

filebeat-kafka日志收集
filebeat-kafka日志收集
由于线上的logstash吃掉大量的CPU,占用较多的系统资源,就想找其它的组件替代.我们的日志需要收集并发送到kafka,生成的日志已经是需要的数据,不用过滤.经过调研发现filebeat也支持发往kafka.
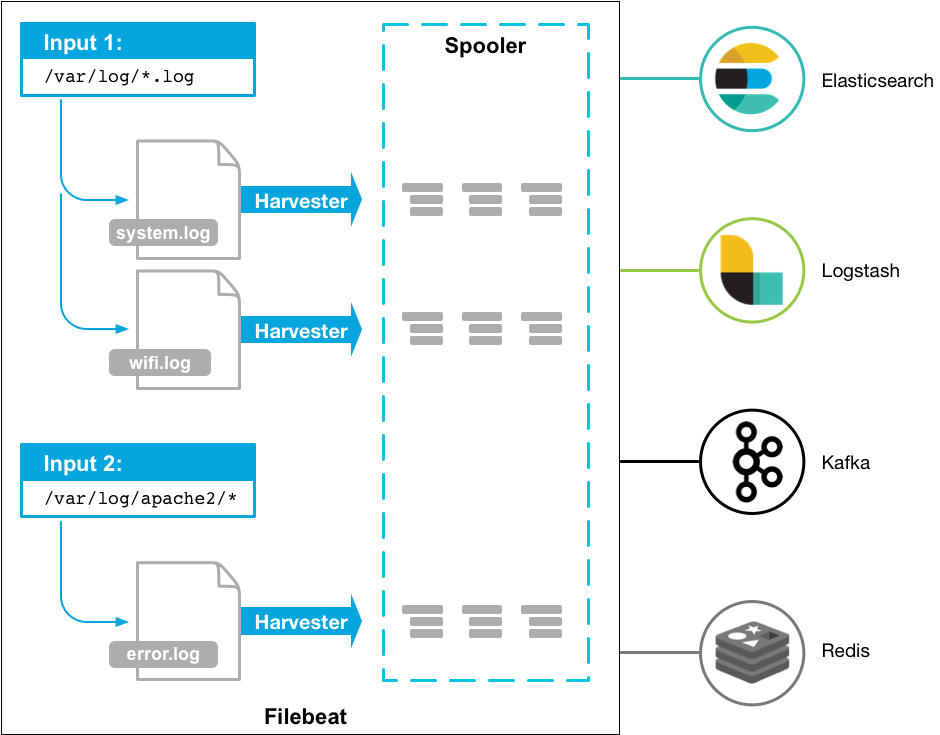
filebeat很轻量,用于转发和收集日志数据.filebeat作为代理安装在服务器上,监视指定的日志文件或位置,收集日志事件,并将他们转发到logstash,elasticsearch,kafka等.架构图如下:
安装
获取安装包并解压
# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.5.1-linux-x86_64.tar.gz
# tar -xvf filebeat-6.5.1-linux-x86_64.tar.gz
配置
filebeat支持很多种输入和输出.具体可看input,output.
项目中用到的输入是log,输出的kafka.在这只讲这两种配置.
输入配置log
log输入是从文件中按行读取.在paths指定需要监视的文件.
例子:
filebeat.inputs:
- type: log
paths:
- /var/log/messages
- /var/log/*.log
主要有以下几个配置项.
paths
需要监视的文件路径.支持Go Glab的所有模式.例如: /var/log/*.log.这个配置将监视/var/log文件夹下所有以.log结尾的文件.可以用recursive_glob来递归子文件夹.
recursive_glob.enabled
允许扩展 * * 为递归的glob模式.启用此功能后. /foo/* * 扩展到/foo, /foo/* ,/foo/* /* ,等等,它会将单个扩展 * * 为8级深度*模式.
默认情况下启用此功能.设置false禁用.
exclude_lines
正则表达式列表,用于匹配您希望Filebeat排除的行.Filebeat会删除与列表中的正则表达式匹配的所有行.默认情况下,不会删除任何行.空行被忽略.
以下示例将Filebeat配置为删除任何以DBG开头的行:
filebeat.inputs:
- type: log
...
exclude_lines: ['^DBG']
include_lines
正则表达式列表,用于匹配您希望Filebeat包含的行.Filebeat仅导出与列表中的正则表达式匹配的行.默认情况下,将导出所有行.空行被忽略.
以下示例将Filebeat配置为导出以ERR或WARN开头的所有行:
filebeat.inputs:
- type: log
...
include_lines: ['^ERR', '^WARN']
PS: 如果include_lines和exclude_lines两个配置同时出现,优先执行inlcude_lines再执行exclude_lines.和配置项放的位置没有关系.
json
filebeat支持json格式的消息日志.它将逐行处理日志,因此只有每行有一个json对象时,json解码才有效.
配置示例:
json.keys_under_root: true
json.add_error_key: true
json.message_key: log
enabled
输入开关.默认true打开.
输出配置kafka
kafka将输出流发送到Apache Kafka.
配置示例:
output.kafka:
# initial brokers for reading cluster metadata
hosts: ["kafka1:9092", "kafka2:9092", "kafka3:9092"]
# message topic selection + partitioning
topic: '%{[fields.log_topic]}'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000
主要以下几个配置项
enabled
是否打开输出配置项.true打开,false关闭.默认是true.
hosts
kafka的broker地址.
topic
kafka的topic.
worker
并发负载均衡Kafka输出工作线程的数量.
timeout
kafka返回应答的等待时间.默认30(秒).
keep_alive
连接的存活时间.如果为0,表示短连,发送完就关闭.默认为0秒.
required_acks
ACK的可靠等级.0=无响应,1=等待本地消息,-1=等待所有副本提交.默认1.
PS: 如果设为0,kafka无应答返回时,消息将丢失.
配置例子
#=========================== Filebeat inputs =============================
#------------------------------log-----------------------------------
filebeat.inputs:
- type: log
enabled: true
paths:
- /data/collect_log/info.*
#=========================== Filebeat outputs =============================
#------------------------------kafka-----------------------------------
output.kafka:
hosts: ["test1:9092","test2:9092"]
topic: test_collect
keep_alive: 10s
收集/data/collect_log目录下以info开头的文件,发送到kafka,kafka的topic是test_collect.
启动
# /home/filebeat -c filebeat-kafka.yml
日志在filebeat下的log目录.想要显示的看日志启动时加 -e 参数.
参考文档: https://www.elastic.co/guide/en/beats/filebeat/current/configuring-howto-filebeat.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号