进击的 AI 生成,创造性的新世界!
2022年,AI艺术生成文本生成图像的AI绘画生成器如雨后春笋般涌现,以一幅幅“不明觉厉”的AI作品进入大众视野。从2月Disco Diffusion爆火,仅两个月后OpenAI发布DALL-E 2,谷歌和Meta紧随其后宣布了各自的AI”画家“Imagen和Make-A-Scene,再到7月MidJourney向公众付费开放,8月Stable Diffusion横空出世,AI绘画模型掀起了“人人都是艺术家”的一个个热潮。随之而来的视频生成AI模型更是让“人人都能是导演”。
文本-图像AI
由于其开源属性,以及突飞猛进的”艺术造诣”,Disco Diffusion最先引发了全民作画的热潮。只要输入文字提示(prompt),就能让AI输出它所理解的对应图像。虽然出图速度慢,在细节处理方面也比较抱歉,尤其是人脸生成,不过图片整体效果较为惊艳、氛围感强(更适合抽象艺术)。

在矩池云上生成的DD图片
相较于DD的”不拘小节“,OpenAI的DALL-E 2在细节方面拿捏比较到位,生成的图像比较精准逼真,而且作画速度提高了不少,为图像生成领域立了新的标杆。另外,DALL-E 2能对所生成的图像进行二次编辑。早期OpenAI只邀请了部分用户进行内测并且限制绘图次数,不过近期已全面开放所有人使用(中国地区账号暂不支持)。

Prompt: “a painting of a fox sitting in a field at sunrise in the style of Claude Monet
对标OpenAI的DALL-E 2,谷歌推出的Imagen声称提供了“前所未有的照片真实感和深度语言理解”。在为不同对象分配颜色、带引号文本、对象位置关系方面,Imagen表现似乎更优。不过,该模型未开放,谷歌给出的解释是:“系统太危险了,不能发布”。
同期还有另一科技巨头Meta的Make-a-scene,它的创新在于”交互+可控“,重点是用户控制。通过文本描述,再加上一张草图,让AI有针对性地生成图像。目前,只有部分艺术家受邀进行了使用。

而引发更多人关注AI绘画的是使用Midjourney生成的一副油画——

这幅使用MidJourney 生成的数字油画在美国科罗拉多州博览会(Colorado State Fair)的艺术比赛中夺得了第一名。这一新闻被报道后引发了圈内外的广泛讨论。
Midjourney也是不负众望,综合能力比较全面,图像生成速度极快,很多艺术家会借助Midjourney作为创作灵感。另外,因为 Midjourney 搭载在 Discord 频道上,所以有非常良好的社区讨论环境和用户基础。不过,表现不俗、简单上手也意味着Midjourney需要付费使用。
| AI绘画模型 | 模型 | 是否开源 | 生成速度 | 生成内容限制 | 运行设备 |
|---|---|---|---|---|---|
| Disco Diffusion | CLIP+Diffusion | 开源 | 分/时 | 无限制 | >显存10G,Nvidia 1080ti级别 |
| DALL-E 2 | CLIP+改进版GLIDE(Diffusion模型的一种) | 部分开源 | 秒/分 | 无法生成暴力、裸体或真实面孔的图像 | / |
| Stable Diffusion | Latent Diffusion | 开源 | 秒/分 | 无限制 | >显存6G,RTX 2060级别 |
紧接着,“更上一层楼”的Stable Diffusion来了。Stable Diffusion不仅开源免费,上手还足够简单,出图速度也极快,图片效果更为精准写实,掀起了AI绘画的又一个高潮。

在AI绘画模型“墙外开花”的同时,这股浪潮也席卷了国内,百度等科技巨头以及一大批艺术、AI从业者和爱好者也不甘其后,纷纷发布文本输入生成图像的国产AI绘画产品文心一格(暂时免费)、6pen(部分免费)、MuseArt(付费+看广告)、盗梦师(免费次数+付费微信小程序)等等。
文本-视频AI
当我们还在鉴赏(挑刺)AI生成的图像时,“下笔生花”的算法研究员们早已不满足于二维创作/图像生成,在三维甚至视频生成这一赛道上,大家也在摩拳擦掌……
Google Research的DreamFusion模型,可以通过输入简单的文本提示生成3D模型,甚至可以把生成的多个3D模型融合到一个场景里。
清华大学和智源研究院早在今年5月发布了基于Transformer的AI生成模型CogVideo,能够根据文本直接合成视频。
9月29日,Meta发布了基于AI的短视频生成模型Make-A-Video,是对其Make-A-Scene文本到图像工具的升级,可以通过文本提示生成新的视频内容。
仅一周后,谷歌接连发布了两个AI生成视频模型——Imagen Video和Phenaki。和Meta的Make-A-Video相比,谷歌的Imagen Video更高清,能生成1280*768分辨率、每秒24帧的视频片段。
Phenaki则能根据200个词左右的提示语生成2分钟以上的长镜头,就是说,人人都能是”导演”了。Phenaki还可以任意切换视频风格,高清视频或卡通。
在视频风格转换方面,几天前来自新加坡南洋理工大学的研究团队发布了一个能够进行可控高分辨率人像视频风格转换的框架——VToonify。基于StyleGAN的VToonify满足了很多人在短视频平台上使用卡通形象录制视频的需求,可以实现对人像进行高度可调的卡通风格切换。
AI生成技术的迭代
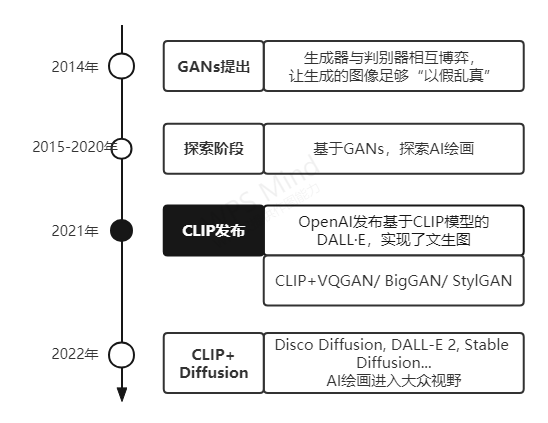
AI生成图像的表现越来越出色,得益于深度学习模型的快速迭代。2012年,AI大牛吴恩达和Jeff Dean等人通过1000台电脑创造出多达10亿个连接的“神经网络”,基于上千万张猫脸图片进行训练后,最终生成了一个模糊的猫脸,这意味着机器自主学会了识别猫脸。
在这一开创性猫脸生成实验后,AI科学家们在图像生成方向上继续摸索。两年后大名鼎鼎的对抗生成网络GANs诞生,它通过生成器和判别器两者的互相对抗不断提升生成能力。自此,AI生成领域主要基于GANs进行了不断的尝试。
彼时,AI绘画还无法实现通过文字输入提示(prompt)进行图像生成。
直到2021年,OpenAI发布了一个新的深度学习模型CLIP(Contrastive Language-Image Pre-Training),实现了图像与文本的匹配。CLIP基于大规模图文数据集进行了对比学习训练,学习给定文本片段与图像的关联。也就是说,CLIP并不是试图预测给定图像的对应文字说明,而是只学习任何给定文本与图像之间的关联。好的,自然语言和视觉任务的跨界界限自此被CLIP打破!
生成式AI会让艺术家们失业吗
而每当技术爆炸迭代到令人瞠目结舌的地步,“人类会不会被机器取代”这一永恒命题又悄然而至——AI会让艺术家们失业吗?AI会冲击短视频行业吗?
就像其他职业的AI威胁论一样,AI取代部分机械重复性较高的工作可能不可避免,但天马行空的想象力和四季三餐的情感共鸣对于AI来说想得而不可得。正如Midjourney创始人David Holz评论AI绘画,
“汽车比人的速度快,但这并不意味着我们不再行走。远距离移动大量物体时,我们需要用到发动机,无论是飞机、轮船还是汽车。我们认为AI绘画技术就是想象力的引擎。”
参考链接
https://mp.weixin.qq.com/s/LsJwRMSqPXSjSyhoNgzi6w
https://github.com/OpenAI/CLIP
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号