Redis_08_Redis Cluster-集群
@
Redis Cluster
Redis Cluster(集群):Redis分布式存储
1)分布式存储:数据按照分区规则映射到多个节点;
2)Redis Cluster使用哈希分区规则映射数据(虚拟槽分区);
哈希分区规则分为:节点取余分区、一致性哈希分区、虚拟槽分区
(1)节点取余分区:根据特殊字段计算出的哈希值,将数据映射到节点
1)节点数量变化时,数据需迁移(哈希值重新计算);
2)扩容时通常采用翻倍扩容(避免映射全部打乱导致全量复制);
(2)一致性哈希(Distributed Hash Table):圆环式部署节点
1)每个节点均分配一个token(0~2³²),toekn构成哈希环;
2)读写操作时先计算键的哈希值,再顺时针匹配大于等于该哈希值的节点;
3)增/减节点只影响相邻节点,但会导致部分数据无法命中;
//部分一致性哈希在增/减节点时,需增加一倍或删除一般的节点保证负载均衡
(3)虚拟槽分区:数据映射到固定范围的整数集合中
1)槽(Slot):映射数据的整数结合(范围远大于节点数);
2)每个节点需尽可能平均分配槽;
Redis Cluster的哈希分区规则为:虚拟槽分区
1)槽范围是0~16383,且是数据管理/迁移的基本单位;
2)每个节点仅负责被分配到的槽和槽所映射的键值对;
//相对于1000个节点的集群,16383个槽足以使用(槽过多会导致消息头过大)
槽计算公式:Slot = CRC16(键)& 16383
Redis Cluster的限制:
1)仅支持部分键的批量操作(只支持拥有相同Slot值的键执行批量操作);
2)仅支持部分键的事务操作(只支持多个键在同一节点上的事务操作);
3)键是数据分区的最小粒度(不能将多层结构的对象存储到不同节点);
4)不支持多数据库空间(集群中所有Redis均默认使用0号数据库);
5)仅支持单层复制结构(不支持树状主从复制结构);
部署集群
部署集群:通过部署多个Redis节点并互通实现Redis Cluster
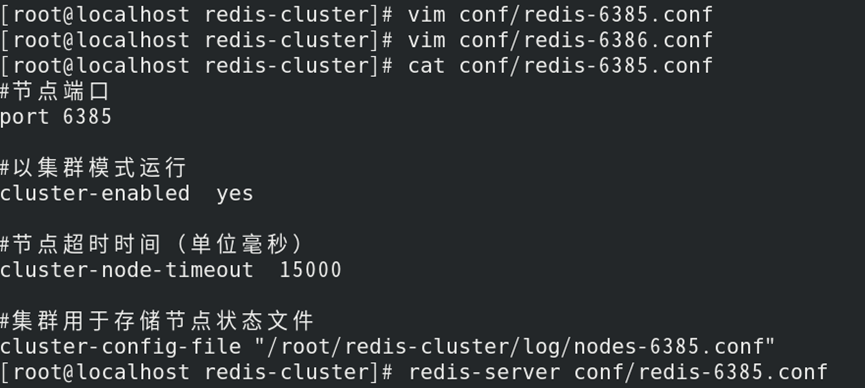
1)每个节点需配置参数“cluster-enabled yes”(Redis以集群模式运行)
2)每个节点在配置前需进行重置;
部署集群的2个建议:
(1)节点数量:根据业务所需控制实际数量
1)集群至少拥有6个节点,才可保证集群的完整和高可用性;
2)集群节点不建议超过1000个,避免网络拥堵
//节点过多时,Ping/Pong消息中所携带数据过多从而导致网络拥堵
(2)创建以下3个目录存储/管理集群中节点数据:
| 目录 | 说明 |
|---|---|
| conf | 节点配置文件 |
| data | 节点数据 |
| log | 节点日志 |
准备节点
如:部署具有6个节点(3主3从)的Redis Cluster
| 主/从节点 | IP:端口 | 系统 |
|---|---|---|
| 从节点 (其主节点6382) | 127.0.0.1:6379 | CentOS 8 |
| 从节点 (其主节点6383) | 127.0.0.1:6380 | CentOS 8 |
| 从节点 (其主节点6384) | 127.0.0.1:6381 | CentOS 8 |
| 主节点 | 127.0.0.1:6382 | CentOS 8 |
| 主节点 | 127.0.0.1:6383 | CentOS 8 |
| 主节点 | 127.0.0.1:6384 | CentOS 8 |
准备节点:启动6个Redis节点以备形成集群(尚未互通)
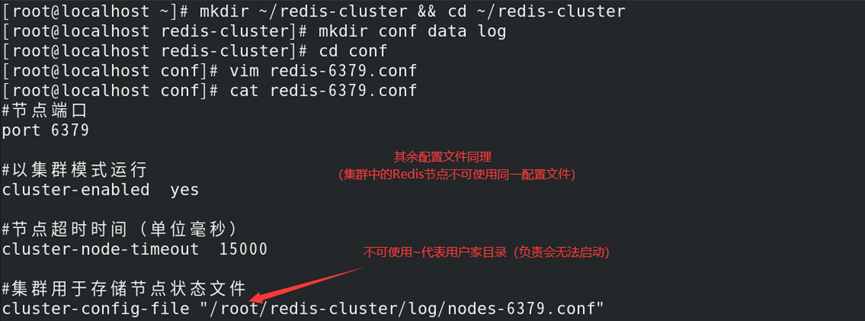
(1)创建所属工作目录并配置参数文件:
1)mkdir \~/redis-cluster && cd \~/redis-cluster
2)mkdir conf data log
3)根据所需Redis配置参数文件(除集群配置外,其他相同与普通Redis)
(2)启动所有主/从节点:
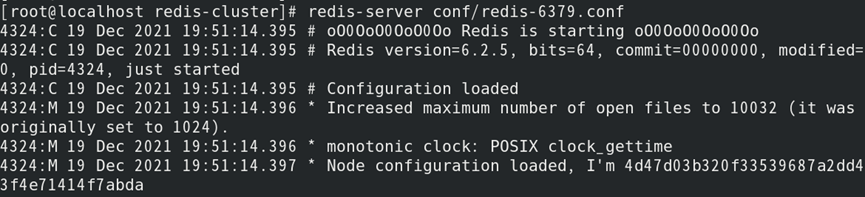
//集群模式下不能通过SLAVEOF添加从节点
(3)验证节点是否已启动

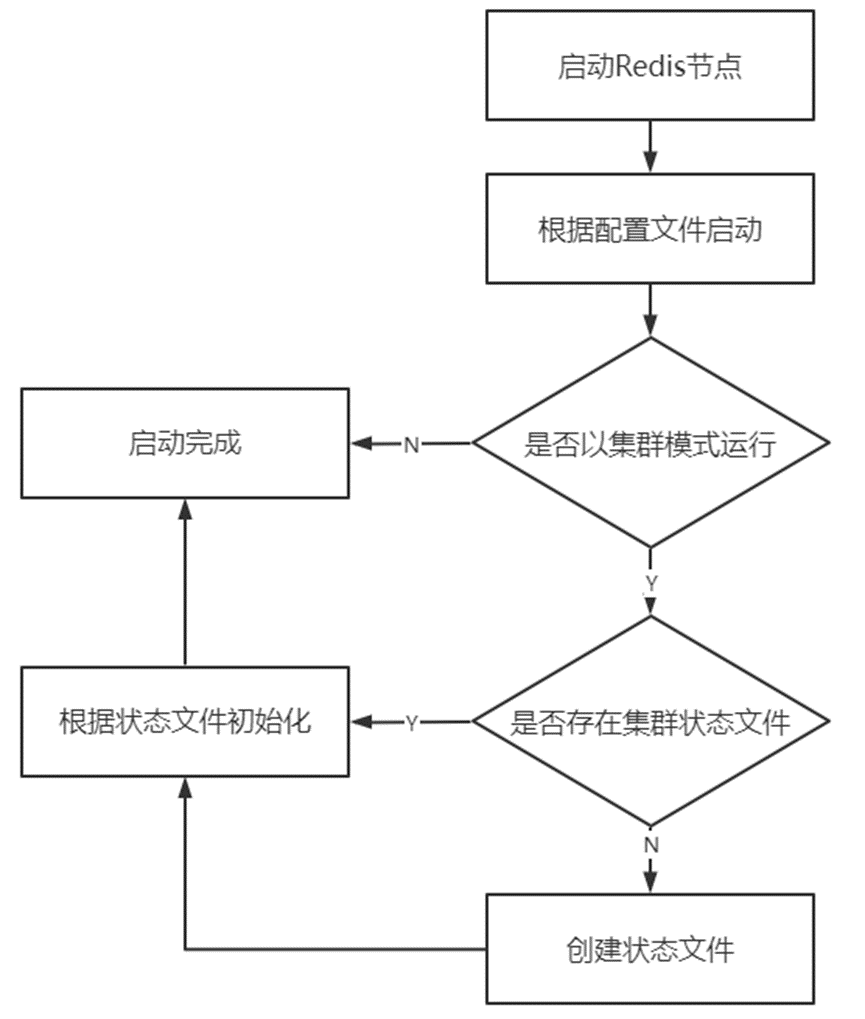
节点ID:集群中用于区分不同节点的唯一标识符
1)40位16进制字符串(存储于参数cluster-config-file指定文件);
2)节点ID只创建一次节点(重启后仍使用同一节点ID,不同于运行ID);
如:集群中节点启动流程
节点握手
节点握手:通过Gossip协议使6个节点互通(互相获取信息/监控)
节点握手流程(简约版):
1)节点A向节点B发送Meet信息;
2)节点B收到Meet信息后保存节点A的信息,并回复Pong信息;
3)节点A和节点B周期性发送Ping/Pong保证对方在线(心跳检测);
//握手状态会在集群内创博,其他节点自动与新节点发起握手流程
(1)启动节点客户端,并执行握手命令
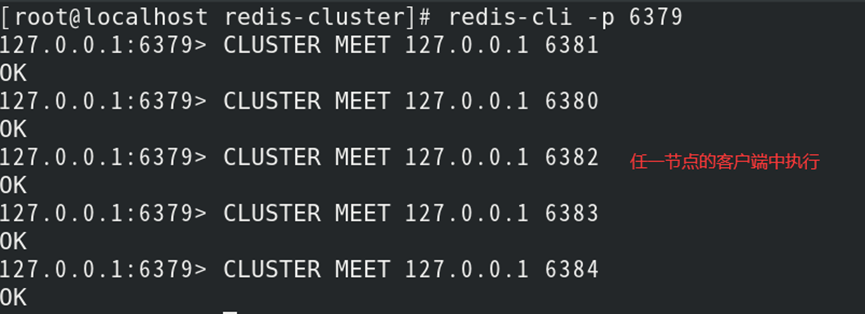
//节点握手属于异步命令,执行后立刻返回
(2)查看集群状态验证节点是否已互通:
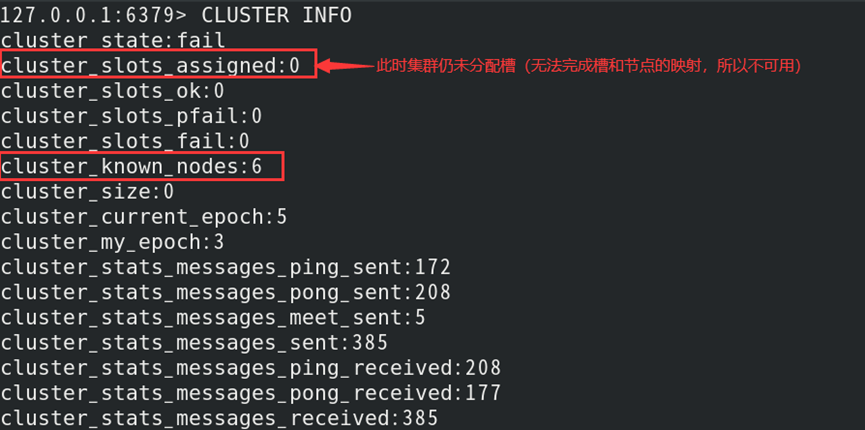
分配槽
分配槽:将16384个槽平均分配给集群中主节点
1)首次启动节点和被分配槽的节点默认都是主节点;
2)主从复制时,从节点会连同复制主节点的槽信息(实现故障转移);
(1)查看状态文件获取主节点ID(任一状态文件均可):
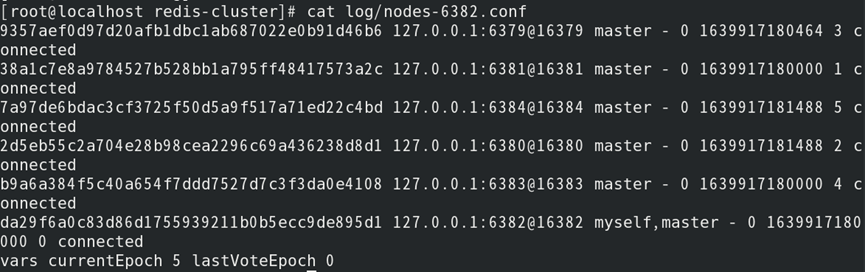
//默认状态下16384个槽均没有被分配(集群处于不可用状态)
(2)配置主从节点;
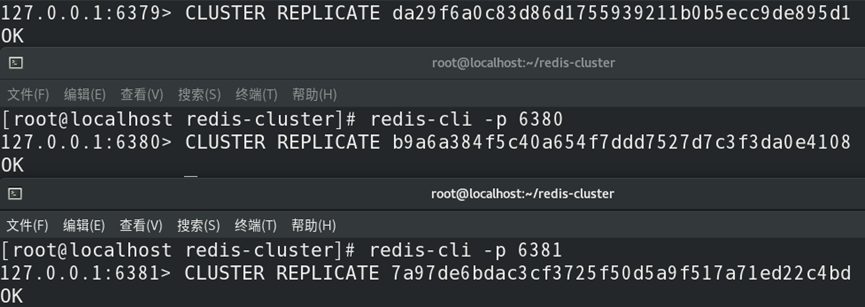
(3)平均分配槽给主节点;

(4)验证集群是否已部署完成:
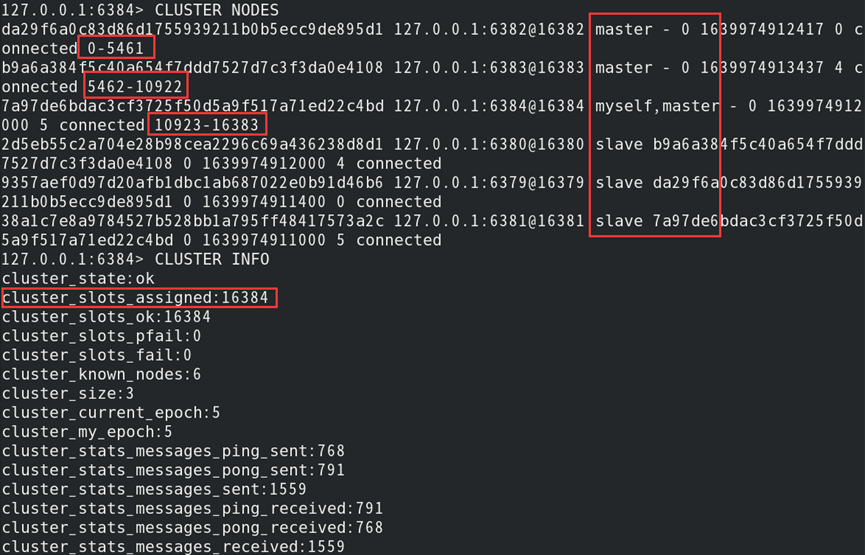
默认集群中存在任何一个槽没有分配给节点,集群均处于不可用状态
1)当持有槽主节点故障/下线时,会导致集群处于不可用状态;
2)可配置参数cluster-require-full-coverage为no,保证其他主节点的可用性;
集群优化
(1)通过CLUSTER KEYSLOT命令实现hash_tag
1)本质:槽映射多个键
2)常用于Redis IO优先:可使用批量操作命令
3)不能大量使用hash_tag,会导致集群倾斜(节点间的数据/请求量差异过大)
(2)通过READONLY命令实现集群读写分离
1)集群模式下默认从节点不接受任何读写请求(接收后会重定向到主节点);
2)开启集群读写分离后,从节点接收到对应主节点的读请求则会执行执行;
//READONLY属于连接级别的设置(READWRITE命令可关闭)
节点通信
节点通信:节点之间互相发送消息实现心跳检测和状态同步等功能
1)节点之间按照Gossip协议互相交换信息(节点元数据);
2)节点通信保证各个节点均能获知集群中全局节点的最新状态信息
//节点元数据:节点已知其他节点元数据、节点负责的数据和节点是否故障等
节点通信流程:
1)每个节点均开辟个TCP通道用于节点间通信(通信端口)
2)每个节点按特定规则周期性与选择节点发送Ping消息;
3)接收到Ping消息的节点回复Pong消息;
//通信端口号为指定端口号加10000
Gossip
Gossip协议:通过发送各类型消息实现各节点的信息交换
1)Gossip协议中5种消息类型如下:
| 消息类型 | 说明 |
|---|---|
| Meet | 通知节点加入集群 (节点加入集群后会周期性发送Ping/Pong消息) |
| Ping | 检测节点是否在线并发送节点元数据 (节点元数据:封装节点自身和部分其他节点的状态数据) |
| Pong | 响应Ping/Meet消息并发送节点元数据 (该节点元数据只封装自身状态数据) |
| Fail | 节点判断其他节点下线时,在集群内广播Fail消息 (其他节点接收Fail消息后会更新节点元数据) |
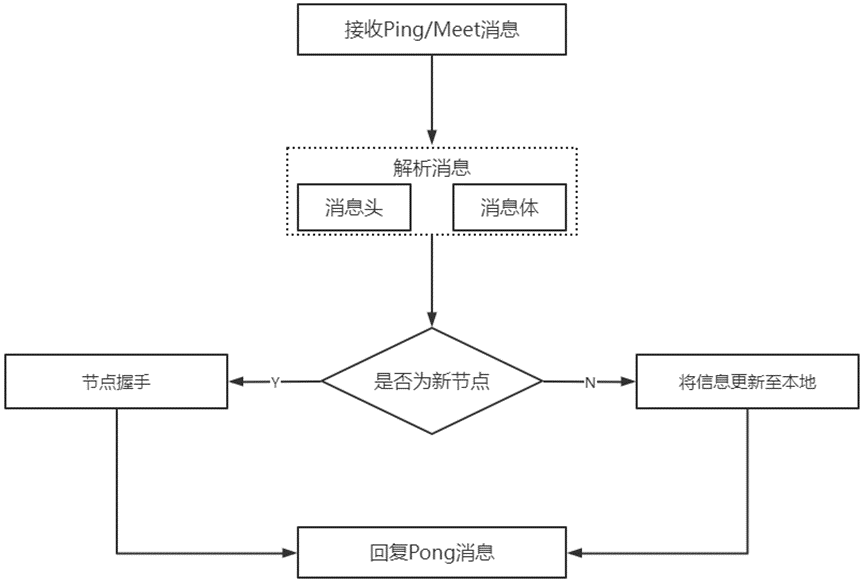
节点间发送消息的格式均为:消息头、消息体
(1)消息头:发送节点自身和信息相关信息
1)消息头的代码原型为“clusterMsg”结构体:
typedef struct {
char sig[4]; // 标识信号
uint32_t totlen; // 消息总长度
uint16_t ver; // 协议版本
uint16_t type; // 消息类型
uint16_t count; // 消息体包含的节点数量
uint16_t currentEpoch; // 当前发送节点的配置纪元
uint16_t configEpoch; // 主节点的配置纪元
uint16_t offset; // 复制偏移量
char sender[CLUSTER_NAMELEN]; // 发送节点的节点ID
usigned char myslots[CLUSTER_SLOTS/8]; // 发送节点所负责的槽信息
char slaveof[CLUSTER_NAMELEN]; // 若发送节点为从节点,则记录节点ID
uint16_t port; // 对方端口号
uint flags; // 标识发送节点(区分主从节点和是否已下线)
unsigned char state; // 发送节点所处的集群状态
unsigend char mflags[3]; // 消息标识
union clusterMsgData data; // 消息内容
} clusterMsg;
(2)消息体:发送节点自身状态数据和集群1/10节点的状态数据
1)消息体的代码原型为“clusterMsgData”结构体:
union clusterMsgData {
struct { // Meet、Ping、Pong消息体
clusterMsgDataGossip gossip[1]; // Gossio消息结构数组
} ping;
struct { // Fail消息体
clusterMsgDataFail about;
} fail;
};
typedef struct { // 标识消息类型用于信息交换
char nodename[CLUSTER_NAMELEN]; // 节点ID
uint32_t ping_sent; // 最后一次向该节点发送Ping消息时间
uint32_t pong_received; // 最后一次接收该节点Pong消息时间
char ip[NET_IP_STR_LEN]; // 节点IP
uint16_t port; // 节点端口
uint16_t flags; // 节点标识(是否已下线,用于故障转移)
} clusterMsgDataGossip;
如:节点间接收消息后解析流程(Ping/Meet消息为例,其他同理)
节点选择
节点选择:节点通信时按照随机性和实时性选择节点进行通信
1)随机性:每秒随机选取5个节点,对其中最久未通信节点发送Ping消息
2)实时性:每100毫秒扫描本地节点列表,对其中最后一次Pong消息时间大于cluster-node-timeout/2的节点发送Ping消息
如:节点选择通信流程
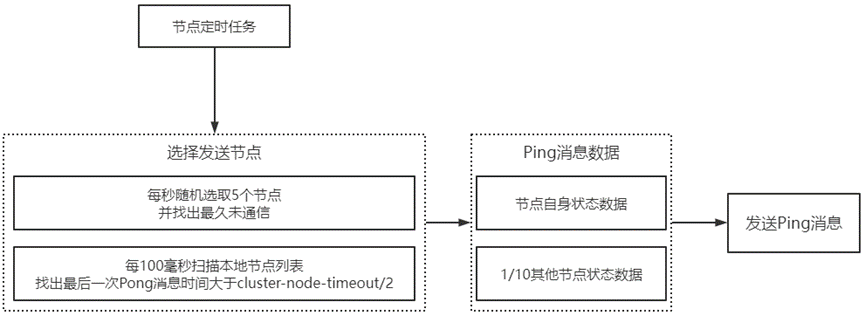
1)节点选择通信节点的数量受限制(兼顾实时交换信息和网络成本)
2)节点采用固定频率进行通信(定时任务每秒执行10次)
请求重定向
MOVED重定向
MOVED重定向:当前节点不能处理客户端的请求,返回正确节点
1)节点对于不属于负责键的命令只回复重定向反应(不会转发);
2)MOVED重定向内容格式:(error) MOVED 槽值 节点IP:端口
//客户端同时更新本地槽缓存
集群模式下Redis节点接收键相关命令的处理流程:
1)根据键名,计算出其对应的槽;
2)找出负责该槽的节点(若节点是自身,则处理该命令);
3)若不属于该节点则返回MOVED重定向错误,并返回正确的节点信息;
如:在其他节点的客户端中执行属于其他槽的键命令

//可在启动客户端时添加-c选项,其自动根据MOVED信息进行重定向
### ASK重定向
ASK重定向:迁移槽过程中,确保键命令的正常执行
1)本质:将对被迁移槽节点的命令重定向到新节点;
2)ASK重定向内容格式:(error) ASK 槽值 目标节点IP:端口
//客户端不会更新本地槽缓存
ASK重定向执行流程:
1)客户端根据本地槽缓存发送命令至源节点;
2)若槽已迁移至目标节点,则返回ASK重定向错误;
3)客户端自动根据ASK重定向信息,将命令发送至目标节点;
//在迁移槽时,客户端执行键已被迁移时默认触发ASK重定向
集群扩缩
集群扩缩:在不影响集群提供服务前提下,增/减节点
1)本质:槽和数据在不同节点间的移动;
扩容
扩容:集群中添加新节点
集群扩容流程如下:
(1)准备新节点并启动
1)新节点需与集群中其他节点配置保持一致(便于管理);
(2)将节点加入集群(任一节点和新节点握手)
1)若节点已属其他集群,加入后两个集群会合并(导致数据丢失和错乱)

//可使用redis-trib.rb add-node命令在加入前对节点进行检查
(3)迁移槽和数据,流程如下:
1)新节点准备导入槽(导入槽4096):

2)其他主节点准备导出槽:

//槽迁移过程中集群仍可提供服务
3)将源节点中槽映射数键迁移至新节点:

4)遍历通知所有主节点槽已属于新节点:
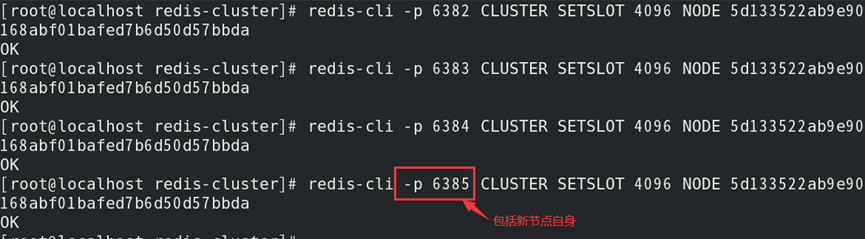
5)配置新节点的从节点:
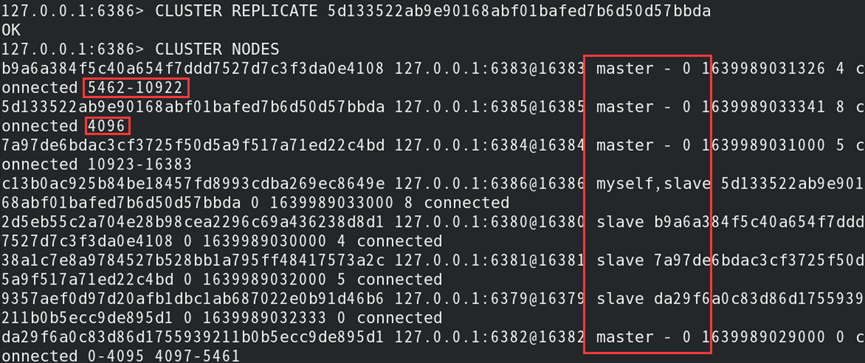
//实际迁移需确保每个主节点负责的槽数量大致相同
缩容
缩容:集群删除节点(先忘记后下线)
1)若删除的节点负责槽,则应先将槽迁移至其他主节点;
2)若删除的节点不负责槽或是从节点,可直接通知其他节点忘记该节点;
集群缩容流程如下:
1)将下线节点的槽迁移至其他节点;

2)遍历通知所有主节点槽已属于新节点:

3)使其他节点忘记被下线节点:
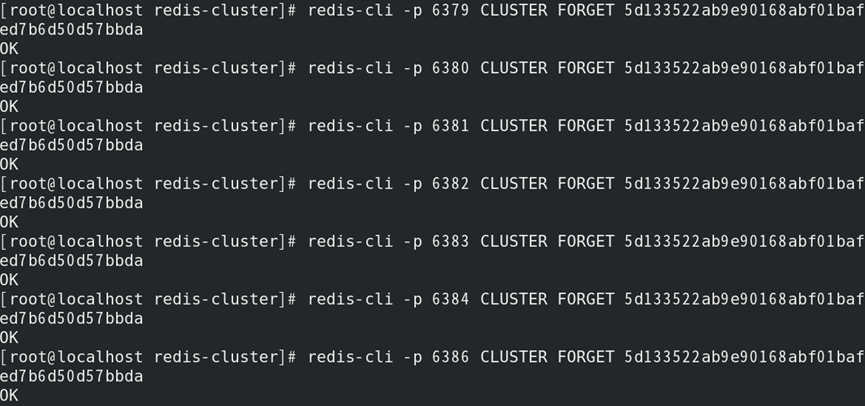
//务必在60秒内遍历所有节点执行该命令(否则将下线失败)
4)查看当前集群状态:
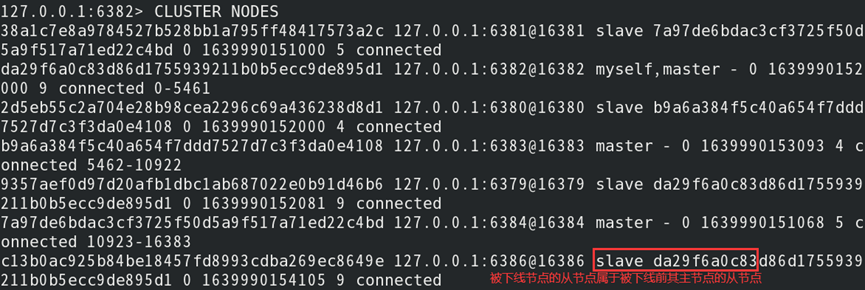
故障转移
故障转移:集群通过主观下线和客观下线实现节点的上/下线节点
1)主观下线:集群中某个节点判断另一个节点不可用(将其标为不可用状态)
2)客户下线:集群中多个节点判断另一个节点不可用(进行下线处理)
3)负责槽的主节点被下线时,需为该节点执行故障转移
主观/客观下线
主观下线:通过Ping/Pong消息发现不可用节点
1)主管下线并不会下线节点(因存在误判可能性);
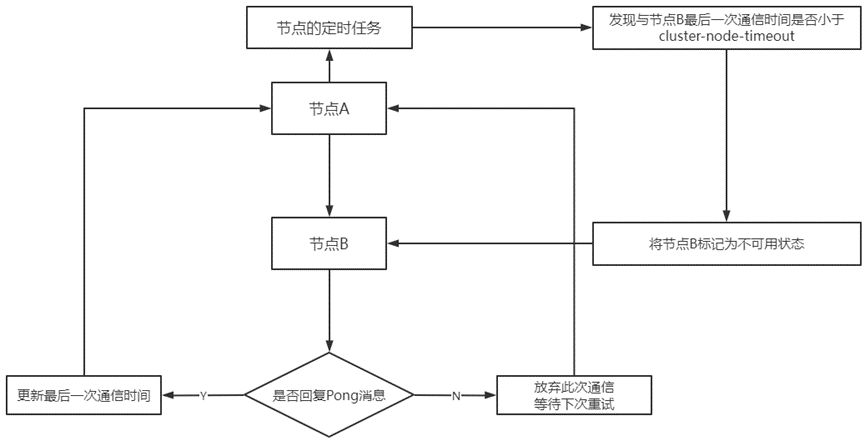
主观下线的执行流程:
1)每个节点定期向部分节点发送Ping消息;
2)节点需在限定时间内回复Pong消息,用于更新最后一次通信时间;
3)若最后一次通信时间大于cluster-node-timeout,则将其标记未不可用状态;
//若限定时间内未回复Pong消息,节点会无限重试发送Ping消息
如:主观下线执行流程图
客观下线:当集群半数以上主节点标记节点为不可用状态时,触发下线流程
1)当客观下线发生后,其标记状态会随之Ping/Pong消息在集群中传播;
2)只能是主节点参数节点下线的决策(从节点只复制其信息);
客观下线的执行流程:
1)Ping/Pong消息体中含有其他节点的pfail时,将该节点标记为不可用状态;
2)更新clusterNode内部下线报告列表(存储不可用节点的结构体);
3)根据多个主节点的clusterNode对主节点进行下线处理;
//若从节点发送pfail,则会被忽略
//每次接收到其他节点的pfali信息时,都会尝试触发客观下线
如:客观下线执行流程图
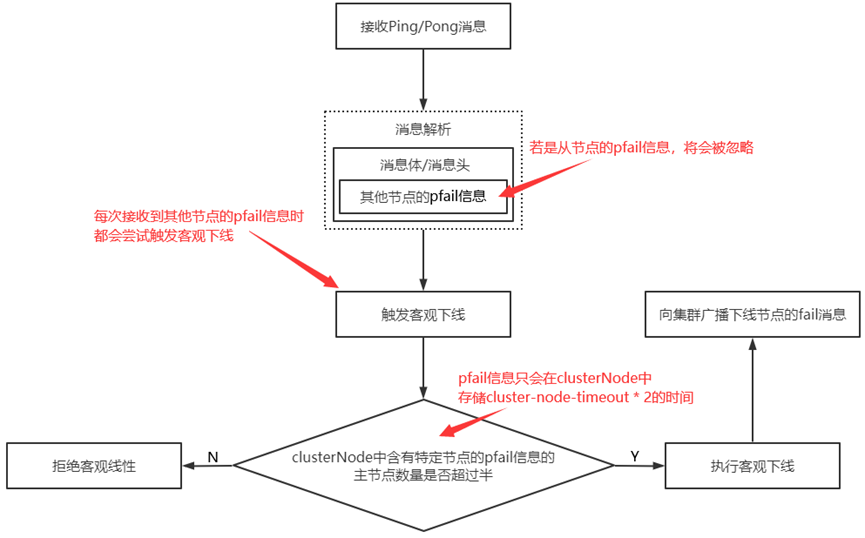
//超过限定时间则会清除clusterNode中节点的pfail信息
故障恢复
故障恢复:客观下线主节点后使用其从节点代替故障主节点负责槽
1)从节点通过定时任务发现主节点下线后,会自动触发故障恢复;
(1)资格检查:验证从节点是否有资格代替主节点
1)与主节点的断线时间低于 cluster-node-timeout * cluster-slave-validity-factor
(2)选举时间:区别多个具有资格从节点的优先级
1)复制偏移量最大的从节点优先级最高(延迟最低,优先执行)
2)默认触发选举时间为:客观下线后1秒
//通过延迟不同从节点的选举进行以区分优先级
(3)发起选举:从节点等待选举时间到后,准备选举
1)自增集群的全局配置纪元(每次发起选举均执行,以区分选举);
2)集群内广播选举消息,并记录已发送消息的状态;
//每个从节点在同一配置纪元内只能发起一次选举
(4)选举投票:持有槽的主节点投票从节点是否可成为主节点
1)持有槽的主节点只有一票(同一配置纪元内);
2)已投票的主节点会忽略其他从节点的选举投票请求(同一配置纪元内);
3)从节点只要获取 N/2 + 1张票即可成为主节点(N为集群所有主节点数量);
4)若cluster-node-timeout * 2时间内仍未获得足够票数,则本次选举作废;
//回复FAILOVER_AUTH_ACK消息即为该从节点投票
//故障主节点也算在投票总数N中
(5)替换主节点:获得足够票数后,执行如下替换主节点操作:
1)从节点取消复制(成为主节点);
2)执行clusterDelSlot操作撤销故障主节点负责的槽;
3)执行clusterAddslot操作将撤销的槽委托给从节点;
4)向集群广播Pong消息(通知所有节点,该从节点已成为主节点);
配置纪元:Redis节点中只增不减的整数,用于标识主节点的版本
1)每个主节点均维护个配置纪元(clusterNode.configEpoch);
2)集群也会维护个全局配置纪元(clusterState.currentEpoch);
3)当配置纪元重复时,节点ID更大者修改为全局配置纪元自增的结果;
4)当主节点操作冲突时,以配置纪元更大的一方为准;
5)配置纪元会随Ping/Pong消息在集群内传播;
//从节点会复制主节点的配置纪元;
手动转移
手动转移:通过执行特定命令实现手动故障转移(主从角色切换)
1)手动转移命令仅可在从节点客户端中执行;
2)手动故障转移从节点不做中断超时检查;
手动转移执行流程:
1)从节点通知主节点停止处理所有客户端请求;
2)主节点发送所有延迟复制数据给从节点,保证数据偏移量一致;
3)从节点立刻发起选举投票(无延迟,选举投票流程等同故障转移);
4)选举成功后断开复制(成为主节点),并广播Pong消息;
5)旧主节点变为新主节点的从节点,阻塞所有客户端请求;
//旧节点变为从节点后会向新主节点发哦是那个全量复制
手动转移相关命令:
(1)开启故障转移 CLUSTER FAILVER
(2)强制开启故障转移 CLUSTER FAILOVER FORCE
1)用于主节点宕机时,不确认复制偏移量(会丢失复制延迟数据)
(3)强制开启故障转移 CLUSTER FAILOVER TOKEOVER
1)用于集群中过半主节点宕机,从节点直接更新配置纪元成为主节点
//执行命令后客户端请求会有短暂的阻塞(但不会丢失数据)
常用命令
(1)获取集群相关信息:
(1)查看当前集群状态 CLUSTER INFO
(2)获取集群中所有节点状态 CLUSTER NODES
(3)返回指定主节点相关所有从节点信息 CLUSTER SLAVES 主节点ID
(4)返回执行命令节点的节点ID CLUSTER MYID
(4)返回指定从节点的主节点 CLUSTER SLAVES 从节点ID
(5)返回执行命令节点所负责的槽 CLUSTER SLOTS
(2)节点相关操作:
(1)节点握手(加入集群) CLUSTER MEET 对方IP 对方端口
1)本质:节点发送Meet消息至指定节点
(2) 使执行该命令的节点成为指定节点的从节点 CLUSTER REPLICATE 主节点ID
(3) 将执行该命令的节点所有配置刷新到磁盘配置文件中 CLUSTER SAVECONFIG
(4)从节点变为只读状态 READONLY
(5)从节点变为只读状态(仅能在从节点客户端中执行) READONLY
(6)关闭只读状态(仅能在从节点客户端中执行) READWRITE
(3)集群扩缩相关命令
(1)节点准备导入槽 CLUSTER SETSLOT 槽值 IMPORTING 节点ID
(2)节点准备导出槽 CLUSTER SETSLOT 槽值 MIGRATING 节点ID
(3)获取消导入/导出槽 CLUSTER SETSLOT 槽值 STABLE
(4)获取导出槽的N个键 CLUSTER GETKEYSINSLOT 槽 数值N
1)若已有键少于N,则立刻返回所有键
(5)通知所有主节点指定槽已属于节点 CLUSTER SETSLOT 槽 NODE 节点ID
1)遍历原因:防止较大配置纪元的节点不接受其他节点消息
(6)忘记指定节点(下线节点) CLUSTER FORGET 节点ID
1)需在每个节点的客户端中执行;
2)本质:将指定节点加入本地禁用列表中,不再与之进行信息交换;
//禁用列表有效期为60秒(该时间内未完成发送给全部节点,则下线失败)
(4)槽相关命令:
(1)将起始位至结束位的槽分配执行该命令的节点 CLUSTER ADDSLOTS 起始位 结束位
(2)移除执行命令节点所属的所有槽 CLUSTER FLUSHSLOTS
(3)计算键对应的槽 CLUSTER KEYSLOT 键名
1)若键名中使用“{}”,则仅使用大括号中内容计算槽(反之使用键名)
2)通过使多个键具有相同的槽,可使用批量操作(优化操作)
(4)获取指定槽映射的键数量 CLUSTER COUNTKEYSINSLOT 槽值
(5)循环输出槽映射的N个键 CLUSTER GETKEYSINSLOT 槽值 数值N
(5)手动转移相关命令:
(1)开启故障转移 CLUSTER FAILVER
(2)强制开启故障转移 CLUSTER FAILOVER FORCE
1)用于主节点宕机时,不确认复制偏移量(会丢失复制延迟数据)
(3)强制开启故障转移 CLUSTER FAILOVER TOKEOVER
1)用于集群中过半主节点宕机,从节点直接更新配置纪元成为主节点
redis-trib.rb
redis-trib.rb:Redis Cluster管理工具(Ruby实现)
1)内部通过调用Redis Cluster原生命令实现;
2)功能:创建集群、检测集群、槽迁移和节点均衡等操作;
//不建议使用redis-trib.rb工具操控Redis Cluster
部署redis-trib.rb工具流程:
1)配置Ruby语言环境:yum install -y ruby
2)安装rubygem redis依赖:gem install redis
3)将Redis安装目录下的redis-trib.rb复制到/usr/local/bin目录下
常用命令:
(1)创建集群,同时配置主从节点: redis-trib.rb create –replicas N 节点1 节点2 节点N
1)N代表从节点数量;
2)节点列表顺序代表节点的主从关系(先主后从)
3)节点必须是不包含任何槽/数据的节点,否则将拒绝执行;
(2)检测集群完整性: redis-trib.rb check 节点IP:端口
1)任一节点的IP和端口即可实现对集群的检测;
2)完整性:集群中所有槽均分配给主节点(有槽未分配则集群不完整);
(3)节点加入集群: redis-trib.rb add-node 新节点IP:新节点端口 节点IP:节点端口
| 选项 | 含义 |
|---|---|
| --slave | 以从节点加入 |
| --master-id | 主节点ID |
//在指定的节点IP(端口)中执行握手
(4)迁移槽: redis-trib.rb reshard 节点IP:端口 选项
| 选项 | 含义 |
|---|---|
| --from | 指定源节点ID (多节点ID使用逗号分隔,all代表所有主节点) |
| --to | 目标节点ID (仅能指定一个) |
| --slots | 迁移槽的总数量 |
| --timeout | 指定迁移键的超时时间 (默认值60000毫秒) |
| --pipeline | 每次批量迁移键的数量 (默认值10) |
| --yes | 自动输入确认 |
//节点IP必须为集群现存活节点的(用于获取集群状态信息)
(5)集群忘记节点: redis-trib.rb del-node 节点IP:端口 被下线节点ID

 浙公网安备 33010602011771号
浙公网安备 33010602011771号