
Shell_02_文本三剑客
@
cut
cut命令:以字段为单位对数据进行操作
指令格式:cut 选项 文件路径
| 选项 | 含义 |
|---|---|
| -d | 指定数据的分隔符 |
| -f | 指定字段显示 |
| -c N | 指定N个字符为1个单位显示 |
1)-d和-f选项一起使用才有意义(只有指定数据的分隔符,数据才能分段)
2)-c选项后跟的数值的“-”在不同地方有不同含义
如:显示PATH变量路径中的第五个路径

如:以不同字符单位显示test1.txt文件内容

sed
sed命令:以行为单位对数据进行替换、删除、新增、选取等功能
指令格式:sed 选项 ‘操作’ 文件路径
1)选项为可选项,但操作必须有;
2)sed命令超过两个以上的操作时,需添加-e选项;
3)操作必须用两个单引号括起来,且多个操作之间使用“;”分隔;
| 选项 | 含义 |
|---|---|
| -n | 仅输出被sed处理过的行 |
| -e | 在命令提示符界面下进行sed操作 |
| -f | 将sed的操作写入一个文件 |
| -r | 使用扩展正则表达式语法 (默认是基础正则表达式语法) |
| -i | 直接修改文件内容 (默认是仅读取文件后输出到终端) |
| 操作 | 含义 |
|---|---|
| s | 替换/删除字符串 (通常配合正则表达式使用) |
| y | 替换字符 |
| i | (上一行)插入 |
| a | (下一行)插入 |
| c | 替换行 |
| d | 删除行 |
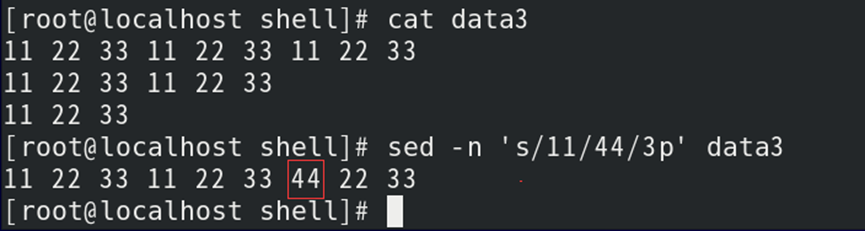
| p | 打印 (通常配合-n选项一起使用才有意义) |
替换字符串
s操作:替换数据流中指定的字符串
1)格式:s/原字符串/新字符串/标识
2)标识分为(p和w可用于其他操作):
| 标识 | 说明 |
|---|---|
| g | 数据流中所有出现原字符串的都被替换 |
| p | 打印出字符串被操作后所在的行 |
| w 文件路径 | 将操作后的结果写到指定文件 |
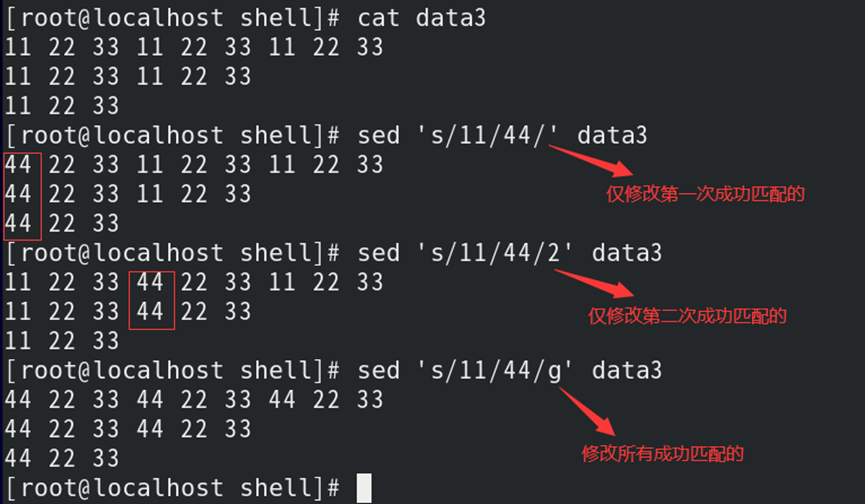
| 数值N | 指定该字符串在该行中成功匹配的第N次,才进行替换 |
3)默认仅替换成功匹配的第一次字符串;
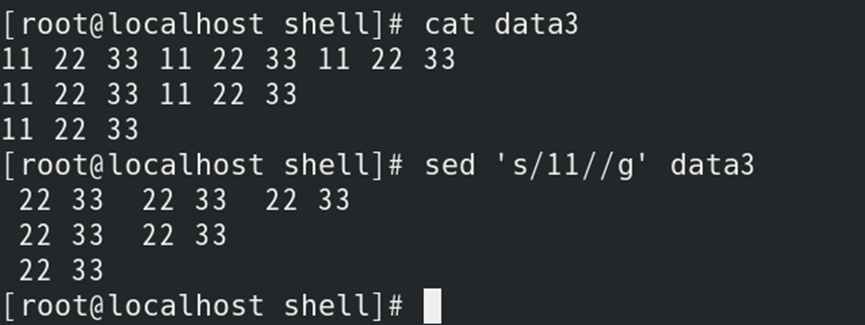
4)若新字符串为空,则实现删除原字符串的功能;
如:替换指定字符串
如:仅打印出被sed命令替换的行
如:通过s操作删除指定字符串
y操作:替换数据流中单个字符
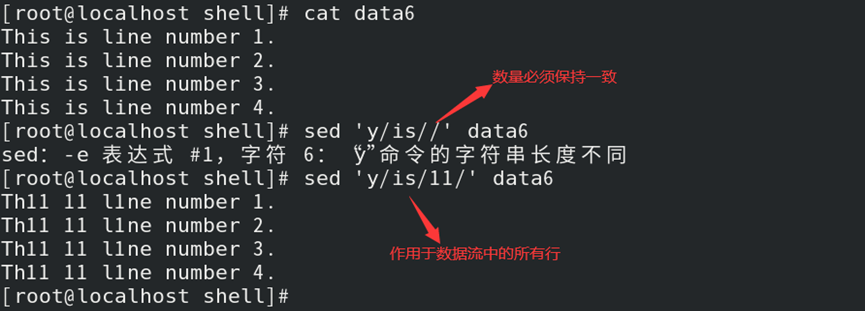
1)格式:y/原字符/新字符/
2)原字符数量需和新字符数量保持一致;
3)默认作用于数据流中所有字符串(无法通过寻址指定范围)
如:替换指定字符
寻址
行寻址(Line Addressing):指定sed命令的操作的作用范围行
1)sed命令的操作默认作用在所有数据行;
2)行寻址分为:数字寻址、文本寻址
(1)数字寻址
1)sed默认从第一行数据分配行号1(包括空行);
2)数字寻址分为:行、行区间
3)数字寻址格式:‘数值和操作’
//指定行区间时,多个数值之间使用“,”分隔(区间包含数值本身)
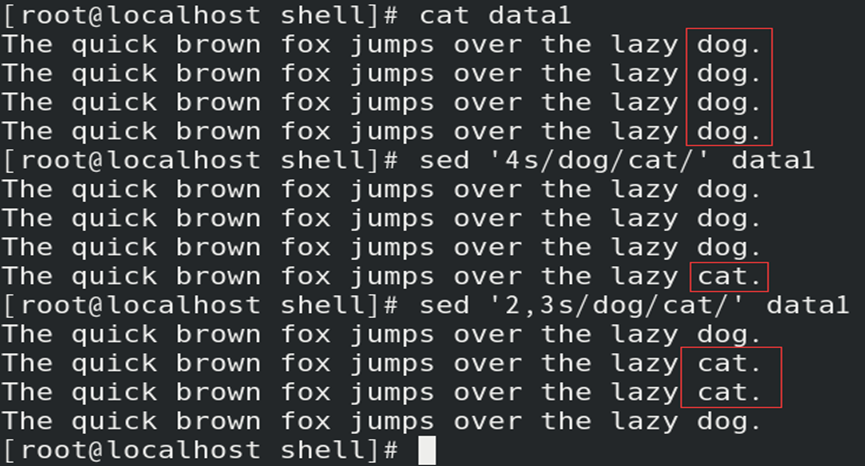
如:通过数字寻址,替换指定数据
(2)文本寻址
1)选取含有指定字符串的行;
2)文本寻址格式:‘/字符串/操作’
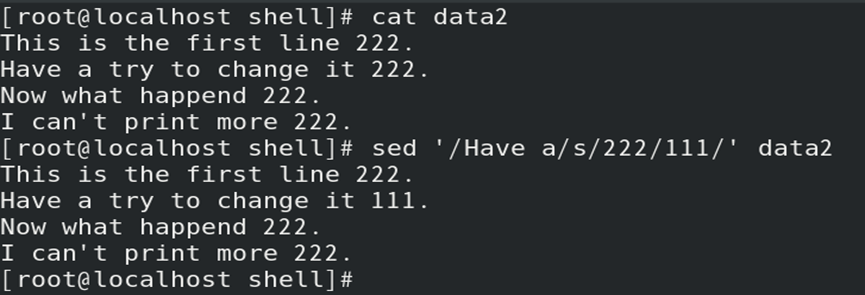
如:通过文本寻址,替换指定数据
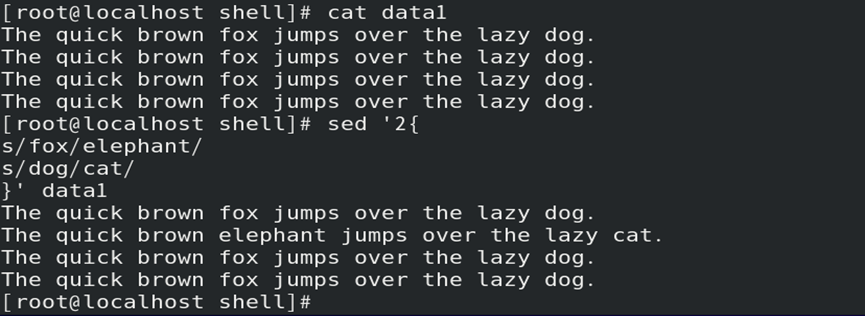
(3)在同一个寻址下执行多个操作时,操作需分行指定
//也可写在同一行,但需多次指定寻址且使用“;”分隔操作
如:指定行中,同时替换多个数据
删除
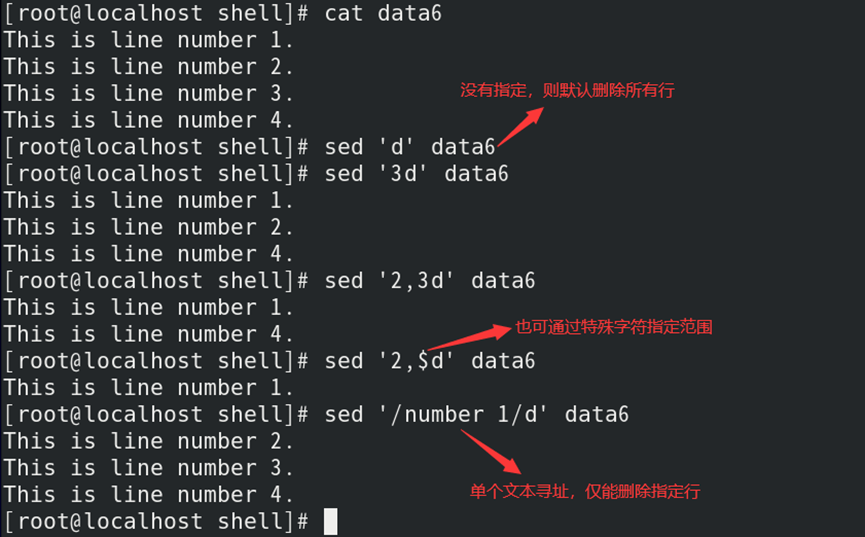
d操作:删除数据流中指定行
1)格式:匹配格式d
2)若不指定字符串,则默认删除所有行的字符串;
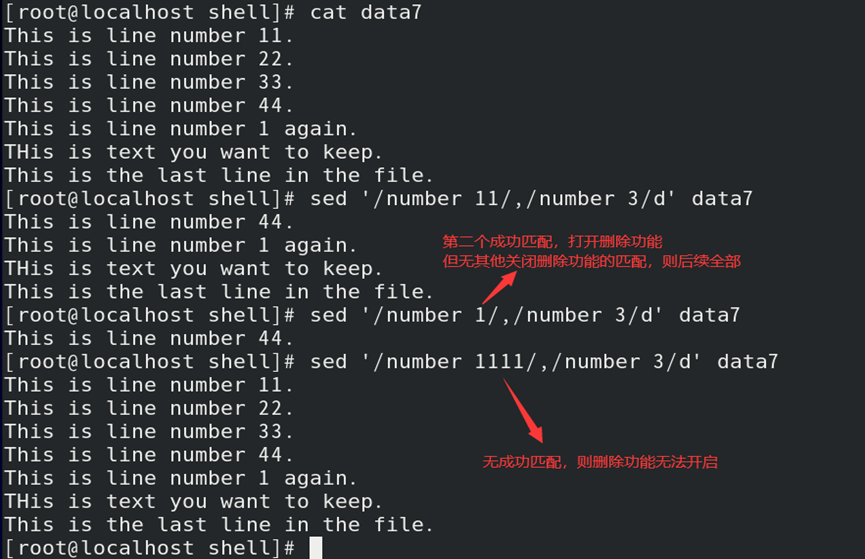
3)使用两个文本寻址,可实现删除功能的开启和关闭;
//匹配到第一个文本寻址时开启删除功能,匹配到第二个时则关闭
如:删除指定行
如:通过两个文本寻址,实现删除功能的开启和关闭
插入
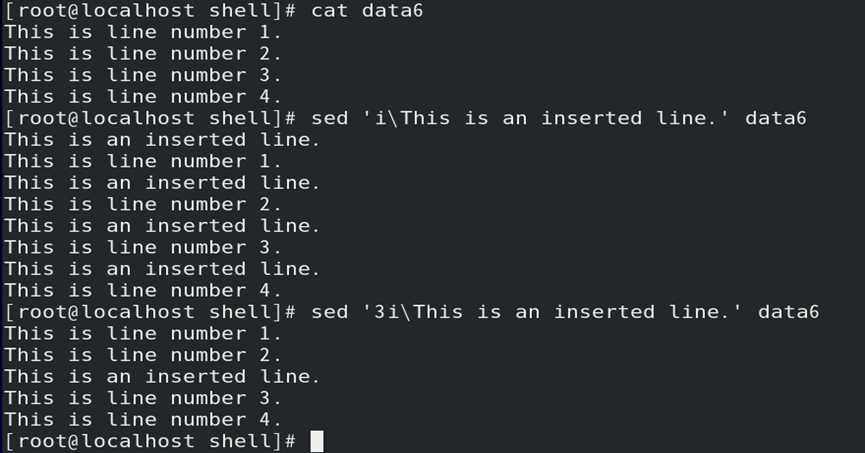
i操作:在数据流中指定行的上一行插入一行数据
1)格式:寻址i\插入数据
2)i操作须配合寻址,且不能使用行区间寻址;
//若不指定寻址,则默认在所有行的上一行插入指定数据
3)a操作与i操作相同(区别在于:在指定行的下一行插入);
如:读取data6文件数据流中,第3行的上一行插入指定数据
替换行
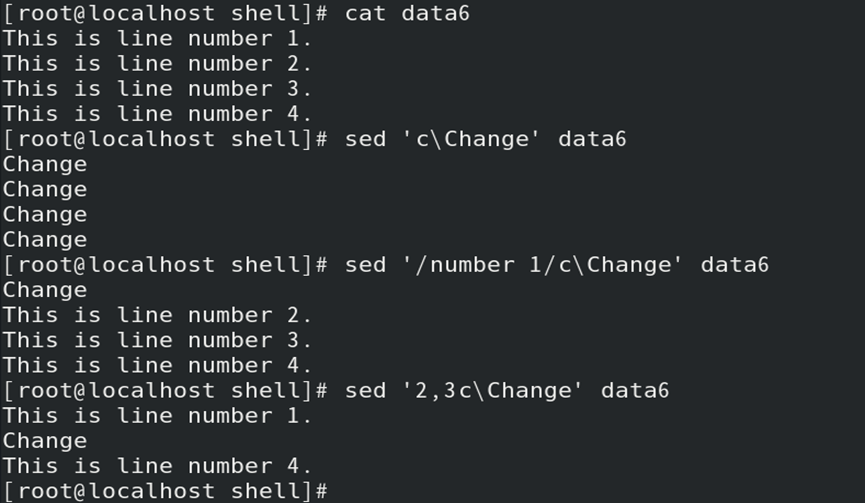
c操作:新行替换数据流中指定行
1)格式:寻址c\新行
2)c操作须配合寻址(若行区间寻址,则区间替换为新行);
//若不指定寻址,则默认替换数据流中的所有行
如:新行替换指定行
gawk
gawk程序:Unix中awk程序的GNU版本,有以下功能
1)可定义变量以存储数据;
2)使用算术和字符串操作符处理数据;
3)使用结构化编程概念为数据处理增加处理逻辑;
4)通过提取数据文件中的数据元素,将其格式化并输出;
gawk命令:每一行的字段为单位对数据进行替换、删除、新增、选取等功能
指令格式:gawk 选项 ‘关键词1{操作1} 关键词2{操作2}’ 文件路径
| 选项 | 含义 |
|---|---|
| -F 字符 | 指定字段的分隔符 |
| -f 文件路径 | 指定存储gwak操作的文件 |
| -v 变量名=值 | 定义变量和变量值 |
| -mf | 指定数据流中最大处理字段数 |
1)gawk以行为进行单位,以字段为处理单位;
2)gwak中每个字段的内置变量为:
| 变量名 | 说明 |
|---|---|
| $0 | 代表整行数据 |
| $1 | 代表第1个字段 |
| $2 | 代表第2个字段 |
| $N | 代表第N个字段 |
3)gawk其他内置变量
| 变量名 | 含义 |
|---|---|
| NF | 每一行的字段总数 |
| NR | gawk所处理的是第几行数据 |
| FS | 输入字段的分割符 (默认为空格) |
| RS | 输入数据行的分隔符 |
| OFS | 输出字段的分隔符 |
| ORS | 输出数据行的分隔符 |
//内置变量在gawk内使用时,不需在前添加变量符号“$”
4)gawk中3个关键词:BEGIN(最先执行)、pattern、END(最后执行)
//指定分割字符时,需使用BEGIN关键词,否则gawk还没有更换分割字符时,其他操作就已经开始处理
//默认省略pattern关键词(使用较少)
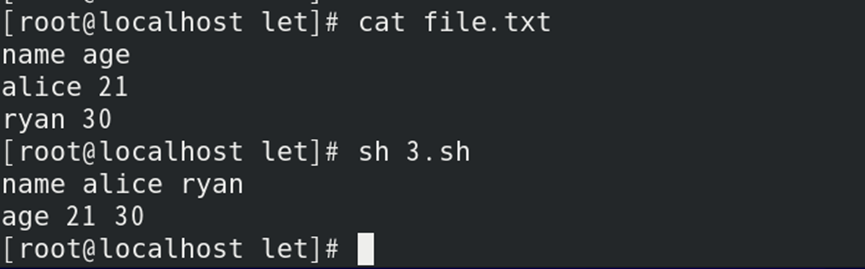
如:格式化输出

//当一个操作中有多条命令时,需使用“;”分隔
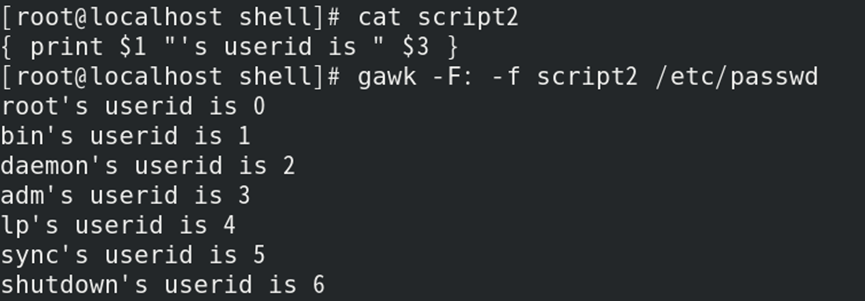
如:通过调用存储gwak操作的文件,输出/etc/passwd文件的用户名和UID
如:查询/etc/passwd文件内UID小于10的用户,并通过awk格式化输出

//gawk可使用逻辑运算实现操作选择,且awk和gawk通用
如:通过gawk格式化输出
1)编写3.sh脚本文件
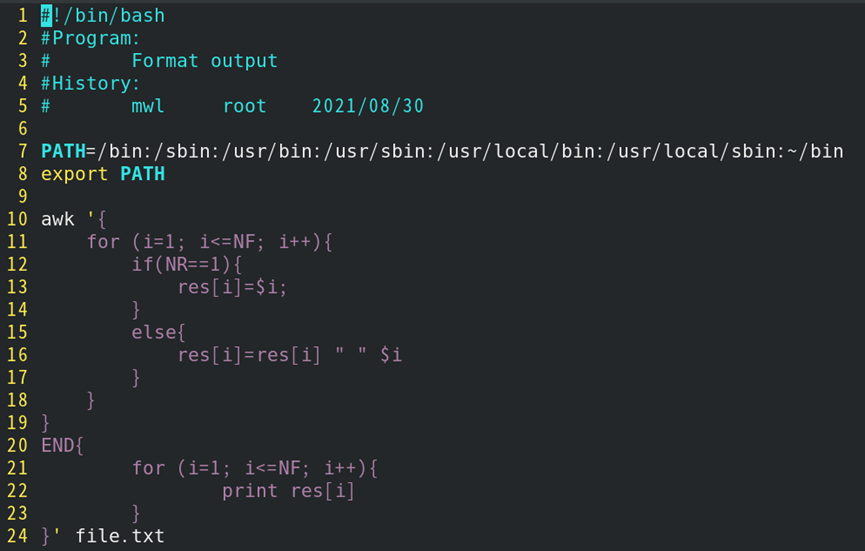
2)调用3.sh脚本文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号