基于GMM高斯混合模型的语音信息身份识别算法的matlab仿真
1.算法理论概述
一、引言
语音信息身份识别是指通过声音信号对个体进行身份识别的过程。目前,语音信息身份识别已经成为语音处理领域的一个热门研究方向。在语音信息身份识别中,高斯混合模型(GMM)是一种被广泛应用的方法。本文将详细介绍基于GMM的语音信息身份识别算法的实现步骤和数学原理。
二、GMM模型
GMM模型是一种基于统计学的模型,常用于对多维数据进行建模。在语音信息身份识别中,GMM模型可以用于对语音信号进行建模和分类。GMM模型假设每个类别的数据是由多个高斯分布组成的混合分布,每个高斯分布表示该类别的一种特征。GMM模型可以用以下公式表示:
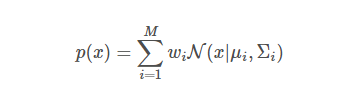
其中,$p(x)$表示数据$x$的概率密度函数,$M$表示高斯分布的数量,$w_i$表示第$i$个高斯分布的权重,$\mu_i$表示第$i$个高斯分布的均值,$\Sigma_i$表示第$i$个高斯分布的协方差矩阵,$\mathcal{N}(x|\mu_i,\Sigma_i)$表示以$\mu_i$为均值,$\Sigma_i$为协方差矩阵的高斯分布。
三、语音信息身份识别算法
基于GMM的语音信息身份识别算法的实现步骤如下:
提取语音特征
使用声学特征提取算法,如MFCC(Mel频率倒谱系数)算法,将语音信号转换为数值型的特征向量。MFCC算法将语音信号分帧,并对每一帧进行傅里叶变换,然后将频率轴上的能量值转换为Mel频率轴上的能量值,并计算其倒谱系数。最后,将每一帧的倒谱系数串联起来,得到该帧的MFCC特征向量。
训练GMM模型
使用训练数据集训练GMM模型。对于每个说话人,使用其训练集中的语音信号提取MFCC特征,并使用GMM模型对MFCC特征进行建模。对于每个说话人,GMM模型的高斯分布数量和协方差矩阵可以根据其训练集的大小和分布进行调整。
计算GMM得分
对于测试集中的每个语音信号,提取其MFCC特征,并使用GMM模型计算其GMM得分。对于每个说话人的GMM模型,根据其权重、均值和协方差矩阵,可以计算该语音信号在该说话人模型下的概率密度值,即GMM得分。对于每个说话人,选择其GMM得分最高的语音信号作为其身份识别结果。
2.算法运行软件版本
MATLAB2022a
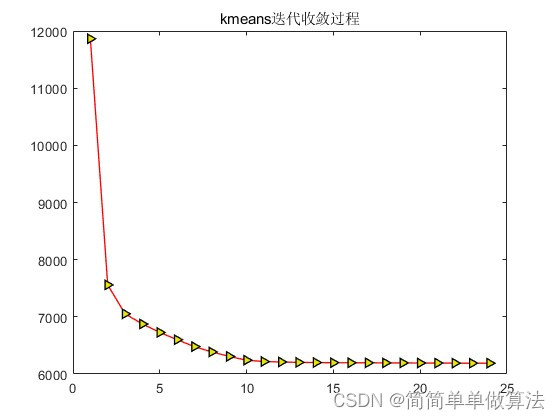
3.算法运行效果图预览


4.部分核心程序
%训练
load data\train_data.mat; %加载训练数据
%遍历人
for ij=1:Pnum
ij%显示当前正在处理的人的序号
idx1=1;%初始化MFCC特征矩阵的列下标
idx2=1;
%遍历语音
for jk=1:Tnum
speech = tdata{ij}{jk}; %获取当前人的当前语音信号
%预处理
%预加重
pre_emp = filter([1 -0.97],1,speech); %预加重处理
%汉明窗
win_type= 'M'; %设置窗函数类型为汉明窗
%倒谱系数
Nmfcc = 20; %设置MFCC特征中的倒谱系数个数为20
%帧长
Lframe = fs*0.02; %设置帧长为20ms
%滤波器组个数
Nfilter = 20; %设置滤波器组的个数为20
%帧移
Offset_frame = fs*0.01; %设置帧移为10ms
%mfcc特征
Fmfcc = melcepst(pre_emp,fs,win_type,Nmfcc,Nfilter,Lframe,Offset_frame);
Fmfcc2 = Fmfcc(:,1:end-1)';%去掉每帧的能量值,只保留MFCC系数
idx2 = idx1+size(Fmfcc2,2);%计算MFCC特征矩阵的列下标上界
cof(:,idx1:idx2-1) = Fmfcc2;%将MFCC特征存储到特征矩阵中
idx1 = idx2;%更新MFCC特征矩阵的列下标下界
end
%GMM训练
K_iter =30; %Kmeans迭代次数
EM_iter=30; %EM迭代次数
%GMM的初始化
[mix,Kerr] = gmm_init(nums,cof',K_iter,'full'); %使用Kmeans算法对GMM的参数进行初始化
[mix,post,errlog] = gmm_em(mix,cof',EM_iter); %使用EM算法对GMM模型的参数进行估计
%将训练得到的GMM模型的参数存储到Gmm_model变量中
Gmm_model{ij}.pai = mix.priors;
Gmm_model{ij}.mu = mix.centres;
Gmm_model{ij}.sigma = mix.covars;
clear cof mix;
end
%绘制Kmeans迭代的收敛过程
figure;
plot(Kerr,'-r>',...
'LineWidth',1,...
'MarkerSize',6,...
'MarkerEdgeColor','k',...
'MarkerFaceColor',[0.9,0.9,0.0]);
title('kmeans迭代收敛过程');
%绘制EM迭代的收敛过程
figure;
plot(errlog,'-r>',...
'LineWidth',1,...
'MarkerSize',6,...
'MarkerEdgeColor','k',...
'MarkerFaceColor',[0.9,0.9,0.0]);
title('EM迭代收敛过程');

 浙公网安备 33010602011771号
浙公网安备 33010602011771号