Redis_01_数据类型
@
数据类型
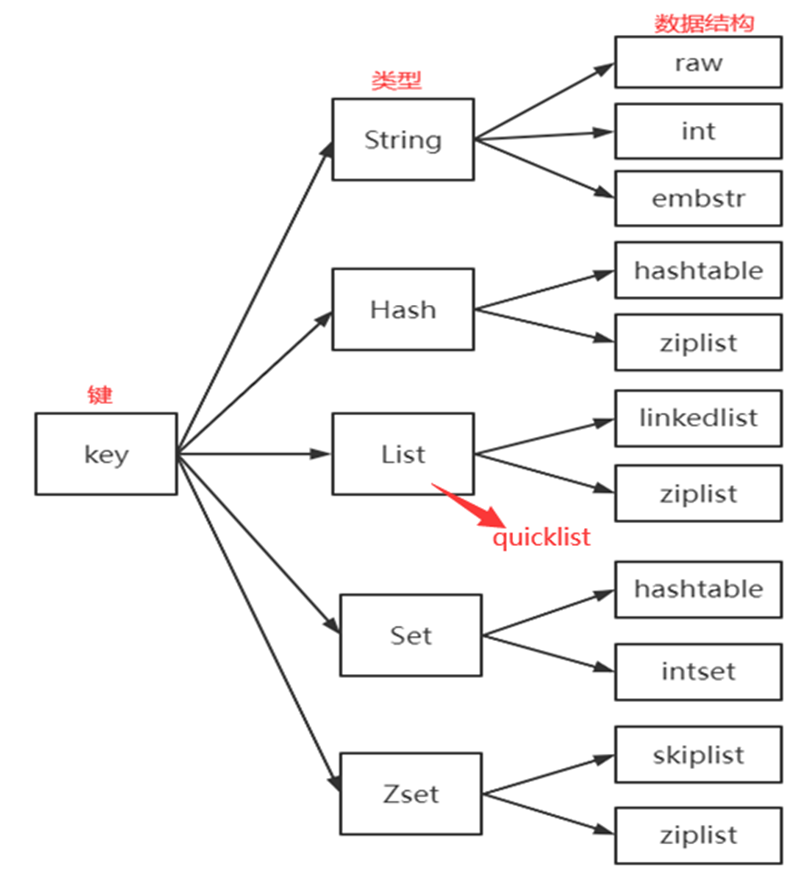
Redis内置5种键类型:字符串、哈希、列表、集合、有序集合
1)每种类型的底层编码实现可为多种(都有两种以上);
2)根据其底层不同数据结构的实现区分各种键;
//Redis中无命名空间概念,键名可为任意字符、符号和数字组成
如:Redis键类型和底层数据结构实现
字符串
字符串(String):一键一值关系
1)值可为字符串、数字和二进制数据(大小不能超512MB);
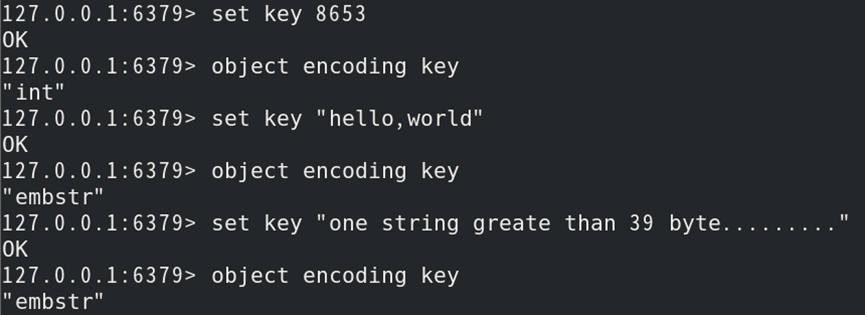
2)底层数据结构格式分为:int、embstr和raw
//字符串是Redis最基础的键类型(其他键类型均基于字符串类型实现);
Redis会根据值类型和长度自动选择数据供结构作为对应字符串键的底层
| 数据结构 | 说明 |
|---|---|
| int | 8个字节的长整型 |
| embstr | 小于等于39个字节的字符串 |
| raw | 大于39个的字符串 |
如:创建不同的字符串键,并判断其类型
常用命令
创建
(1)创建键:set 键名 值 选项
1)批量创建键:mset 键名1 值1 键名N 值N
2)创建成功返回OK;
3)选项分为以下4种:
| 选项 | 说明 |
|---|---|
| ex 数值N | 指定键的过期时间为N秒 |
| px 数值N | 指定键的过期时间为N毫秒 |
| nx | 仅在指定键名不存在才可执行(添加) |
| xx | 指定键名必须存在才可执行(更新) |
//setex和setnx命令是set命令分别加上ex和nx选项的变体
(2)重定义键:getset 键名 值
1)若指定键不存在,则返回“(nil)”;
2)返回指定键原来的值;
(3)修改指定位字符:setrange 键名 索引位 字符
1)使用指定字符替换值中索引位的字符;
2)成功替换返回OK;
(4)值自增(跨度为1):incr 键名
1)只能对值类型为整数的键应用(否则返回“error”);
2)返回自增后的结果(若键不存在,则默认初始化为0且自增1);
3)类似命令如下:
| 命令 | 说明 |
|---|---|
| incrby | 指定跨度自增 |
| decr | 自减(跨度为1) |
| decrby | 指定跨度自减 |
| incrbyfloat | 浮点数自增(指定跨度) |
(5)追加值:append 键名 值
1)向指定键名的尾部添加值(不常用,一般直接重新赋值键);
2)返回添加值后的长度;
获取
(1)获取值:get 键名
1)批量获取值:mget 键名1 键名N
2)若获取的键不存在,则返回“(nil)”;
3)返回获取指定键的值(返回顺序为指定键的顺序);
(2)获取值长度:strlen 键名
1)字符和数字占一位,汉字占三位;
2)返回指定键对应值的字符串长度;
(3)返回部分字符串:getrange 键名 索引位1 索引位2
1)返回值中索引位1到索引位2的字符串(包含2个索引位);
2)索引位从0开始;
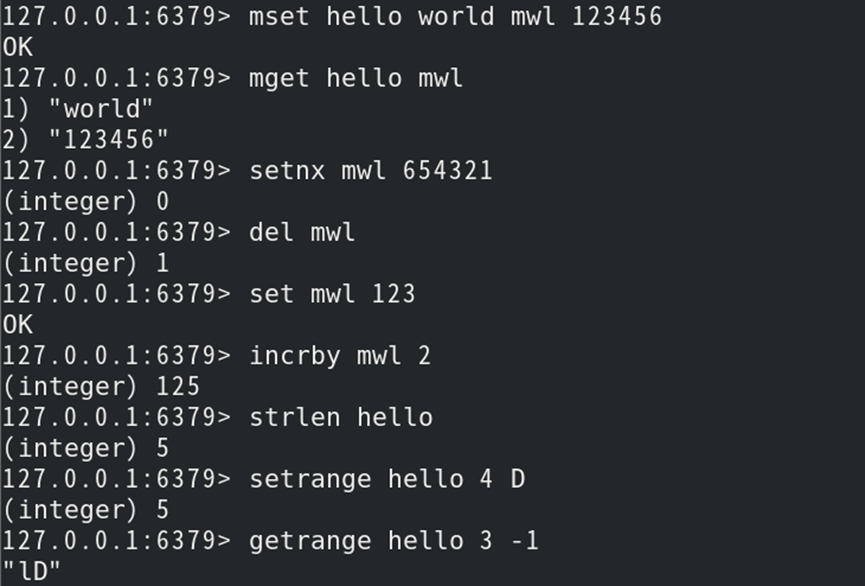
如:创建字符串键值对,并获取值和修改
如:单次操作和批量操作的时间区别
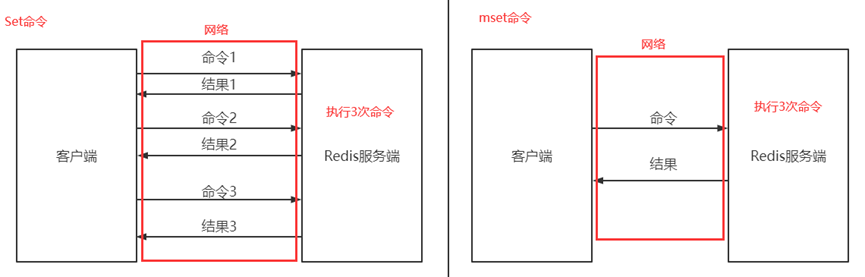
1)N次set/get命令时间 = N次网络时间 + N次set/get命令时间
2)1次mset/mget命令时间 = 1次网络时间 + N次set/get命令时间
//批量命令操作需限制数量,否则可能导致Redis阻塞或网络拥塞
哈希
哈希(Hash):一键多值关系,且键也可为键值对(字典)
1)若值也是键值对,则相对值为键的值称为“内值”;
2)底层数据结构格式分为:ziplist(压缩列表)和hashtable(哈希表)
Redis会根据值个数和大小自动选择数据供结构作为对应键的底层
-
ziplist:当值的个数小于hash-max-ziplist-entries(默认512)个,且小于hash-max-ziplist-value(默认64)字节时(多个值连续存储,更节省内存);
-
hashtable:当值条件不能满足ziplist时(读写时间复杂度为O(1))
如:创建不同的哈希键,并判断其类型
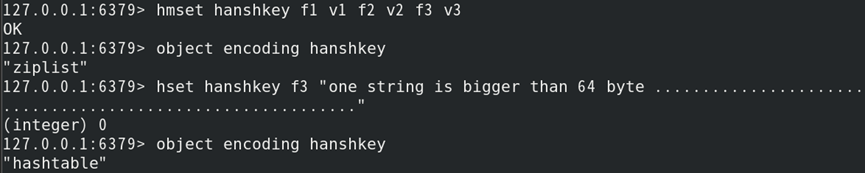
//若键的底层已为hashtable,即使后续条件再满足ziplist也不会切换
常用命令
创建
(1)创建键:hset 键 值 内值
1)批量创建:hmset 键名1 值1 内值1 键名N 值N 内值N
2)hsetnx命令是hset命令的基础上,指定值必须存在才可设置内值;
3)创建成功返回1(反之返回0);
(2)内值自增(跨度默认为1):hincrby 键 值 跨度
1)只能对内值类型为整数的值应用(否则返回“error”);
2)返回自增后的结果(若值不存在,则默认初始化为0且自增1);
3)hincrbyfloat命令可对浮点数类型进行自增运算(可指定跨度,默认为1);
获取
(1)键中值数量:hlen 键名
1)返回指定键含有值的个数
(2)判断值是否存在:hexists 键名 值
1)若存在返回1,不存在则返回0;
(3)获取内值:hget 键名 值
1)批量获取内值:hmget 键名 值1 值N
2)返回获取指定内值(返回顺序为指定值的顺序);
3)若获取的键不存在,则返回“(nil)”;
(4)获取内值长度:hstrlen 键 值
1)字符和数字占一位,汉字占三位;
2)返回指定值对应内值的字符串长度;
(5)获取所有值:hkeys 键名
1)返回指定键的所有值;
(6)获取所有内值:hvals 键名
1)返回指定键的所有内值;
(7)获取所有值和内值:hgetall 键名
1)返回顺序为:先值后内值
2)若指定键中值数量较多时,可能导致Redis阻塞(可使用scan命令代替)
删除
(1)删除值:hdel 键名 值1 值N
1)值被删除后,其对应的内值也随之被删除;
2)返回成功删除值的个数;
如:创建哈希键值对,并获取/修改值和内值
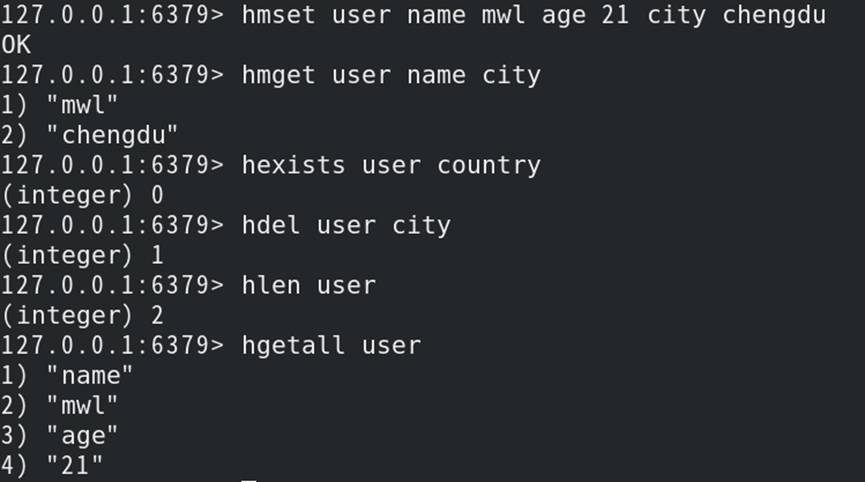
列表
列表(List):一键多值的有序关系,且可通过索引值获取(从0开始)
1)列表中只能存储2³²-1个值,且值可重复;
2)可在列表的两端进行插入(Push)和弹出(Pop)操作;
3)底层数据结构格式分为:ziplist(压缩列表)、linkedlist(链表)
Redis会根据值个数和大小自动选择数据供结构作为对应键的底层
-
ziplist:当值的个数小于list-max-ziplist-entries(默认512)个,且小于list-max-ziplist-value(默认64)字节时(多个值连续存储,更节省内存)
-
hashtable:当值条件不能满足ziplist时
-
quicklist:结合ziplist和linkedlist(默认使用)
| 参数 | 说明 |
|---|---|
| list-max-ziplist-size | 指定最大压缩空间或长度 (默认值-2代表8KB) (负数指定最大压缩空间,正数指定长度) |
| list-compress-depth | 指定最大压缩深入 (默认值0代表不压缩) |
//list-max-ziplist-entries和list-max-ziplist-value参数已被废弃
常用于实现栈(仅一端Push和Pop)和队列(两端均可Push和Pop):
lpush + lpop = Stack(栈)
lpush + rpop = Queue(队列)
lpush + ltrim = Capped Collection(有限集合)
lpush + brpop = Message Queue(消息队列)
//索引值为负数时,代表从列表的末端开始定位
常用命令
创建
(1)创建键分为:从末端添加值创建、从前端添加值创建
1)从末端添加值创建:rpush 键名 值1 值N
2)从前端添加值创建:lpush 键名 值1 值N
3)返回成功添加值的个数
(2)添加值:linsert 键名 before或after 定位值 添加值
1)将指定值添加到定位值的前方(before)或后方(after);
2)返回插入成功后的列表的长度(含值个数);
(3)修改值:lset 键名 索引 新值
1)将指定索引代表的值替换为新值;
2)替换成功返回OK;
获取
(1)获取列表长度(所含值个数):llen 键名
1)返回键的长度(所含值个数);
(2)获取值:lindex 键名 索引值
1)返回指定索引值代表的值
(3)获取范围内的值:lrange 键名 索引1 索引2
1)返回索引1到索引2之间的所有值(包括两个索引);
2)默认从左到右定位(索引值为负数时,则从右到左);
删除
(1)弹出值分为:末端弹出值、前端弹出值
1)末端弹出值:rpop 键
2)前端弹出值:lpop 键
3)返回被弹出的值(默认仅弹出一个);
(2)删除匹配值:lrem 键名 数值N 匹配值
1)匹配到特定值开始执行删除操作(仅删除匹配值),删除个数为N;
2)删除个数满足N时则停止,若删除个数不足则继续匹配;
3)返回成功删除值的个数(可能不等于N,保证不阻塞);
4)N的取值影响删除操作:
| 取值 | 说明 |
|---|---|
| N > 0 | 从左到右,删除最多N个匹配值 |
| N < 0 | 从右到左,删除最多N个匹配值 |
| N == 0 | 删除所有匹配值 |
(3)删除范围外的值:ltrim 键名 索引1 索引2
1)仅保留索引1到索引2范围内之间的值(包括两个索引),其他均删除;
2)删除成功返回OK;
(4)阻塞弹出值分为:末端阻塞弹出值、前端阻塞弹出值
1)末端阻塞弹出值:brpop 键1 键N 阻塞时间M
2)前端阻塞弹出值:blpop 键1 键N 阻塞时间M
3)brpop是M秒内从左到右遍历N个键直到有值可弹出并返回(blpop反之);
4)多个客户端对同一个键执行brpop/blpop,则最先执行的客户端获得值;
5)返回被弹出的值(若M秒内无值可返回,则返回“(nil)”);
如:创建列表键值对,并获取/修改值和内值
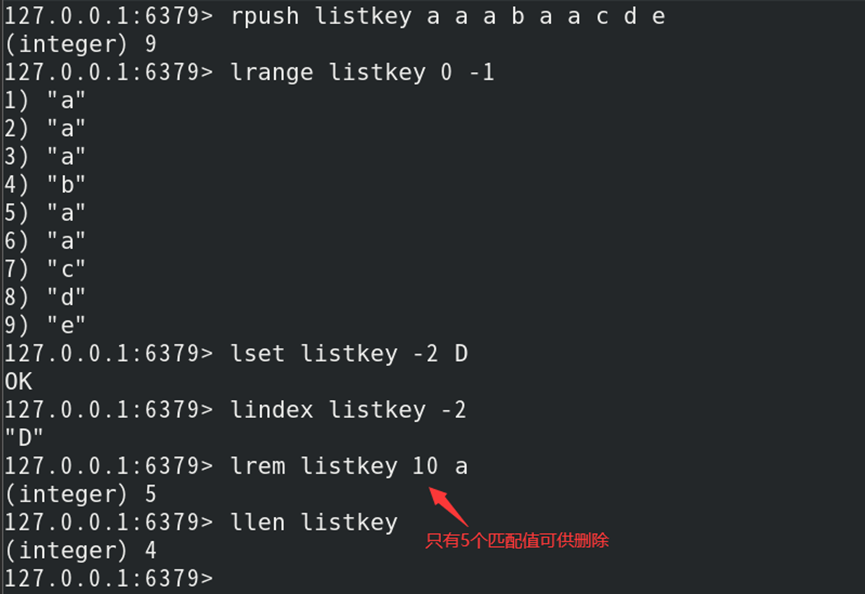
集合
集合(Set):一键多值的无序关系
1)列表中只能存储2³²-1个值,且值不可重复;
2)多个集合之间可进行交集、并集和差集操作;
3)底层数据结构格式分为:intset(整数集合)、hashtable(哈希表)
Redis会根据值个数和大小自动选择数据供结构作为对应键的底层
-
intset:值均为整数类型,且个数小于set-max-intset-entries(默认512)个;
-
hashtable:当值条件不能满足ziplist时
//intset底层编码具有使用更小内存的优势
//若底层编码为intset,插入数据时会自动进行排序和去重
如:创建不同的集合键,并判断其类型
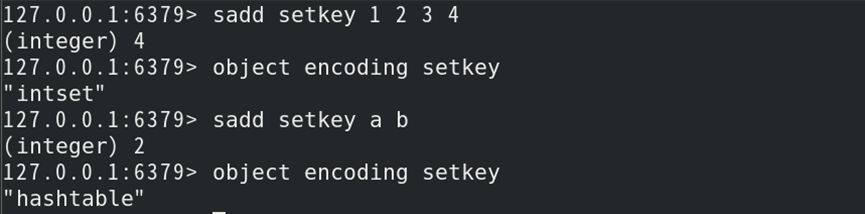
常用命令
创建
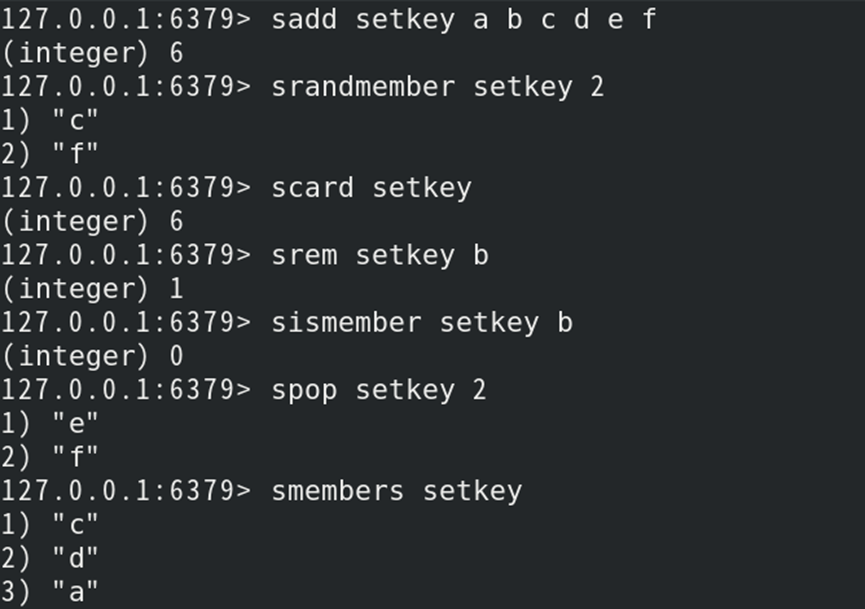
(1)创建键:sadd 键名 值1 值N
1)返回成功添加值的个数;
(2)交集:sintersotroe 新键名 键名1 键名N
1)将多个集合键之间的交集结果存储至新键(相同值);
2)返回新键中所含值的个数;
(3)并集:sunionstore 新键名 键名1 键名N
1)将多个集合键之间的并集结果存储至新键(所有值,排序重复值);
2)返回新键中所含值的个数;
(4)差集:sdiffstore 新键名 键名1 键名N
1)将多个集合键之间的差集结果存储至新键(不同值);
2)返回新键中所含值的个数;
获取
(1)键中值数量:scard 键名
1)返回指定键中所含有的值的个数;
2)时间复杂度为O(1),其直接查询内部变量获得;
(2)判断值是否存在:sismember 键名 值
1)若存在返回1,不存在则返回0;
(3)获取随机值:srandmember 键名 数量N
1)从集合键中随机获取N个值(默认1个);
2)返回获取的值(仅获取,不删除);
(4)获取所有值:smembers 键名
1)返回指定键中所有的值;
2)由于集合是无序的,所以返回结果也是无序(每次返回结果可能不同);
//若指定键中所含有值过多时,可能导致Redis阻塞
删除
(1)删除值:srem 键名 值1 值N
1)返回成功删除值的个数;
(2)随机弹出值:spop 键名 数量N
1)指定集合键中随机弹出N个值(默认弹出1个);
2)返回弹出的值;
如:创建集合键值对,并获取/修改值和内值
交/并/差
(1)交集:sinter 键名1 键名N
1)返回多个集合键之间的交集结果(相同值);
(2)并集:sunion 键名1 键名N
1)返回多个集合键之间的并集结果(所有值,排序重复值);
(3)差集:sdiff 键名1 键名N
1)返回多个集合键之间的差集结果(不同值);
如:计算两个集合键之间交、并和差集

有序集合
有序集合(Zset):一键多值的有序关系
1)列表中只能存储2³²-1个值,且值不可重复;
2)多个集合之间可进行交集、并集和差集操作;
3)通过给每个值设置权重值进行排序(权重值可重复);
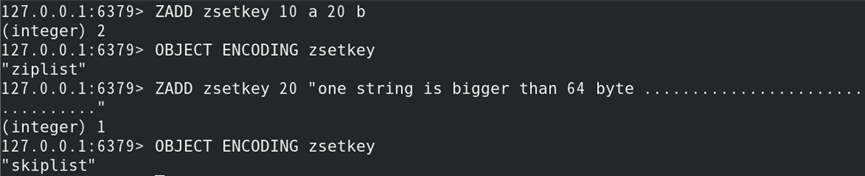
4)底层数据结构格式分为:ziplist(压缩列表)、skiplist(跳跃表)
Redis会根据值个数和大小自动选择数据供结构作为对应键的底层
-
ziplist:当值的个数小于list-max-ziplist-entries(默认512)个,且小于list-max-ziplist-value(默认64)字节时(多个值连续存储,更节省内存)
-
skiplist:当值条件不能满足ziplist时
如:创建不同的集合键,并判断其类型
常用命令
创建
(1)创建键:ZADD 键名 选项 权重值1 值1 权重值N 值N
1)返回成功添加值的个数;
2)选项如下(可省略):
| 选项 | 说明 |
|---|---|
| NX | 键必须不存在才可执行(创建) |
| XX | 键必须存在才可执行(添加值) |
| CH | 返回该次执行后,值发生变化的个数 |
| incr | 仅增加权重值 |
(2)增加权重值:ZINCRBY 键名 权重值 值
1)返回添加权重值的权重值;
2)若指定值不存在,则将值添加到键中(并赋予指定的权重值);
获取
(1)键中值数量:ZCARD 键名
1)返回指定键中所含有的值的个数;
2)时间复杂度为O(1),其直接查询内部变量获得;
(2)获取权重值:ZSCORE 键名 值
1)返回指定值对应的权重值(若值不存在,则返回“(nil)”);
(3)获取排名:ZRANK 键名 值
1)返回指定值的在键中的排名(根据权重值,递增排序);
2)ZREVRANK命令同理,但以递减的形式排序;
//排序名从0开始技术
(4)获取范围内的值:ZRANGEBYSCORE 键名 最小值 最大值
1)返回权重值在最小值和最大值之间的值(包括范围值,递增);
2)可在最后添加“WITHSCORES”选项,同时显示该值的权重值;
3)可在最小值和最大值旁指定圆括号,代表不包含该范围值;
4)“-INF”和“+INF”分别代表无限小和无限大;
3)ZREVRANGEBYSCORE命令同理,但以递减的形式返回;
(5)获取范围内的值数量:ZCOUNT 键名 最小值 最大值
1)返回权重值在最小值和最大值之间的值个数(包括范围值);
(6)获取排名内的值:ZRANGE 键名 最小排名 最大排名
1)返回排名在最小排名和最大排名之间的值(包括排名,递增);
2)可在最后添加“WITHSCORES”选项,同时显示该值的权重值;
3)ZREVRANGE命令同理,但以递减的形式返回;
删除
(1)删除值:ZREM 键名 值1 值N
1)返回成功删除值的个数;
(2)删除分数范围内的值:ZREMRANGEBYSCORE 键名 最小值 最大值
1)删除权重值在最小值和最大值之间的值(包括范围值);
2)返回成功删除值的个数;
(3)删除排名范围内的值:ZREMRANGEBYRANK 键名 最小排名 最大排名
1)删除排名在最小排名和最大排名之间的值(包括排名);
2)返回成功删除值的个数;
如:创建有序键值对,并获取/修改值和内值

//若两个值的权重值相同,则按照两个值名的ASCII码值再排序(递增)
交/并
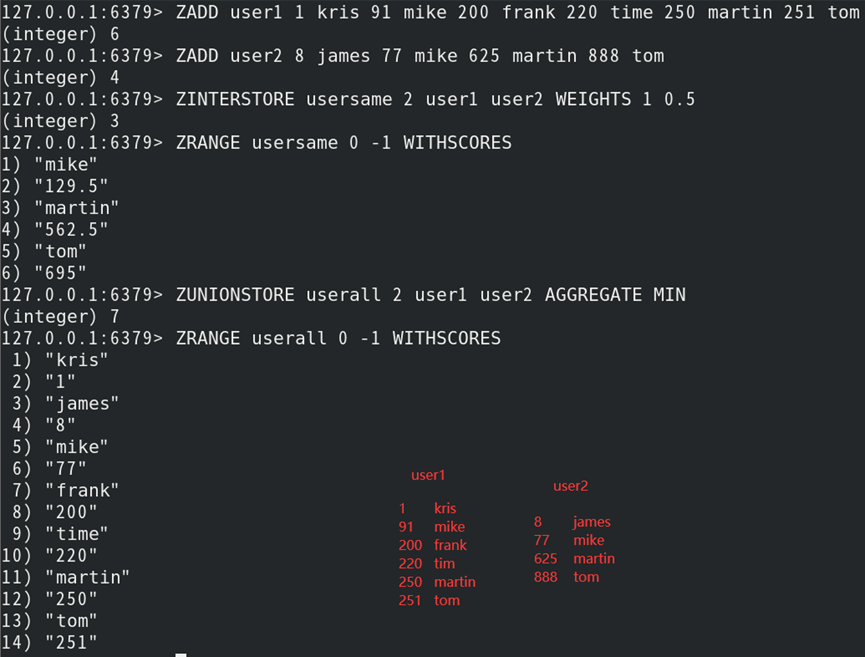
(1)并集:ZINTERSTORE 新键名 键个数 键1 键N 选项
1)将多个键的并集结果存储至新键中;
2)返回新键中所含值的个数;
3)选项如下:
| 选项 | 含义 |
|---|---|
| WEIGHTS 权重1 权重N | 每个键中权重值在计算时的权重 (默认全为1) |
| AGGREGATE MIN或MAX或SUM | 指定新键的权重值取值方式 (默认为SUM) |
权重公式如下:
| 权重公式 | 说明 |
|---|---|
| MIN | 保留最小权重值 |
| MAX | 保留最大权重值 |
| SUM | 多个权重值合并 |
(2)交集:ZUNIONSTORE 新键名 键个数 键1 键N 选项
1)将多个键的交集结果存储至新键中;
2)返回新键中所含值的个数;
3)选项等同于ZINTERSTORE命令;
如:计算两个集合键之间交集和并集

 浙公网安备 33010602011771号
浙公网安备 33010602011771号