基于yolov2深度学习网络的猫脸检测识别matlab仿真
1.算法运行效果图预览



2.算法运行软件版本
matlab2022a
3.算法理论概述
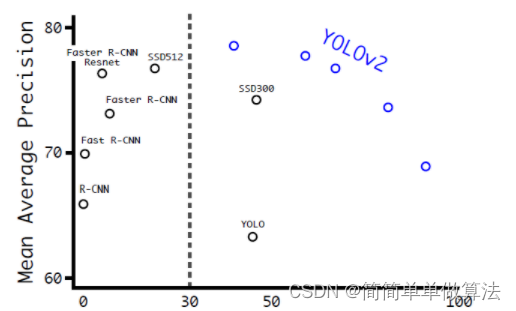
YOLOv2的论文全名为YOLO9000: Better, Faster, Stronger,它斩获了CVPR 2017 Best Paper Honorable Mention。在这篇文章中,作者首先在YOLOv1的基础上提出了改进的YOLOv2,然后提出了一种检测与分类联合训练方法,使用这种联合训练方法在COCO检测数据集和ImageNet分类数据集上训练出了YOLO9000模型,其可以检测超过9000多类物体。所以,这篇文章其实包含两个模型:YOLOv2和YOLO9000,不过后者是在前者基础上提出的,两者模型主体结构是一致的。YOLOv2相比YOLOv1做了很多方面的改进,这也使得YOLOv2的mAP有显著的提升,并且YOLOv2的速度依然很快,保持着自己作为one-stage方法的优势,YOLOv2和Faster R-CNN, SSD等模型的对比如下图所示。
基于YOLOv2深度学习网络的猫脸检测识别是一种利用深度卷积神经网络进行目标检测的方法。下面将详细介绍这种方法的原理和数学公式。
YOLOv2是一种基于深度卷积神经网络的目标检测算法,它将目标检测任务转化为一个回归问题,直接在输出层回归目标的边界框(bounding box)和类别信息。相较于传统的目标检测方法,YOLOv2具有速度快、准确率高、能够处理复杂背景等优点。
在猫脸检测识别任务中,YOLOv2首先会对输入图像进行特征提取,然后利用这些特征进行猫脸的位置和大小预测。具体来说,YOLOv2将输入图像划分成S×S个网格,每个网格负责预测B个边界框和C个类别概率值。如果一个物体的中心落在某个网格内,则该网格负责预测这个物体的边界框和类别信息。
每个边界框包含5个参数,分别是边界框的中心坐标(x,y)、宽度w、高度h和置信度confidence。置信度反映了模型对这个边界框是否包含物体的置信程度。
每个网格还需要预测C个类别概率值,表示该网格内物体属于每个类别的概率。最终,每个边界框的类别置信度可以通过类别概率值和边界框置信度相乘得到。
4.部分核心程序
load yolov2.mat% 加载训练好的目标检测器
img_size= [224,224];
imgPath = 'test/'; % 图像库路径
imgDir = dir([imgPath '*.jpg']); % 遍历所有jpg格式文件
cnt = 0;
for i = 1:36 % 遍历结构体就可以一一处理图片了
i
if mod(i,12)==1
figure
end
cnt = cnt+1;
subplot(3,4,cnt);
img = imread([imgPath imgDir(i).name]); %读取每张图片
I = imresize(img,img_size(1:2));
[bboxes,scores] = detect(detector,I,'Threshold',0.15);
if ~isempty(bboxes) % 如果检测到目标
I = insertObjectAnnotation(I,'rectangle',bboxes,scores,LineWidth=3);% 在图像上绘制检测结果
end
subplot(3,4,cnt);
imshow(I, []); % 显示带有检测结果的图像
pause(0.01);% 等待一小段时间,使图像显示更流畅
if cnt==12
cnt=0;
end
end

 浙公网安备 33010602011771号
浙公网安备 33010602011771号