你的计算机也可以看懂世界——十分钟跑起卷积神经网络(Windows+CPU)
众所周知,如果你想研究Deep Learning,那么比较常用的配置是Linux+GPU,不过现在很多非计算机专业的同学有时也会想采用Deep Learning方法来完成一些工作,那么Linux+GPU的环境就有可能会给他们带来一定困扰,我写这篇文章就是为了让这些同学可以不用去装Linux系统,不用去涉及GPU,就可以基于Caffe框架跑出一个简单的神经网络。
CNN基础知识:https://zhuanlan.zhihu.com/p/22038289?refer=intelligentunit(没基础的还应该另外了解一些神经网络算法的基础知识,例如前馈传递,BP算法等,有基础的也推荐再通过这个链接巩固一番,以下的文章会假设你对于CNN有比较全面和扎实的理解)
所需系统环境:windows7 sp1及以上系统,win7 sp1以下的会不会有什么错误我不知道,对了,是64位系统哦~
其他环境:Visual Studio 2013,cygwin 2.871(其他版本应该也可以,主要是用来在windows系统上模拟一个非常简易的linux环境,因为应用上只会用到一些很基础的命令,所以早一点的版本也无所谓)
Windows版Caffe框架:https://github.com/Microsoft/caffe
首先,需要将windows版本的Caffe框架下载到本地,随便下到哪都行,然后随便解压缩到哪都行,我解压完之后,Caffe框架的根目录就是H:\caffe-master\caffe-master。解压完之后,我们可以很明显地发现,这个框架还是一块未编译的“生肉”,是不能直接使用的,所以我们需要利用VS2013对其进行编译,但是在此之前,还有一个步骤,因为我们是小穷逼,我们没有动辄上万的GPU,但是贾大神所在的土豪实验室有用不完的GPU,所以这里默认的还是GPU模式的框架,我们需要对这一点进行修改,具体方式就是修改根目录中windows文件夹中的CommonSettings.props.example文件,具体修改方式是:
一、将该文件重命名为CommonSettings.props;
二、将该文件中的
<CpuOnlyBuild>false</CpuOnlyBuild>
<UseCuDNN>true</UseCuDNN>
改为
<CpuOnlyBuild>true</CpuOnlyBuild>
<UseCuDNN>false</UseCuDNN>
至于这里面的CuDNN是什么,之后会提到,现在先不用了解~
三、保存该文件。
在将框架改为CPU模式之后,就可以双击打开windows文件夹中的Caffe.sln文件,然后在VS2013中点击最上方的生成->重新生成解决方案即可,需要注意的是,进行这一步之前最好将Debug模式改成Release,就像这样。

经过一段时间的编译,在VS2013下端的显示台上会显示生成成功的信息,这时候这个框架就编译完成了,而生成的可执行文件caffe.exe的位置在根目录中的Build\x64\Release之中,同时还会生成一大堆的依赖包和各类库,这里各位先不用在意,今天的任务主要会和caffe.exe发生接触。
编译好了框架之后,可以说是万事俱备,只欠数据集和网络模型了,在第一次的尝试中,CSDN的卜居大神所推崇的使用Yann LeCun大神(我习惯于说成杨乐村大神)提出的LeNet-5网络模型来进行对MNIST数据集的学习是非常适合的。
MNIST数据集是一个手写数字的数据库,所以可想而知,这次训练的目的是让你的计算机学会“看懂数字”。
MNIST数据集在哪里获取呢?Caffe框架已经为你想到了这一点,所以在H:\caffe-master\caffe-master\data\mnist中的get_mnist.sh脚本就是用来帮你下载这个数据集的,理论上,这个脚本的运行需要Linux的环境支持,但是我们现在用的是windows环境,怎么办呢?很简单,还记得之前所说的cygwin吗?没错,就用它!有关cygwin的安装和配置可以看看这个http://www.cygwin.cn/site/install/。
现在,你已经安装好了cygwin,并已经将其双击打开,只需要在这个黑框框里如下输入,然后回车,就会为你自动下载MNIST数据集(注意,如果不FQ是没有办法下载的,推荐一下我一直用的Psiphon3,这个名字一搜就能搜到,你们懂的)。

(忽略我的电脑名字是Celia,用的实验室的机器,懒得改了。。。)
这时候,你会发现在data\mnist文件夹中出现了
,也就是说,MNIST数据集已经成功地下载下来了。
那么这个数据集是不是可以直接用了呢?答案是不能。为什么呢?因为到这一步为止,我们的数据集还只是二进制文件,需要转换为lmdb文件才可以被Caffe框架识别,所以这其中还有一个转换的过程,对于windows用户来说,这个转换是比较烦的,以至于我自己也没有试过,但是由于我之前一直在Ubuntu系统中使用这个框架,所以我们可以采用如下的两种方法:
一、在Ubuntu系统中,首先cd进Caffe框架的根目录,之后只需通过简单的一行命令:
./examples/mnist/create_mnist.sh
即可完成数据的转换工作,那么因为这里我们不希望去使用Ubuntu,所以我比较推荐第二种方法。
二、去网上找资源。。。MNIST数据集的lmdb文件在网上是容易找到的,这里我也用我的网盘分享了一份,http://pan.baidu.com/s/1o86O7Xo。
假设你是从我的网盘下载的,那么现在只需要把这个下载下来的文件解压,然后把解压出来的mnist_train_lmdb以及mnist_test_lmdb文件夹放到examples/mnist中即可。
至于我们使用的LeNet-5模型,眼尖的同学应该已经发现了,早就已经存在于examples/mnist文件夹中了。
现在,我们有了框架,有了数据集,有了模型,那么就快要大功告成了。接下来,只需要在windows自带的cmd命令行界面中如下输入:

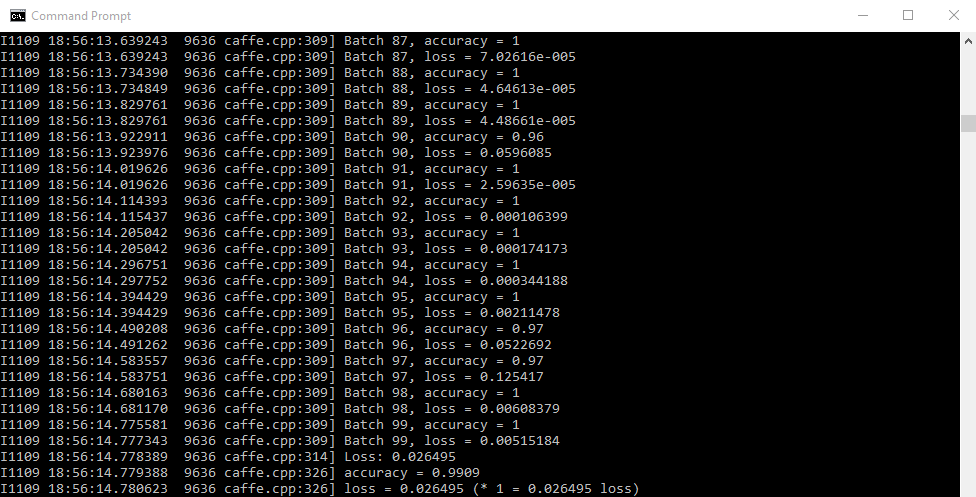
之后按下回车,就大功告成啦,只需在黑框框中不断跳文字的过程中静静地等待即可。。。这个训练时间主要和你的计算机的配置有关,训练完成时的状态是这样的:

可以看到,最终的正确率达到了惊人的99.09%,而损失也降到了0.026495。通过训练之后生成的权重也保存在了mnist文件夹中的lenet_iter_10000.caffemodel之中。这时候,我们可以通过训练好的模型来对测试集进行测试。测试所需代码如下:

最后,我们可以发现这个模型在测试集上的正确率达到了非常惊人的程度。
这样,我们就可以说,你的计算机上成功地诞生了神经网络,而你的计算机同时也成功学会了“认识数字”。
备注:本人非常乐意分享我的文章,转载请注明我的博客地址:http://www.cnblogs.com/matthewli/与原文地址:http://www.cnblogs.com/matthewli/p/6048907.html,谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号