
【爬虫】001-python +requests+beautifulsoup4 简单爬取
实验环境:win7 python3.5 request 2.19.1
时间:2018-08-07
一、爬取 http://china.nba.com/statistics/ 表格数据
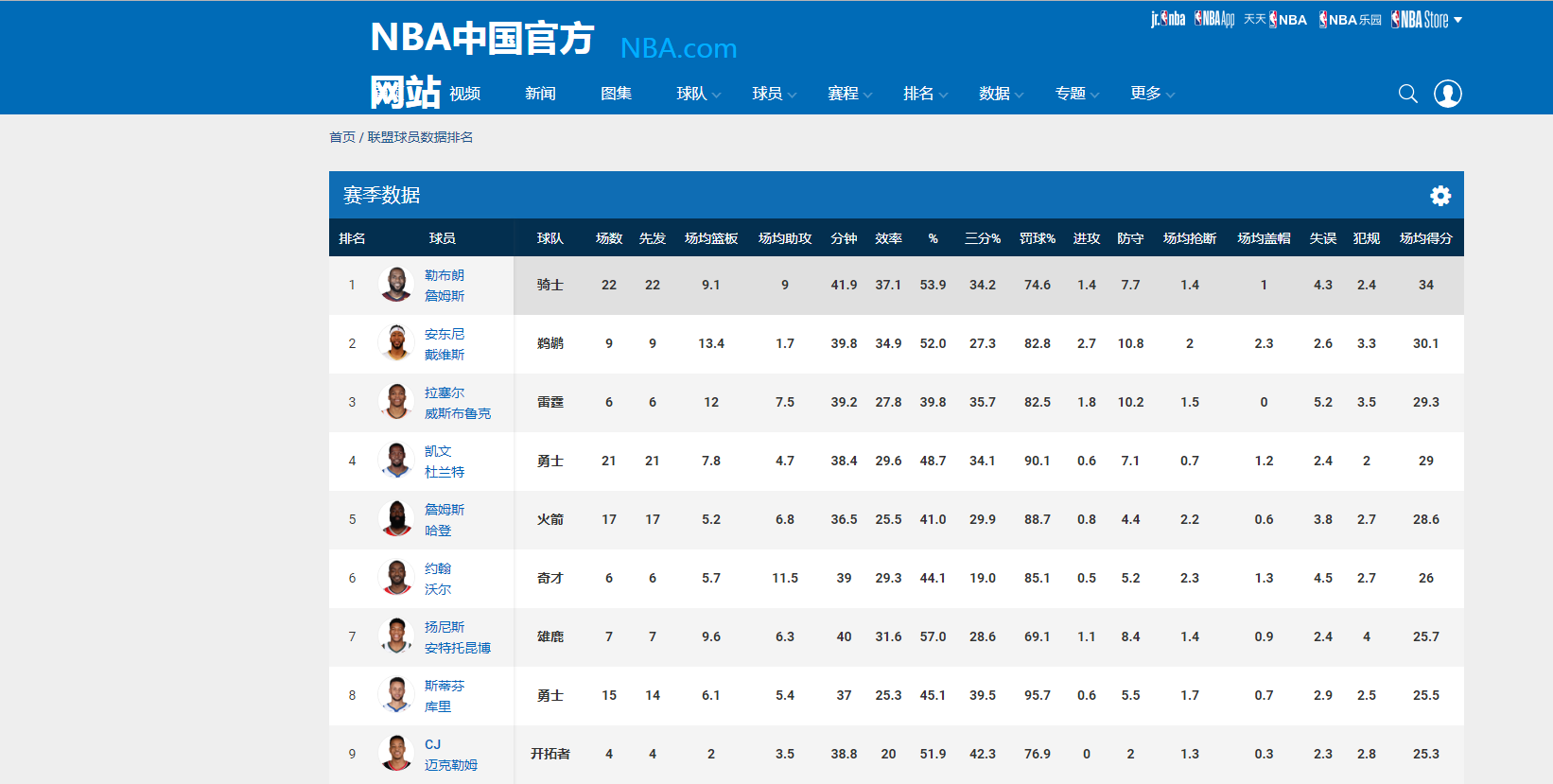
在这个案例中,直接get("http://china.nba.com/statistics/ "), 是得不到以上那个页面的;因为这个页面不是直接返回的静态页面,而是在浏览器端渲染的; get得到的是浏览器渲染之前的页面;
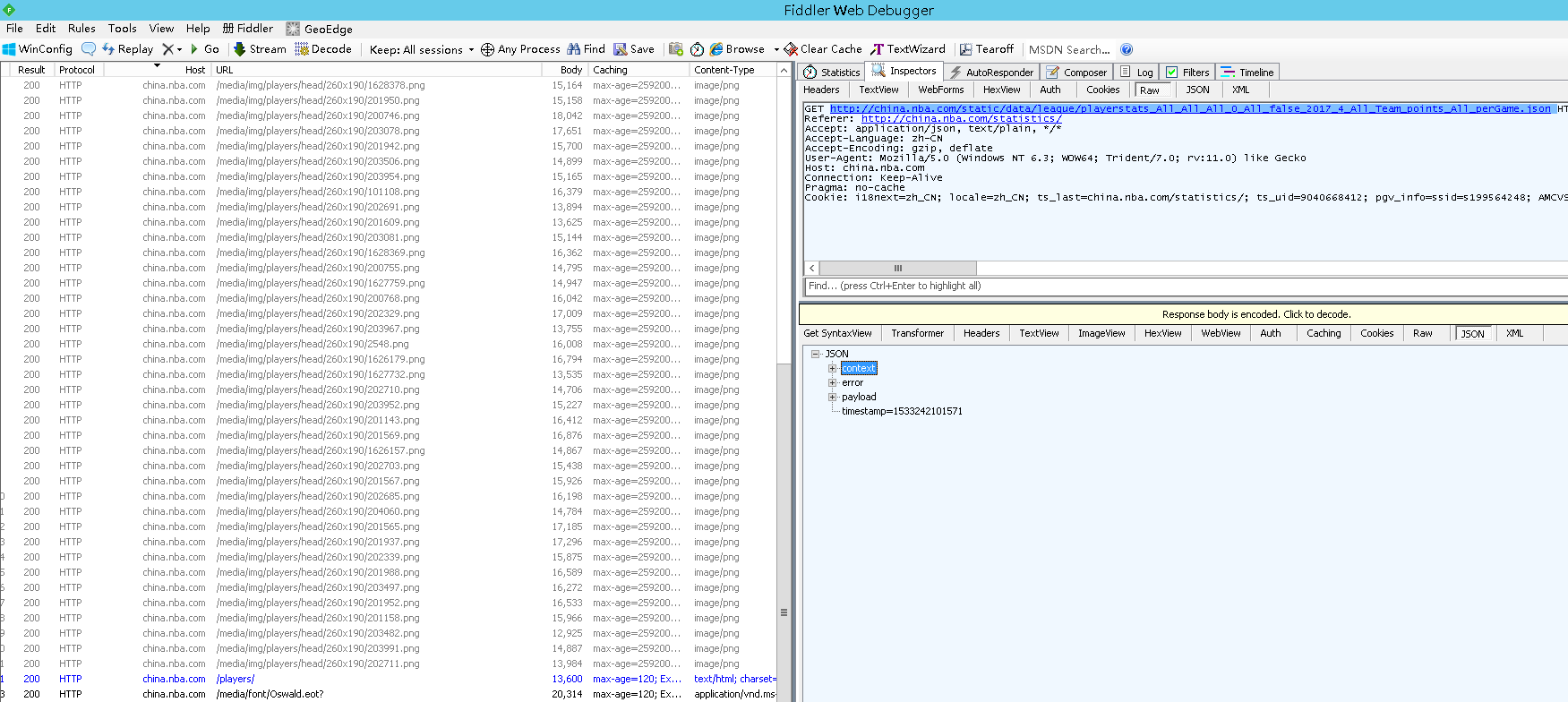
解决方案: 用Fiddler 查看服务器返回的所有报文,从中找到含球员数据的那个报文;一般来说,content-Type 为application/json 是重点排查对象;
最终找到服务区器返回了一个
http://china.nba.com/static/data/league/playerstats_All_All_All_0_All_false_2017_4_All_Team_points_All_perGame.json
这个数据里含有页面上展示的数据
总体爬取流程:
Fiddler 分析网站交互过程 + 找到满足需求的返回报文 +解析数据
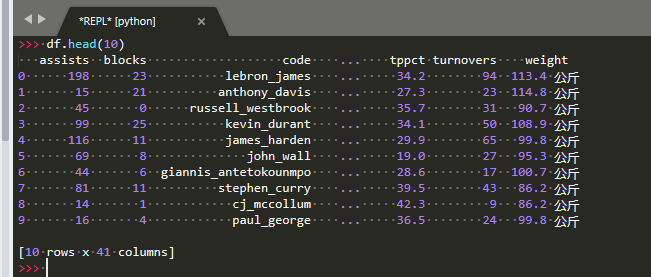
import requests
import bs4
import pandas as pd
url="http://china.nba.com/statistics/"
url1="""http://china.nba.com/static/data/league/playerstats_All_All_All_0_All_false_2017_4_All_Team_points_All_perGame.json"""
r=requests.get(url1)
players=r.json()['payload']['players']
data=[ dict(w['playerProfile'],**w['statTotal']) for w in players]
df=pd.DataFrame(data=data)
当然这种方法的缺陷,也是很明显的;要求你对web交互过程有深入的了解,比如这里的页面渲染是基于angularjs的;有的时候,需要你模拟渲染过程;
同时也因为不管渲染过程,优点是快。
有没有办法直接获取渲染后的静态html呢;答案是肯定的 selenium+python +浏览器 ,让浏览器来渲染,直接获取渲染后的html;
请看后续博文

 浙公网安备 33010602011771号
浙公网安备 33010602011771号