数据库索引及结构
1 什么是索引
索引是一种特殊的文件,它包含着对数据表中所有记录里的引用指针
索引是一种数据结构。数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。
更通俗的来讲,索引就相当于目录。
索引的优点
- 可以大大加快数据的检索速度
- 通过使用索引,可以再查询的过程中,使用优化隐藏起,提高系统的性能
索引的缺点:
- 时间方面:创建和维护索引需要耗费时间。对表中的数据进行增、删、改时,索引需要动态的维护,会降低执行的效率
- 空间方面:索引需要占用物理空间
2 索引的类型
-
主键索引:数据列不允许重复,不允许为NULL,一个表只能有一个主键
-
唯一索引:数据列不允许重复,允许为NULL的值,一个表允许多个列创建唯一索引
可以通过
ALTER TABLE table_name ADD UNIQUE (column);创建唯一索引
可以通过ALTER TABLE table_name ADD UNIQUE (column1,column2);创建唯一组合索引
- 普通索引:基本的索引类型,没有唯一性限制,允许为NULL值
可以通过
ALTER TABLE table_name ADD INDEX index_name(column);创建唯一索引
可以通过ALTER TABLE table_name ADD INDEX index_name(column1,column2);创建唯一组合索引
3 索引的数据结构
3.1 哈希索引
哈希索引类似于数据结构中的哈希表(散列表)。当我们在数据库中使用哈希索引时,主要是通过Hash算法,将数据库字段数据转换成定长的Hash值,与这条数据的行指针一并存入Hash表中的位置;如果发生哈希碰撞,则在对应Hash键下以链表的形式存储。
但我们都知道,Hash值是一个无序的值,所以它无法进行范围查找,也不能利用Hash值去做排序。还有,在Hash碰撞的情况下,需要沿着链表去一个一个的查找,这样降低了查找的效率。
3.2 B+树索引
既然哈希索引由于其无序的特性,使其无法应对范围查找、无法排序,且存在哈希碰撞时效率下降的问题,而树的结构解决了这个问题——它的数据有序排列,且支持范围查询。MySQL中使用的是B+树作为索引的数据结构。为了明白为什么要使用B+树索引,我们需要先从平衡二叉树说起
(1) 平衡二叉树
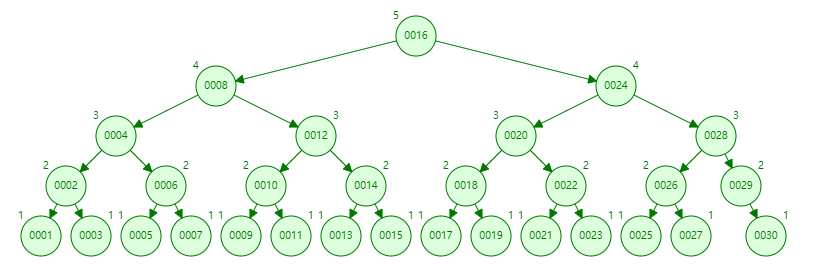
平衡二叉树相比起哈希索引,很好的解决了范围查找的问题,但平衡二叉树仍然存在两个问题:
1、在大量数据的情况下,树的高度会很大。如图所示的平衡二叉树,一共存入了30个数据。可以看到,整棵树一共有5层,而在最坏的情况下,需要向下查询5次才能知道想要的数据。
2、在范围查找时,存在回旋查找的问题。比如在上面的图中要查找大于25的数,要先定位到25,然后再回到26->27,再回到28->29->30,然后把这些数据拿出来。假如要查询的数据非常多,那么在平衡二叉树的结构中回旋查找的效率是非常慢的。
(2) B树
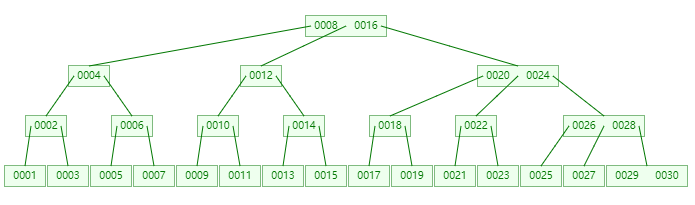
可以看到,同样是在插入30个数据的情况下,B树要比平衡二叉树更矮。
不同于平衡二叉树,B树的每个节点最多可以存储n个有序的数据,同时还存储着最多n+1个指向下一级节点的指针。以上图为例,每个节点最多可以存储2个数据,节点中最多有3个指向下一级节点的指针。以下面这个子树为例:
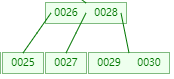
根结点中两个数据是26和28,比26小的数据存储在最左边的指针指向的结点,介于26和28的数据存储在中间的指针指向的结点,大于28的数据存储在最右边的指针指向的结点
相较于平衡二叉树,B树更矮,一个结点内能存储更多的有序数据,因此在大量数据的情况下,不需要向更深处遍历数据。
但B树在范围查找方面有着和平衡二叉树相同的问题:如果要查找比25大的数据,B树要先定位到25,再经历26->27->28->29、30,在数据量大的情况下同样要消耗大量时间。
(3) B+树
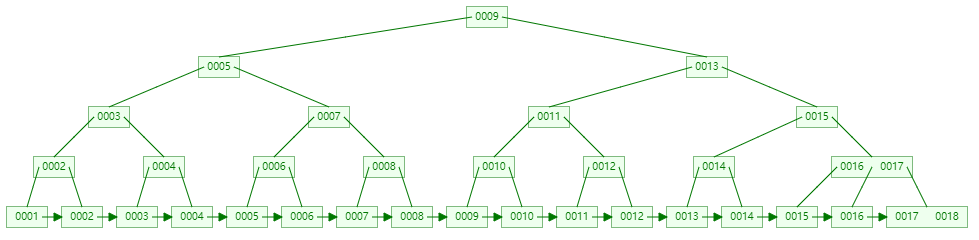
为了解决在范围查找时,出现的回旋查找的问题,产生了B+树的结构。相比起B树,B+树的非叶子结点仅具有索引的做引,不用来存储数据。数据全部存储在叶子结点中。叶子结点之间通过指针相互连接在一起,有序排列。
当使用B+树查找数据时,假如查找8,先从根结点9开始,向左找到结点5,再向右找到结点7,再向右找到结点8,最后找到叶子结点8.
当使用B+树进行范围查找时,假如找到比8大的数据,就先找到叶子结点8,然后向右遍历,就能找到所有比8大的结点,其查找效率要比B树更高

 浙公网安备 33010602011771号
浙公网安备 33010602011771号