在矩池云使用ChatGLM-6B & ChatGLM2-6B
ChatGLM-6B 和 ChatGLM2-6B都是基于 General Language Model (GLM) 架构的对话语言模型,是清华大学 KEG 实验室和智谱 AI 公司于 2023 年共同发布的语言模型。模型有 62 亿参数,一经发布便受到了开源社区的欢迎,在中文语义理解和对话生成上有着不凡的表现。
ChatGLM-6B 可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 针对中文问答和对话进行了优化,经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,已经能生成相当符合人类偏好的回答。
ChatGLM2-6B 则是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
-
更强大的性能:基于 ChatGLM 初代模型的开发经验,全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
-
更长的上下文:基于 FlashAttention 技术,将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,会在后续迭代升级中则有望进行优化。
-
更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
目前 ChatGLM-6B 以及 ChatGLM2-6B 均可通过登记进行商用,为方便大家使用,矩池云已第一时间获取到相关权限并上线了这两个模型的镜像,后续也会根据模型更新而进行镜像迭代,以下是在矩池云上使用 ChatGLM2-6B 的方法,ChatGLM-6B 的使用方法与其一致。

硬件要求
矩池云已经配置好了 ChatGLM-6B 和 ChatGLM2-6B 环境,显存需要大于13G。可以选择 A4000、P100、3090 或更高配置的显卡。
租用机器
在矩池云主机市场:https://matpool.com/host-market/gpu,选择显存大于13G的机器,比如 A4000 显卡,然后点击租用按钮(选择其他满足显存要求的显卡也可以)。
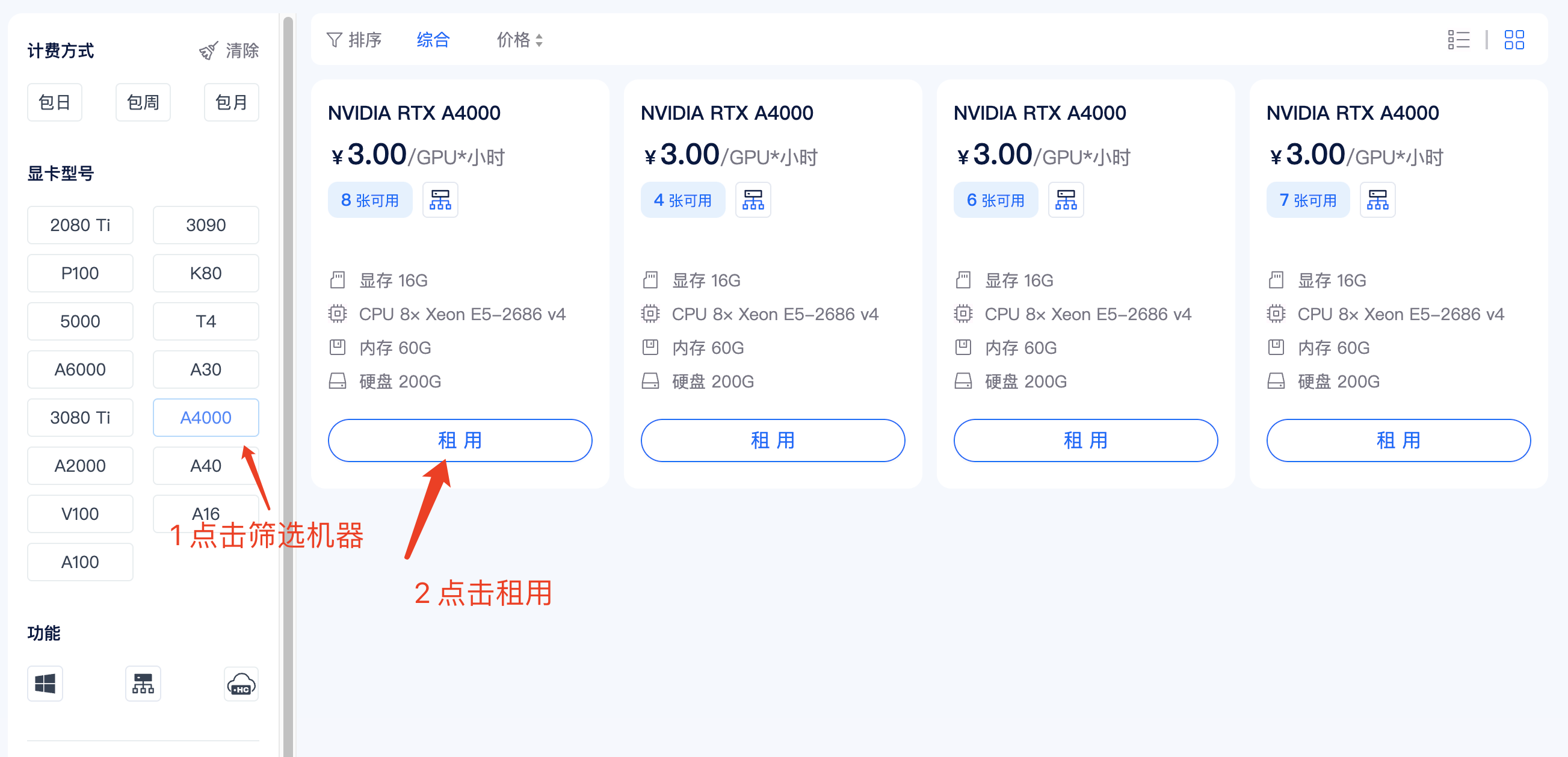
租用页面,搜索 ChatGLM2-6B,选择这个镜像,再点击租用即可。
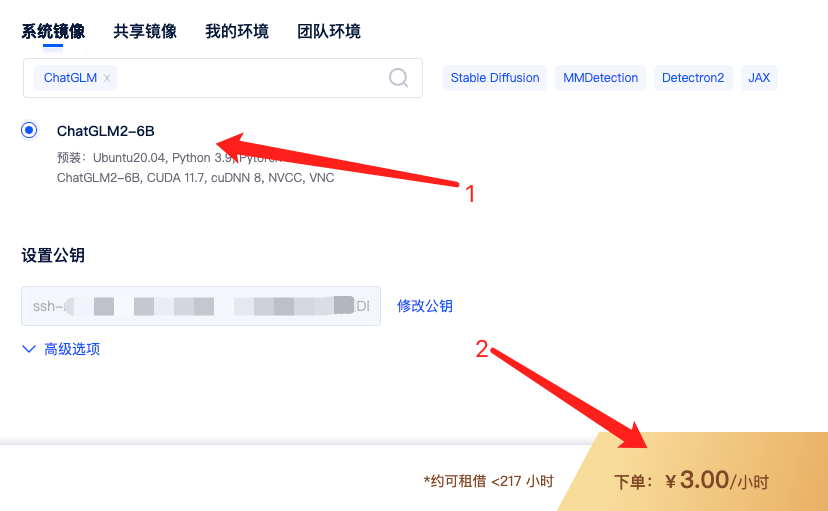
机器租用成功后,你会看到 8000 端口对应链接,这是 ChatGLM2-6B 默认的 api 接口,镜像已经设置了开机自启,也就是说现在可以直接调用这个接口使用 ChatGLM2-6B 了。

使用 ChatGLM2-6B api
调用 ChatGLM2-6B api 需要发送 POST 请求。前面租用机器我们自定义了 8000 端口,在租用页面可以获得对应的公网链接,比如:https://hz.xxxx.com:xxxx/?token=xxxxx
需要注意,实际我们请求不需要 token,所以直接用:https://hz.xxxx.com:xxxx 这段即可。
curl请求:
curl -X POST "https://hz.xxxx.com:xxxx" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'
Python请求:
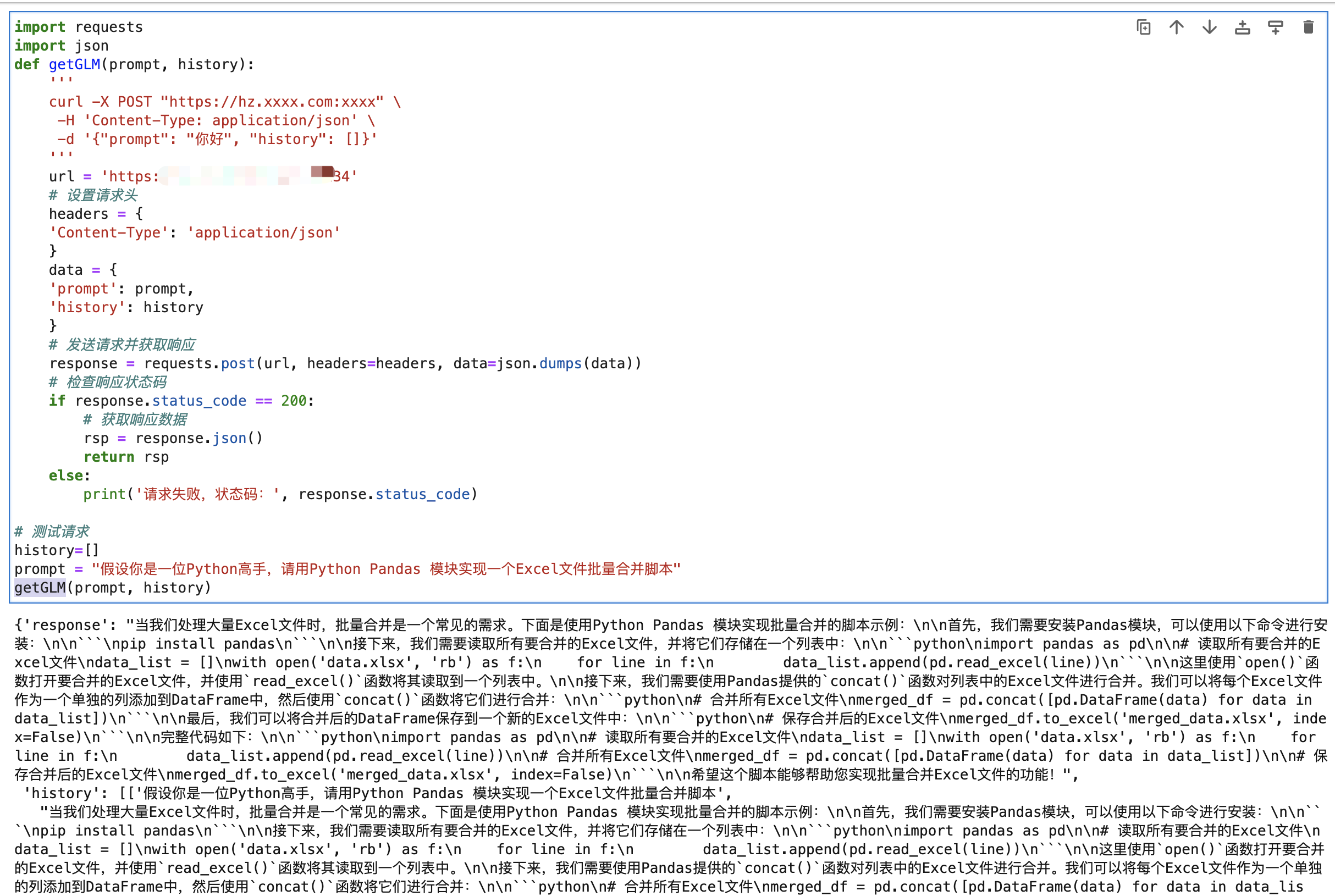
import requests
import json
def getGLM(prompt, history):
'''
curl -X POST "https://hz.xxxx.com:xxxx" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'
'''
url = 'https://hz.xxxx.com:xxxx'
# 设置请求头
headers = {
'Content-Type': 'application/json'
}
data = {
'prompt': prompt,
'history': history
}
# 发送请求并获取响应
response = requests.post(url, headers=headers, data=json.dumps(data))
# 检查响应状态码
if response.status_code == 200:
# 获取响应数据
rsp = response.json()
return rsp
else:
print('请求失败,状态码:', response.status_code)
# 测试请求
history=[]
prompt = "假设你是一位Python高手,请用Python Pandas 模块实现一个Excel文件批量合并脚本"
getGLM(prompt, history)
A4000 回复复杂点的问题(回复字数1.5k左右),耗时 20-40s 左右。
ChatGLM2-6B 也有 web demo,大家也可以运行测试,具体的使用方法如下文。
运行 ChatGLM2-6B web demo
首先我们需要 kill 掉系统开启自启的 ChatGLM2-6B API 服务,Jupyterlab 里新建一个 Terminal,然后输入下面指令查看api服务器进程id。
ps aux | grep api.py

kill 掉相关进程,从上面运行结果可以看出,api.py 进程id是5869,执行下面指令即可 kill 相关进程:
# 注意 5869 换成你自己租用服务器里查出来的 api.py 程序的进程id
# 注意 5869 换成你自己租用服务器里查出来的 api.py 程序的进程id
# 注意 5869 换成你自己租用服务器里查出来的 api.py 程序的进程id
kill 5869
运行 ChatGLM2-6B 版本 运行
# 进入项目目录
cd /ChatGLM2-6B
# 安装依赖
pip install streamlit streamlit_chat
# 启动脚本
streamlit run web_demo2.py --server.port 8000 --server.address 0.0.0.0

运行后服务会启动到 8000端口,host 设置成0.0.0.0,这样我们访问租用页面 8000 端口链接即可访问到对应服务了。
前面租用机器我们自定义了 8000 端口,在租用页面可以获得对应的公网链接:
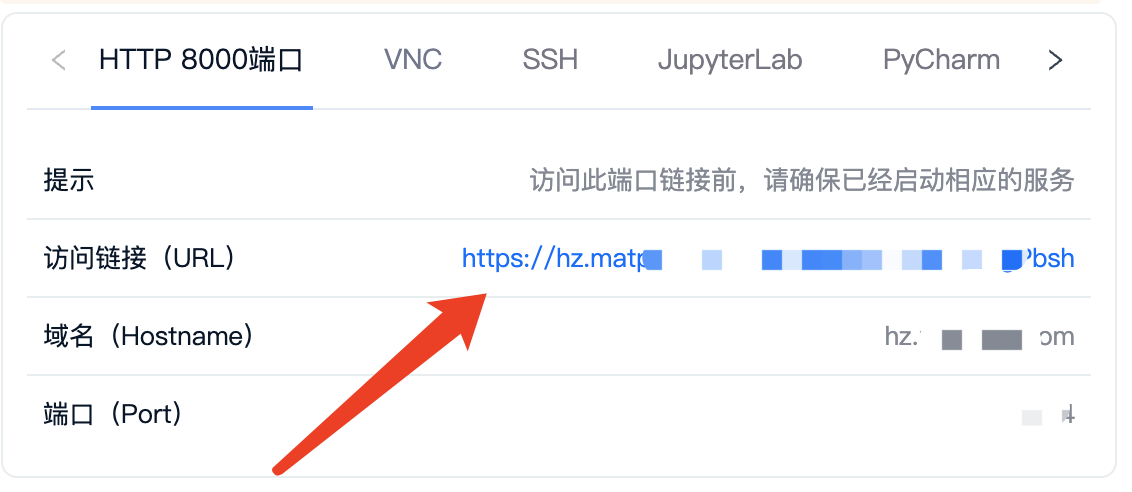
比如:https://hz.xxxx.com:xxxx/?token=xxxxx
需要注意的是,实际上我们在请求时候不需要 token,所以使用的地址直接用:https://hz.xxxx.com:xxxx 这段即可。

浅尝试一下生成的效果还不错,这个问题的回答有点出乎意料,给了一个用 pygame 写的猜数游戏,其他的一些模型一般回复的内容都是 cmd 版本的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号