

Go(Golang)_10_错误/异常
@
错误/异常
错误
错误(error):Go语言中通过普通值显示表示程序的问题
1)错误值的数据类型为error(内置接口类型,需导入errors包);
2)习惯上将错误值作为最后一个结果返回(通常为布尔类型);
3)Go语言中的错误控制流机制一般为if语句;
//宕机(异常)是因人为Bug导致,而错误是由其他环境因素导致
error接口的定义如下:
type error interface {
Error() string
}
普通错误
errors/errors.go中errorString结构体的数据结构定义:
type errorString struct {
s string
}
func (e *errorString) Error() string {
return e.s
}
创建普通错误的两种方式:
(1)静态(字符串):errors.New(“字符串”)
1)本质:创建errorString实例并赋值便返回;
2)errors/errors.go中New()的实现:
func New(text string) error {
return &errorString{text}
}
(2)动态(格式化):fmt.Errorf(“格式化内容”, 变量)
1)本质:内部调用Errors.New()和fmt.Sprintf()(errors.New()的再次封装)
2)生成错误时需遍历所有字符(无须格式化时建议使用errors.New())
3)fmt/fmt.go中Errorf()的伪代码:
func Errorf(format string, a ...interface{}) error {
return errors.New(Sprintf(format, a...))
}
如:通过errors.New()和fmt.Errorf()函数输出错误信息
1)编写程序;
package main
import (
"errors"
"fmt"
)
func main() {
err1 := errors.New("this is New Error")
if err1 != nil {
fmt.Println(err1)
}
const name, id = "Errorf", 2
err2 := fmt.Errorf("this is %s ID is %d", name, id)
if err2 != nil {
fmt.Print(err2)
}
}
2)运行结果;

链式错误
链式错误:可链接多个普通错误,并支持链式拆解和分析
1)基于wrapError结构体实现;
2)wrapError结构体的数据结构如下:
type wrapError struct {
msg string // 存储上下文信息和err.Error()
err error // 存储原error
}
创建链式错误的方式:fmt.Errorf()和 verb动词%w
1)每个fmt.Errorf()方法中只能出现一次%w(只能包含一个普通错误);
2)verb动词%w只能匹配实现error接口的参数;
3)fmt/fmt.go中Errorf()的实现如下:
func Errorf(format string, a ...interface{}) error {
p := newPrinter()
p.wrapErrs = true
p.doPrintf(format, a) // 解析参数,若发现%w则提供合法的error参数
// 并将error放到p.wrappedErr成员中
s := string(p.buf)
var err error
if p.wrappedErr == nil { // 若无%w,则生成普通错误
err = errors.New(s)
} else { // 存在%w,则生成链式错误
err = &wrapError{s, p.wrappedErr}
}
p.free()
return err
}
//自定义error类型需实现Unwrap()函数才可成为链接错误;
errors包中用于解析链式错误的函数:
1)获取相对本层的上层错误信息
func Unwrap(err error) error
//可嵌套使用,以获取多层链接中的错误信息
2)检查链式错误err中是否包含target普通错误
func Is(err, target error) bool
//内部调用Unwrap()方法进行逐层解析匹配,发现相等立刻返回ture
3)检查链式错误err中是否包含target数据类型
func As(err error, target interface{}) bool
//内部调用Unwrap()方法进行逐层解析匹配,发现相等立刻将err值写入target
使用链式错误的建议:
1)等值检查使用errors.Is()替代;
2)类型断言使用errors.As()替代;
3)自定义error类型实现Unwrap()函数;
4)创建错误时,尽量使用链式错误(存储更多信息);
宕机
宕机(panic):程序中的特殊对象,代表当编译/运行程序时出现的问题(异常)
1)程序发生宕机时,默认会终止运行(并留下一条日志信息);
2)goroutine因宕机退出时会显示一个函数调用的栈跟踪信息;
3)程序也可从宕机状态恢复至正常运行状态;
宕机的定义格式:panic(参数)
1)可接收任意数据类型作为参数;
2)panic会触发当前goroutine内的所有defer语句;
3)当前作用域无法解决panic时,会将panic抛给上层(同样触发defer语句);
panic须知:
1)panic会递归执行本goroutine中所有的defer语句;
3)本goroutine中的defer语句处理完成后就会直接结束程序;
4)panic不会触发和处理其他goroutine的defer语句(除上层外);
4)panic过程中再次panic时会终止处理defer语句,开始处理另外的panic;
如:在主函数和延迟函数中分别panic,验证恢复
1)编写程序;
package main
import (
"fmt"
)
func main() {
defer func() {
if err := recover(); err != nil {
fmt.Println(err)
} else {
fmt.Println("fatal")
}
}()
defer func() {
panic("defer panic") // defer中支持再次panic
}()
panic("normal panic")
}
2)运行结果;

//先运行的panic会被后续panic顶替
实现原理
runtime/runtime2.go中panic的数据结构定义:
type _panic struct {
argp unsafe.Pointer // defer的参数空间地址
arg any // panic的参数
link *_panic // 指向前一个panic(嵌套时使用,以串成链表)
pc uintptr // 该panic被跳过时的返回地址
sp unsafe.Pointer // 该panic被跳过时defer调用指针
recovered bool // 该panic是否已被recover
aborted bool // 该panic是否终止(产生新的panic)
goexit bool // 该panic是否为runtime.Goexit()产生的
}
1)panic()函数的本质是调用runtime.gopanic()函数产生_painc实例
2)runtime.gopainc()函数的主要任务是消费goroutine中的defer链表
3)runtime.Goexit()函数也可产生_panic实例(但不可recover)
4)所有_panic实例会被存储到goroutine的gp._panic链表中
消费defer时触发新panic,会调用runtime.gopanic()函数以产生新_panic实例
1)新_panic实例会将旧_panic实例的aborted标为ture;
2)旧_panic实例会defer消费的控制权转交至新_panic实例;
3)新_panic实例通过_defer实例中的_panic字段决定是否进行消费;
//_panic每消费个_defer实例都会将其started字段标为true,同时记录本身地址
恢复
恢复(recover):解决程序中触发的宕机(捕获并处理异常)
1)recover必须直接位于derfer语句或延迟函数中执行(否则无法捕获宕机);
2)panic后再恢复是不可靠的(变量状态可能被改变或丢失);
恢复的定义格式:recover()
1)终止goroutine的panic状态,并返回panic参数值(若无panic,返回nil);
2)程序默认继recover()函数后继续运行(不会返回到宕机点继续);
3)函数发生recover时虽不会运行到的return语句,但仍会返回值;
| 返回值类型 | 返回值 |
|---|---|
| 匿名返回值 | 对应数据类型的零值 |
| 命名返回值 | recover前已存在的值 |
如:程序中触发宕机并进行恢复
1)编写程序;
package main
import (
"fmt"
"time"
)
func test() {
defer func() { // 必须先声明defer,否则抛出的panic导致无法执行到defer
fmt.Println("defer Start")
if err := recover(); err != nil {
fmt.Println(err) // 成功捕获panic,从此处继续
}
fmt.Println("defer end")
}()
for {
fmt.Println("func begin")
a := []string{"A", "B"}
fmt.Println(a[3]) // 此处进行越界访问
panic("WRONG") // 抛出panic
fmt.Println("func end") //由于panic,导致该段后的代码无法执行
time.Sleep(1 * time.Second)
}
}
func main() {
test()
fmt.Println("End")
}
2)运行结果;
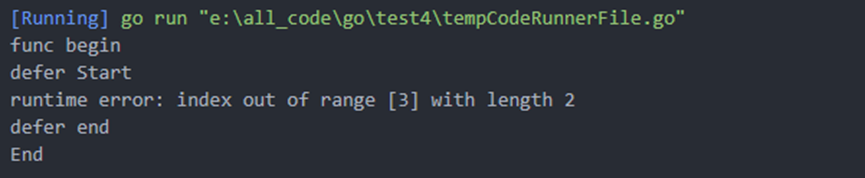
//若不对panic进行recover,则panic会先结束本goroutine进而结束整个程序
实现原理
runtime/panic.go中recover的数据结构定义:
func gorecover(argp uintptr) interface{} {
gp := getg() // 从goroutine数据结构中获取_panic链表
p := gp._panic // 获取当前_panic实例(若未发生panic,则为nil)
// recover的限制条件
if p != nil && !p.goexit && !p.recovered && argp == uintptr(p.argp) {
p.recovered = true
return p.arg
}
return nil
}
1)recover()函数的本质是调用runtime.gorecover()函数;
2)runtime.gorecover()函数的参数是延迟函数的地址;
3)嵌套执行recover会导致其接收不到参数;
源码中获知panic可被recover的4个条件:
1)必须存在_panic实例;
2)_panic实例非runtime.Goexit()函数生成的;
3)_panic实例并未被恢复(已被其他recover恢复);
4)recover()函数是直接位于defer语句或延迟函数中;
//避免调用第三方API时其内部的recover将panic没收(非预期)
