基于模板匹配算法的车牌数字字母识别matlab仿真,带GUI界面
1.算法理论概述
随着交通工具的普及,车辆数量快速增长,车辆管理变得越来越重要。在车辆管理中,车牌号码的自动识别是一个重要的环节。从传统的手工识别,到现在的自动化识别,车牌识别技术已经成为了一个热门的研究领域。其中,数字字母识别是车牌识别的重要组成部分。本文将介绍基于ORC模板匹配算法的车牌数字字母识别方法。
1.1算法原理
ORC模板匹配算法是一种基于模板匹配的数字字母识别方法。该方法基于一组预定义的数字字母模板,通过计算待识别数字字母与模板的相似度,来确定待识别数字字母的类别。具体实现步骤如下:
1.2数据预处理
将待识别的数字字母图像进行预处理,包括二值化、去噪等操作,以便提高识别精度。
1.3特征提取
从预处理后的数字字母图像中,提取出一组特征向量,用于表示该数字字母的形态特征。常用的特征提取方法包括傅里叶描述符、轮廓描述符、哈尔描述符等。
1.4模板匹配
将待识别数字字母的特征向量与预定义的数字字母模板的特征向量进行比较,计算它们之间的相似度。相似度的计算可以使用欧几里得距离、余弦相似度等方式。根据计算出的相似度,确定待识别数字字母的类别,并将结果输出。
下面给出ORC模板匹配算法中常用的两种相似度计算方式及其公式:
欧几里得距离是一种常用的距离度量方式,它可以用于计算两个向量之间的相似度。设向量a和向量b的维度均为n,则它们之间的欧几里得距离为:
d(a,b) = sqrt(sum((ai - bi) ^ 2)), i = 1, 2, ..., n
其中,ai和bi分别表示向量a和向量b的第i维元素。
余弦相似度是一种常用的相似度计算方式,它可以用于计算两个向量之间的相似度。设向量a和向量b的维度均为n,则它们之间的余弦相似度为:
cos(a,b) = dot(a,b) / (||a|| * ||b||)
其中,dot(a,b)表示向量a和向量b的点积,||a||表示向量a的模,||b||表示向量b的模。
下面给出ORC模板匹配算法的具体实现步骤。
将待识别的数字字母图像进行预处理,包括灰度化、二值化、去噪等操作。其中,灰度化可以采用RGB灰度化、加权平均法等方式;二值化可以采用固定阈值、自适应阈值等方式;去噪可以采用中值滤波、均值滤波等方式。
从预处理后的数字字母图像中,提取出一组特征向量,用于表示该数字字母的形态特征。常用的特征提取方法有以下几种:
(1)轮廓描述符(Contour Descriptor):该方法通过计算数字字母边缘的曲率和方向,生成一个轮廓向量,用于表示数字字母的形状特征。
(2)傅里叶描述符(Fourier Descriptor):该方法将数字字母的轮廓看作一个连续的曲线,通过傅里叶变换将其分解成若干个正弦和余弦波形,然后将这些波形的系数作为特征向量,用于表示数字字母的形态特征。
(3)Zernike矩(Zernike Moment):该方法通过将数字字母的轮廓投影到一组正交的基函数上,生成一组Zernike矩,用于表示数字字母的形态特征。
将待识别数字字母的特征向量与预定义的数字字母模板的特征向量进行比较,计算它们之间的相似度。相似度的计算可以使用欧几里得距离、余弦相似度等方式。具体实现步骤如下:
(1)定义一组预定义的数字字母模板,每个模板都具有一组特征向量。
(2)将待识别数字字母的特征向量与每个模板的特征向量进行比较,计算它们之间的相似度。
(3)选择相似度最高的模板,将其类别作为待识别数字字母的类别。
2.算法运行软件版本
matlab2022a
3.算法运行效果图预览
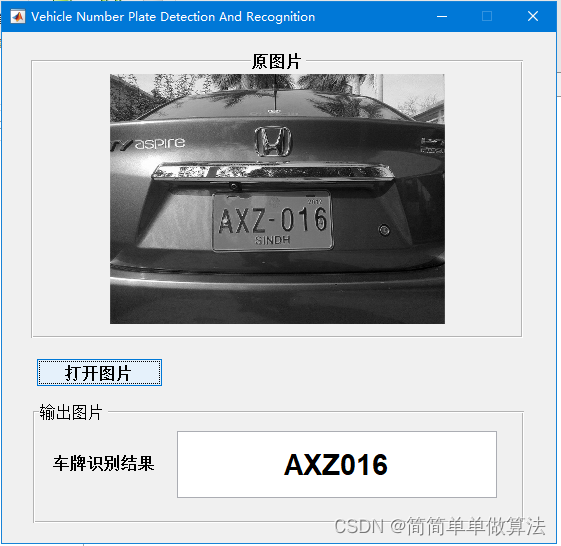

4.部分核心程序
function r=controlling(NR)
% 找到纵坐标直方图中值为6的区间
[Q,W]=hist(NR(:,4));
ind=find(Q==6);
for k=1:length(NR)
C_5(k)=NR(k,2) * NR(k,4);
end
NR2=cat(2,NR,C_5');
[E,R]=hist(NR2(:,5),20);
Y=find(E==6);
if length(ind)==1% 如果纵坐标直方图中有且仅有一个纵坐标值出现次数为6
MP=W(ind);% 将该纵坐标值作为分割容器的中心位置
binsize=W(2)-W(1);% 计算容器的大小
container=[MP-(binsize/2) MP+(binsize/2)]; % 创建一个分割容器
r=takeboxes(NR,container,2); % 将位于容器内部的字符区域提取出来
elseif length(Y)==1
MP=R(Y);
binsize=R(2)-R(1);
container=[MP-(binsize/2) MP+(binsize/2)];
r=takeboxes(NR2,container,2.5);
elseif isempty(ind) || length(ind)>1% 如果分割容器为空
[A,B]=hist(NR(:,2),20);
ind2=find(A==6);
if length(ind2)==1
MP=B(ind2);
binsize=B(2)-B(1);
container=[MP-(binsize/2) MP+(binsize/2)];
r=takeboxes(NR,container,1);
else
container=guessthesix(A,B,(B(2)-B(1))); % 根据面积直方图和区间大小猜测分割容器的位置
if ~isempty(container)% 如果分割容器不为空,将位于容器内部的字符区域提取出来
r=takeboxes(NR,container,1);
elseif isempty(container)
container2=guessthesix(E,R,(R(2)-R(1)));
if ~isempty(container2) % 如果分割容器不为空,将位于容器内部的字符区域提取出来
r=takeboxes(NR2,container2,2.5);
else
r=[]; % 如果分割容器为空,返回空矩阵
end
end
end
end
function container=guessthesix(Q,W,bsize)
for l=5:-1:2
val=find(Q==l);
var=length(val);
if isempty(var) || var == 1% 如果出现次数为l的高度值的个数为空,或者等于1
if val == 1
index=val+1; % 计算要查找的位置
else
index=val;
end
if length(Q)==val% 如果要查找的位置是直方图的最后一个位置,将查找位置置为空
index=[];
end
if Q(index)+Q(index+1) == 6 % 如果查找位置及其相邻的位置出现次数之和等于6
container=[W(index)-(bsize/2) W(index+1)+(bsize/2)];% 创建一个分割容器
break;
elseif Q(index)+Q(index-1) == 6 % 如果查找位置及其前一个位置出现次数之和等于6
container=[W(index-1)-(bsize/2) W(index)+(bsize/2)]; % 创建一个分割容器
break;
end
else% 如果出现次数为l的高度值的个数大于1
for k=1:1:var
if val(k)==1 % 计算要查找的位置
index=val(k)+1;
else
index=val(k);
end
if length(Q)==val(k) % 如果要查找的位置是直方图的最后一个位置,将查找位置置为空
index=[];
end
if Q(index)+Q(index+1) == 6 % 如果查找位置及其相邻的位置出现次数之和等于6
container=[W(index)-(bsize/2) W(index+1)+(bsize/2)]; % 创建一个分割容器
break;
elseif Q(index)+Q(index-1) == 6 % 如果查找位置及其前一个位置出现次数之和等于6
container=[W(index-1)-(bsize/2) W(index)+(bsize/2)];% 创建一个分割容器
break;
end
end
if k~=var% 如果找到分割容器,退出循环
break;
end
end
end
if l==2% 如果循环结束后没有找到分割容器,将分割容器置为空
container=[];
end
function letter=readLetter(snap)
load NewTemplates% 加载新的模板
snap=imresize(snap,[42 24]);% 将图像缩放为指定大小
comp=[ ];% 初始化一个空数组
for n=1:length(NewTemplates)% 对于每个模板
sem=corr2(NewTemplates{1,n},snap);% 计算当前模板与图像的相关性
comp=[comp sem];% 将相关性值添加到数组中
end
vd=find(comp==max(comp));% 找到相关性值最大的位置
if vd==1 || vd==2% 根据不同的位置,将字母或数字赋值给letter变量
letter='A';
elseif vd==3 || vd==4
letter='B';
elseif vd==5
letter='C';
.......................................................................
else
letter='0';
end
function r=takeboxes(NR,container,chk)
takethisbox=[];% 初始化一个空数组
for i=1:size(NR,1)% 对于每个数字区域
if NR(i,(2*chk))>=container(1) && NR(i,(2*chk))<=container(2)% 如果数字区域的中心点在分割容器内部
takethisbox=cat(1,takethisbox,NR(i,:));% 将该数字区域添加到数组中
end
end
r=[];% 初始化一个空数组
for k=1:size(takethisbox,1)% 对于每个数字区域
var=find(takethisbox(k,1)==reshape(NR(:,1),1,[]));% 找到该数字区域的行号
if length(var)==1% 如果只有一个数字区域与该行匹配
r=[r var];% 将该数字区域的列号添加到数组中
else% 对于每个匹配的数字区域
for v=1:length(var)% 判断该数字区域的中心点是否在分割容器内部
M(v)=NR(var(v),(2*chk))>=container(1) && NR(var(v),(2*chk))<=container(2);
end
var=var(M);% 选出中心点在分割容器内部的数字区域
r=[r var];% 将这些数字区域的列号添加到数组中
end
end

 浙公网安备 33010602011771号
浙公网安备 33010602011771号