系如下:
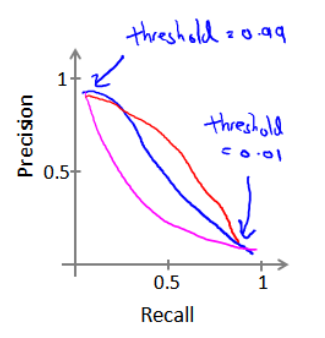
threshould 设定越高,查准率Precision越高、查全率Recall越低。因为判断的准、但有更多正例被漏掉。
threshould 设定越低,查准率Precision越低、查全率Recall越高。因为找的全,但有更多负例被错判为正例。
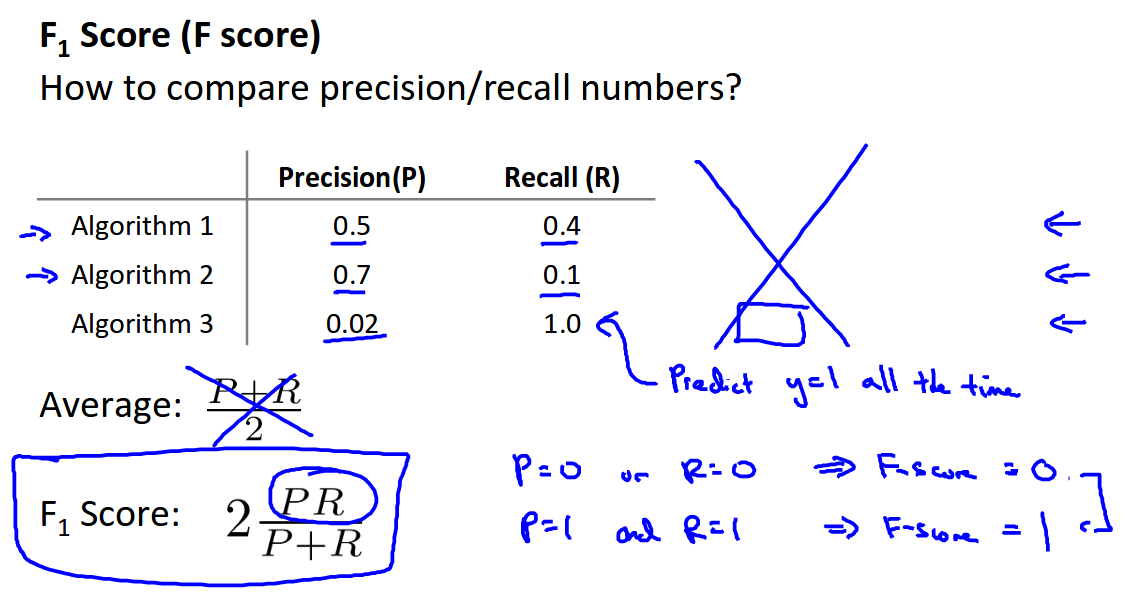
那么如何选择阈值? 我们引入一个评价标准 F1Score,选择使F1值最大的阈值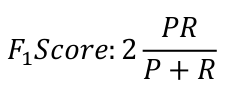
下面这个例子中,算法1的F1 值最高
11.5 数据集的大小
对于机器学习,通常可以选择很多不同的算法进行预测,随着训练集规模增大,Accuracy一般会提高:
但事实上,单纯增大数据集并不能解决一切问题。 如果数据集中含的信息很少(比如想对房价进行预测,但是只有面积数据。这时候即使增加数据、或者对模型在面积这个feature上进行多项式处理,也起不到好的效果)
总之,结论为:
如果模型欠拟合,即偏差bias大: 那就要增加特征(对神经网络增加hidden units);
如果模型过拟合,即方差variance大: 那就要增大数据集,使得Jcv ≈ Jtrain ,从而降低过拟合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号