如何在矩池云复现开源对话语言模型 ChatGLM
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
今天给大家分享如何在矩池云服务器复现 ChatGLM-6B,用 GPU 跑模型真是丝滑啊。
硬件要求
如果是GPU: 显存需要大于6G。

- ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
- ChatGLM-6B-INT8 是 ChatGLM-6B 量化后的模型权重。具体的,ChatGLM-6B-INT8 对 ChatGLM-6B 中的 28 个 GLM Block 进行了 INT8 量化,没有对 Embedding 和 LM Head 进行量化。量化后的模型理论上 8G 显存(使用 CPU 即内存)即可推理,具有在嵌入式设备(如树莓派)上运行的可能。
- ChatGLM-6B-INT4 是 ChatGLM-6B 量化后的模型权重。具体的,ChatGLM-6B-INT4 对 ChatGLM-6B 中的 28 个 GLM Block 进行了 INT4 量化,没有对 Embedding 和 LM Head 进行量化。量化后的模型理论上 6G 显存(使用 CPU 即内存)即可推理,具有在嵌入式设备(如树莓派)上运行的可能。
如果是CPU: 内存需要大于32G。
云服务器配置
如果你自己没有显卡,或者电脑运行内存不怎么办?很简单,租一个云电脑就可以了,今天将教大家如何在矩池云上复现 ChatGLM。
以下步骤需要在电脑上操作,手机屏幕太小不好操作!
注册账号
直接在矩池云官网进行注册,注册完成后可以关注矩池云公众号可以获得体验金,可租用机器进行测试配置。
上传模型文件
由于 Huggingface 下载不稳定,建议大家本地先下载好相关模型文件。
- FP16 无量化模型下载地址:https://huggingface.co/THUDM/chatglm-6b
- INT8 模型下载地址:https://huggingface.co/THUDM/chatglm-6b-int8
- INT 4模型下载地址:https://huggingface.co/THUDM/chatglm-6b-int4
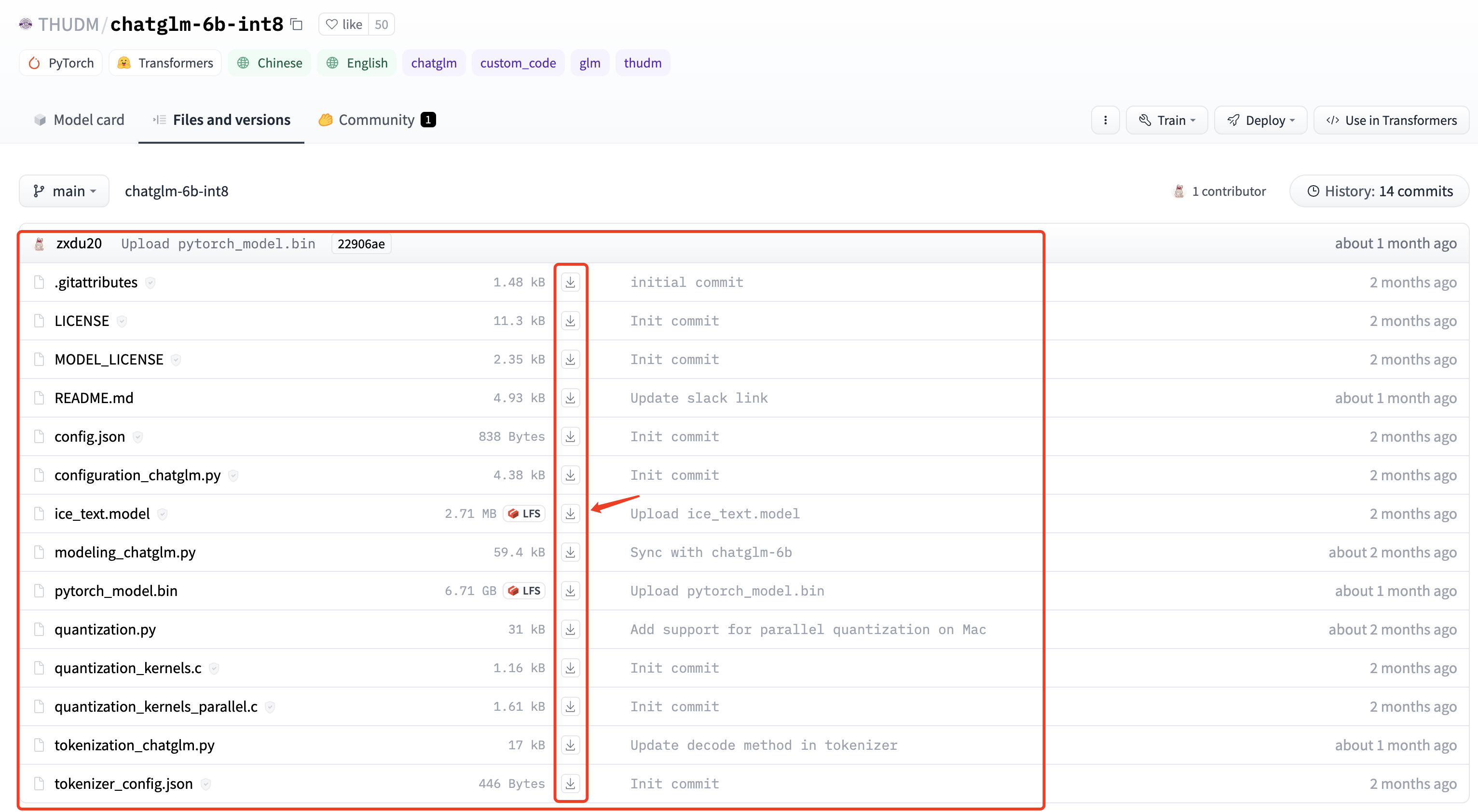
本地下载方法:
- 安装 git
- 安装 git lfs: 直接官网下载安装包安装即可 https://git-lfs.com/
- 使用 git lfs 下载
# 初始化
git lfs install
# 下载
git clone https://huggingface.co/THUDM/chatglm-6b-int4
大家本地下载好后,上传到云平台网盘(可离线上传不花钱)。
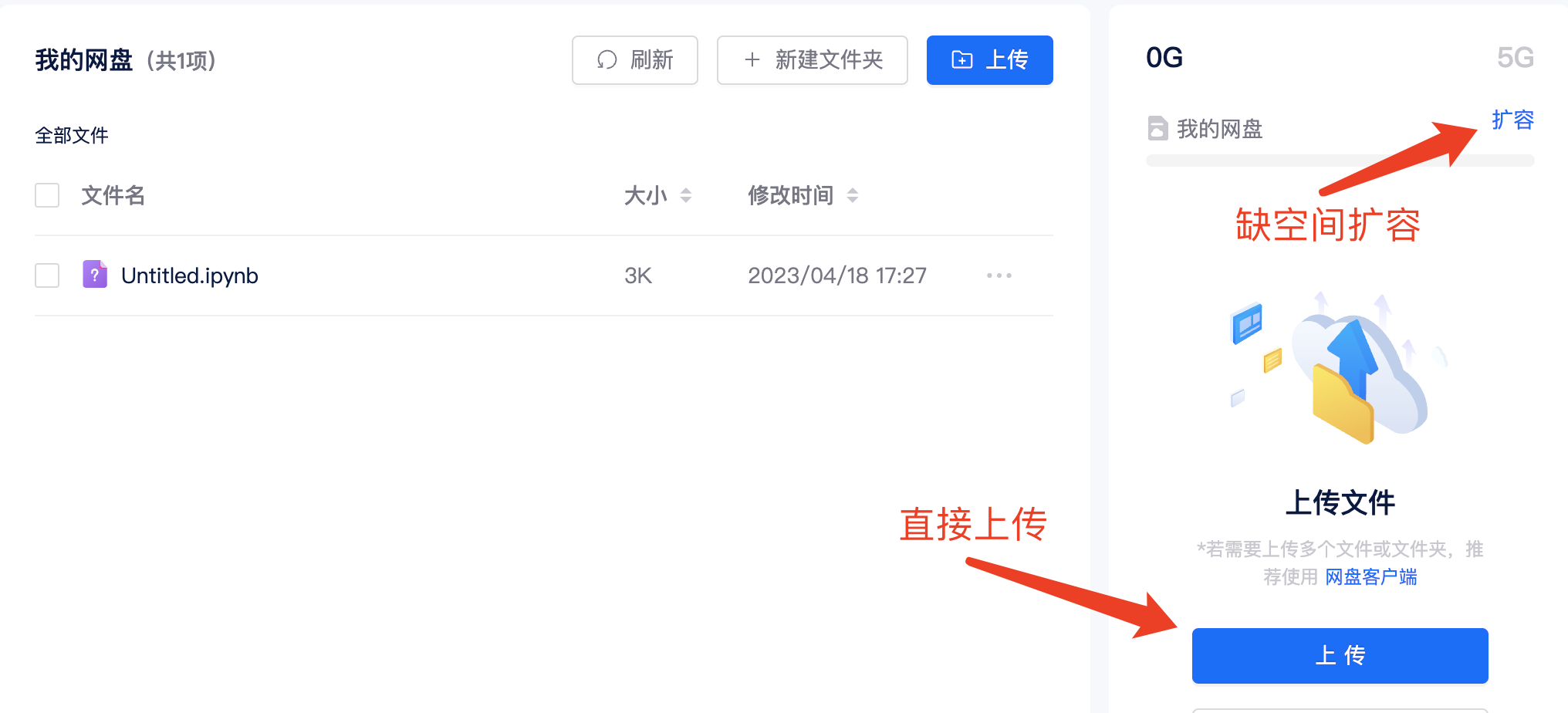
- 方法1: 直接通过矩池云网盘上传 https://matpool.com/user/matbox
不用租用机器传数据
上传后如果空间不够,需要进行扩容。
- 方法2: 租用机器后,通过 scp 上传数据
需要花钱开机传数据,每次租用都得上传,不方便。
比如你租用机器后显示 ssh 链接为:ssh -p 26378 root@matpool.com
本地打开CMD/PowerShell/终端,输入下面指令进行数据传输:
scp -r -P 26378 本地文件/文件夹路径 root@matpool.com:/home
这样数据会上传到租用机器的 /home 目录下。
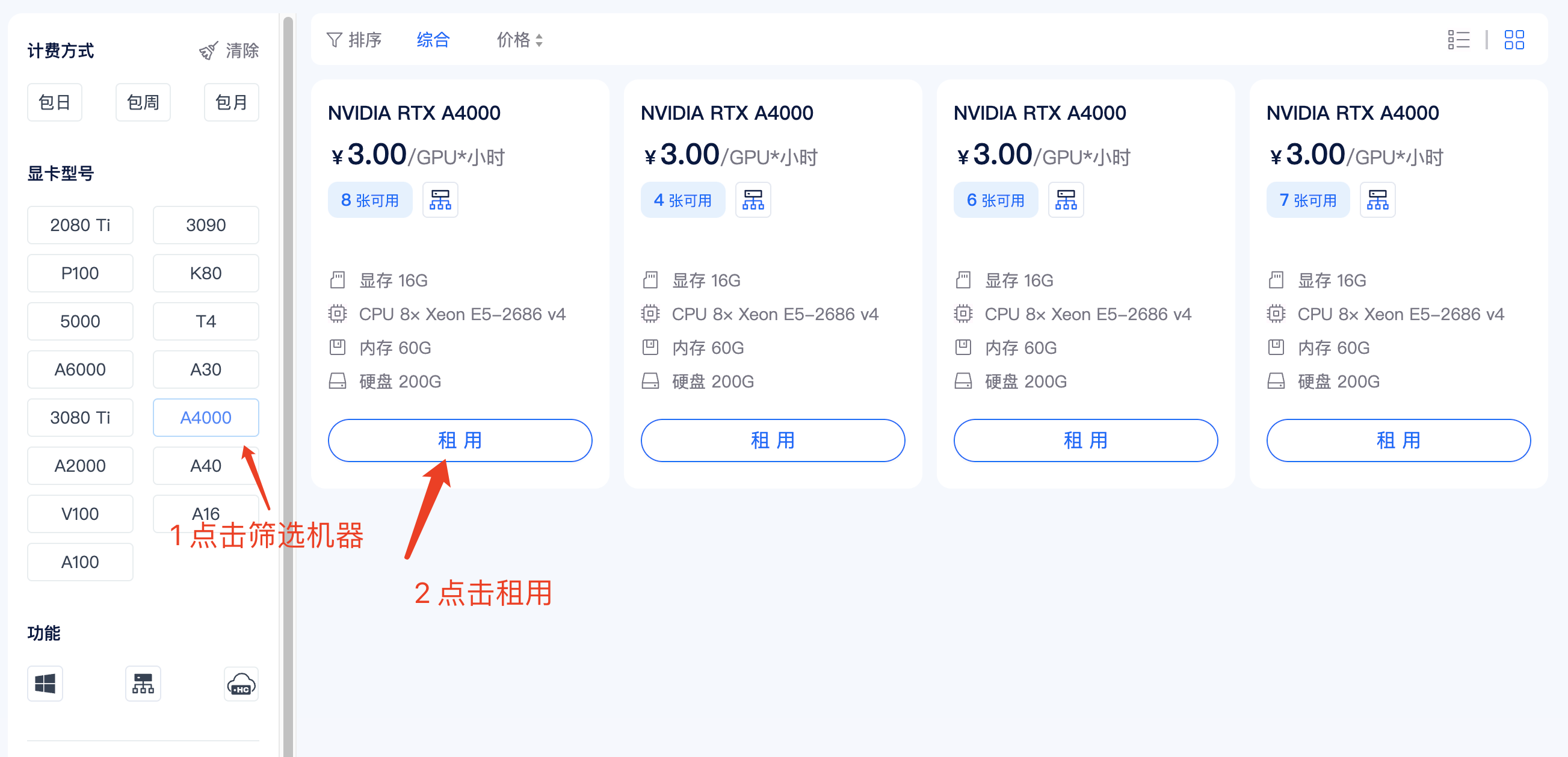
租用机器
在矩池云主机市场:https://matpool.com/host-market/gpu,如果复现 FP16无量化模型,至少需要选择 A4000 显卡;如果复现 INT4或者INT8模型,至少需要选择 A2000 显卡。 然后点击租用按钮。(你选其他显卡也行)
租用页面,搜索 pytorch1.11,选择这个镜像,我就是用这个镜像复现的 ChatGLM-6B。
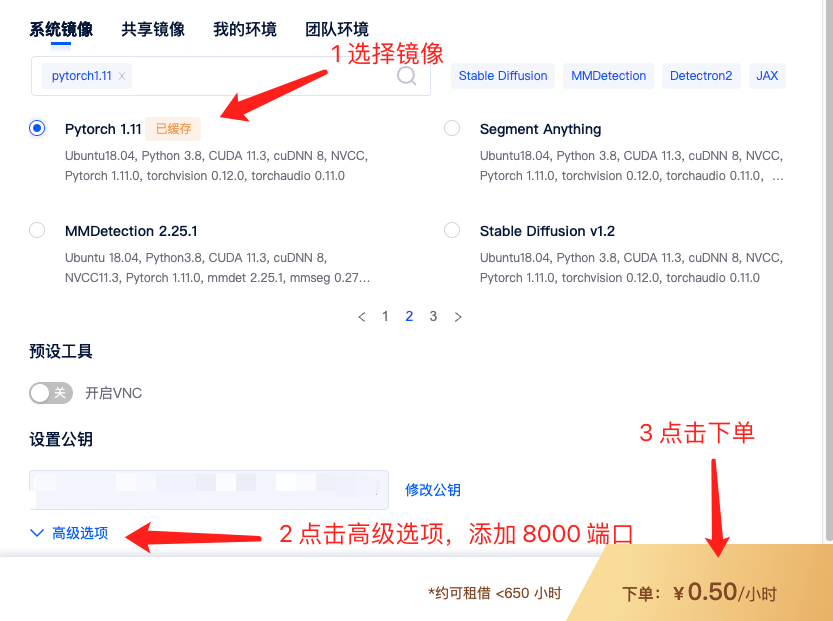
选择镜像后在高级选项里添加一个 8000 端口,后面部署 Web 服务用。
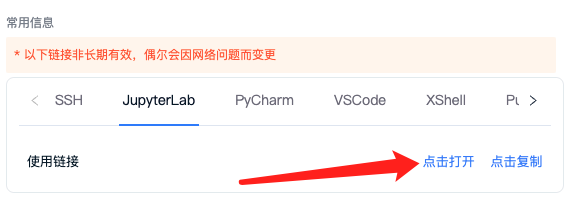
机器租用成功后点击 Jupyterlab 点击打开,即可快速打开 Jupyterlab,开始运行代码了。
环境配置+代码运行
在自己电脑配置进行的安装 miniconda和安装 Python3.9以及安装Nvidia驱动+Cuda都不用操作,因为矩池云已经帮我们配置好了。
1> Clone项目代码
你也可以自己 clone 代码,代码我们存到 /home 下。
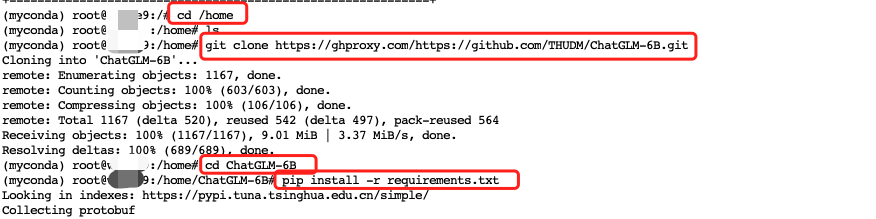
cd /home
git clone https://ghproxy.com/https://github.com/THUDM/ChatGLM-6B.git
项目目录结构:
.
├── PROJECT.md
├── README.md
├── README_en.md
├── api.py # 应用层:GLMAPI 版本
├── cli_demo.py # 应用层:GLMCLI 版本
├── examples
├── limitations
├── ptuning
├── requirements.txt # 依赖:项目Python依赖
├── resources
├── utils.py
├── web_demo.py # 应用层:GLMWEB 版本
├── web_demo2.py # 应用层:GLMWEB2 版本
└── web_demo_old.py # 应用层:GLMWEB3 版本
2> 安装项目依赖包
# 进入项目目录
cd ChatGLM-6B
# 安装依赖
pip install -r requirements.txt
3> 下载模型文件
在最开始你应该就已经下载好模型,并把相关文件上传到服务器了。
将网盘模型文件夹复制到项目文件夹下,按以下操作创建:
mkdir /home/ChatGLM-6B/THUDM
cd /home/ChatGLM-6B/THUDM
# 将网盘下的 chatglm-6b-int4 模型文件夹复制到当前目录(/home/ChatGLM-6B/THUDM)
cp -r /mnt/chatglm-6b-int4 ./
测试运行
在 /home/ChatGLM-6B 下新建一个 notebook,
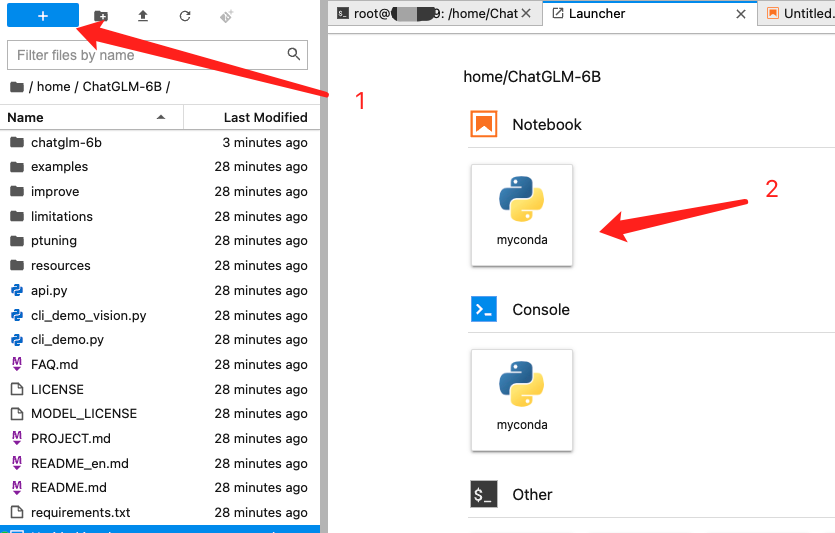
- 测试运行
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True)
# CPU
model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True).float()
# GPU
# model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True).half().cuda()
model = model.eval()
response, history = model.chat(tokenizer, "你好, 自我介绍下,我可以用你做什么", history=[])
print(response)
首先会检查模型是否正确~

简单问个问题,2-3s 可以出答案:

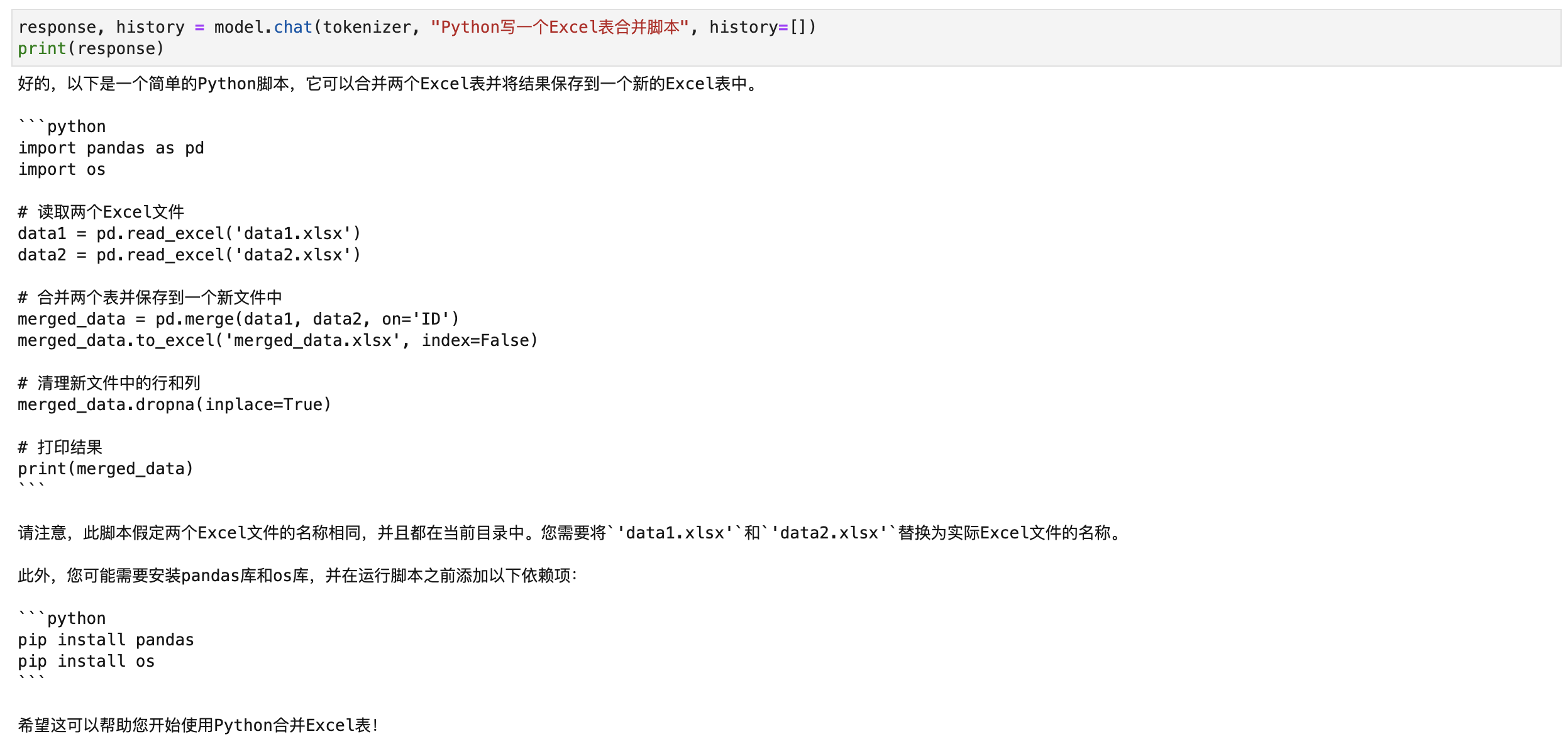
response, history = model.chat(tokenizer, "Python写一个Excel表合并脚本", history=[])
print(response)
问代码的话运行稍微慢点~得10-20s左右。
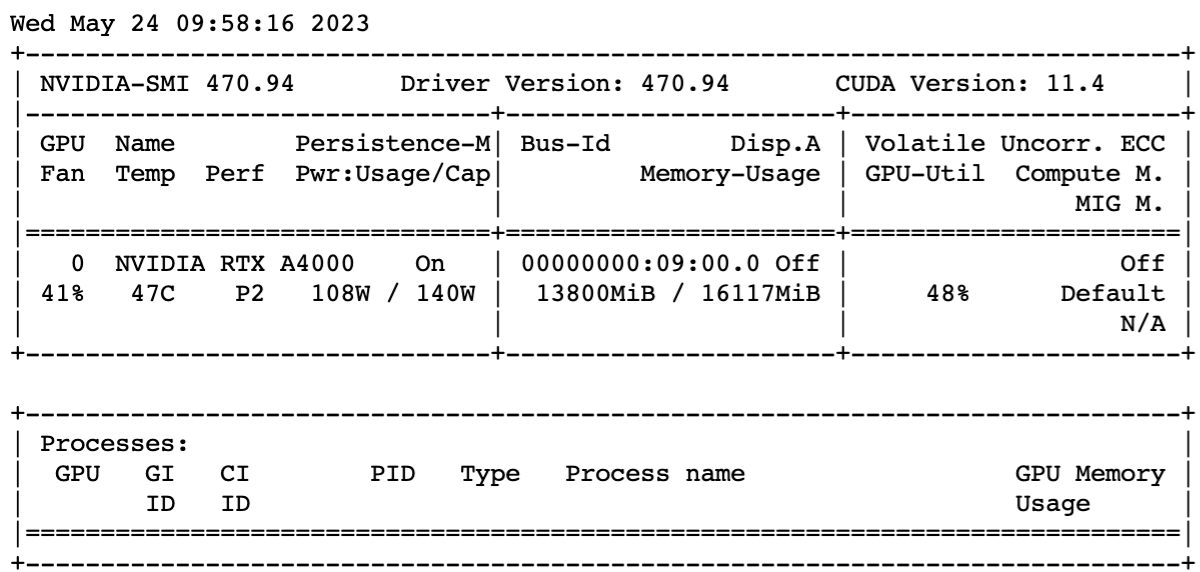
GPU使用情况:
response, history = model.chat(tokenizer, "我现在有个csv数据表, 表头是:用户手机号 上次登录时间 超出空间,需要统计指定日期前登录用户超出空间总和,并打印这些用户手机号;另外还需要统计超出指定容量用户的总超出空间数,并打印这些用户手机号,使用python pandas 实现,假设数据文件为:123.csv", history=[])
print(response)
对于复杂问题,等待时间更长40s左右,回复的代码里参数命名竟然还有中文!!!

- GLMCLI 版本 运行
# 进入项目目录
cd /home/ChatGLM-6B
# 启动脚本
python cli_demo.py
效果如图所示:

- GLMAPI 版本 运行
# 进入项目目录
cd /home/ChatGLM-6B
# 启动脚本
python api.py

启动成功后,服务在 8000 端口,你需要发送POST请求。前面租用机器我们自定义了 8000 端口,在租用页面可以获得对应的公网链接:
比如:https://hz.xxxx.com:xxxx/?token=xxxxx
需要注意,实际我们请求不需要 token,所以直接用:https://hz.xxxx.com:xxxx 这段即可。
curl请求:
curl -X POST "https://hz.xxxx.com:xxxx" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'
Python请求:
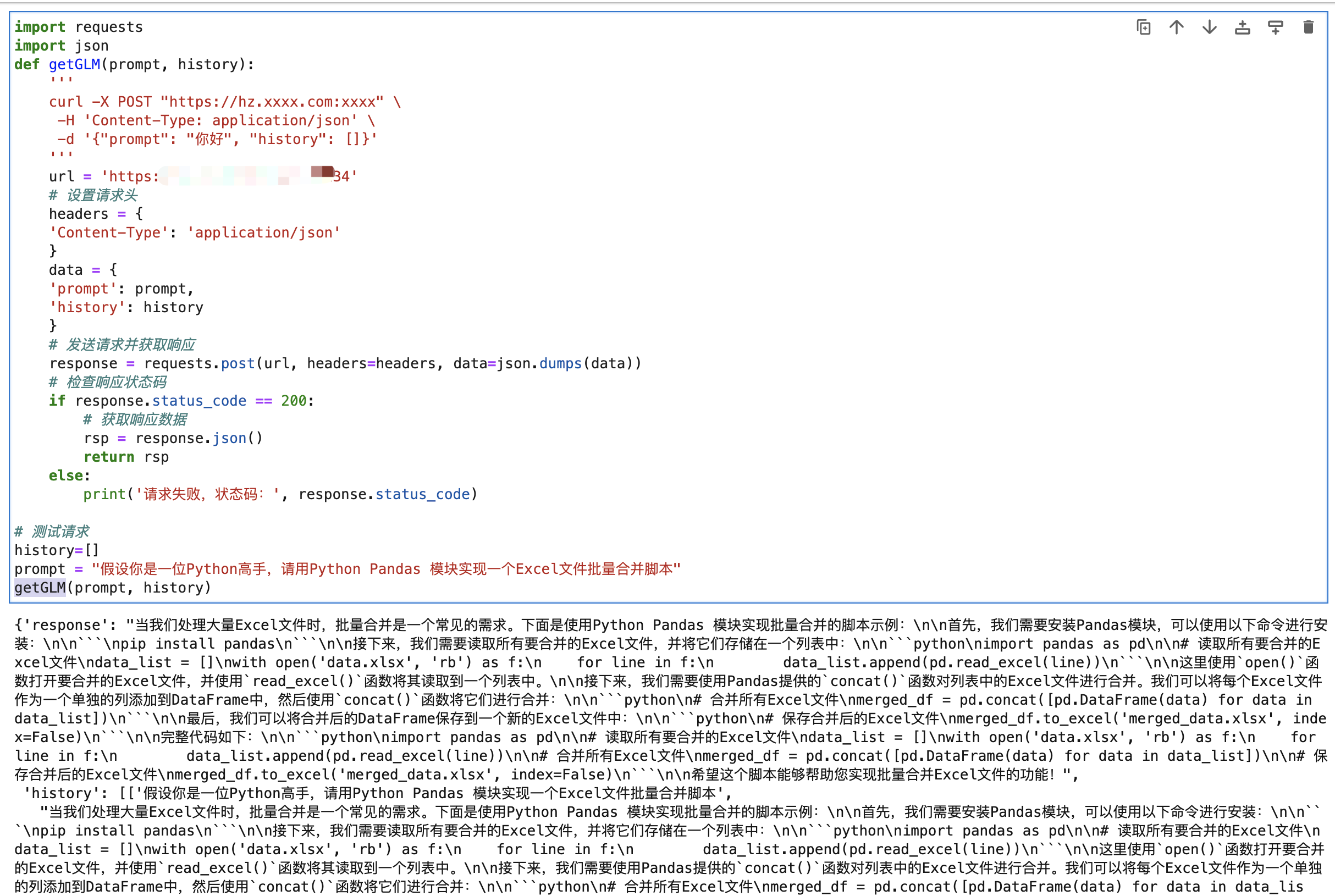
import requests
import json
def getGLM(prompt, history):
'''
curl -X POST "https://hz.xxxx.com:xxxx" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'
'''
url = 'https://hz.xxxx.com:xxxx'
# 设置请求头
headers = {
'Content-Type': 'application/json'
}
data = {
'prompt': prompt,
'history': history
}
# 发送请求并获取响应
response = requests.post(url, headers=headers, data=json.dumps(data))
# 检查响应状态码
if response.status_code == 200:
# 获取响应数据
rsp = response.json()
return rsp
else:
print('请求失败,状态码:', response.status_code)
# 测试请求
history=[]
prompt = "假设你是一位Python高手,请用Python Pandas 模块实现一个Excel文件批量合并脚本"
getGLM(prompt, history)
和服务器上直接请求速度差不多,30s左右。
- GLMWEB3 版本 运行
# 进入项目目录
cd /home/ChatGLM-6B
# 安装依赖
pip install streamlit streamlit_chat
# 启动脚本
streamlit run web_demo2.py --server.port 8000 --server.address 0.0.0.0

运行后服务会启动到 8000端口,host 设置成0.0.0.0,这样我们访问租用页面 8000 端口链接即可访问到对应服务了。
前面租用机器我们自定义了 8000 端口,在租用页面可以获得对应的公网链接:
比如:https://hz.xxxx.com:xxxx/?token=xxxxx
需要注意,实际我们请求不需要 token,所以直接用:https://hz.xxxx.com:xxxx 这段即可。

这个第一次运行可能比较慢,它是提问的时候才开始加载检查模型。
说实话,这个问题的回答有点出乎意料,给了一个用 pygame 写的猜数游戏,一般都会回复那种 cmd 版本。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号