代码质量(1): C/C++测试覆盖率分析工具的分层
软件都有分层,C/C++代码的覆盖率工具亦如此。我们从测试覆盖率工具的分层,来理解工程上十分普遍分层概念,而在工具链上,这点又常常容易被忽视。
一个简单的例子,C/C++的基本测试覆盖率介绍
源代码main.cpp:
#include <stdio.h>
void test_1(){
int arr[] = {0,2,4,8};
for(size_t i=0;i<sizeof(arr)/sizeof(int);i++){
if(i%2==0){
printf("2: %d,",arr[i]);
}else{
printf("1: %d,",arr[i]);
}
}
}
void test_2(){
printf("test2");
}
int main(){
test_1();
// test_2();
return 0;
}
编译:gcc -g -fprofile-arcs -ftest-coverage main.cpp
此时,目录结构如下,GCC生成了一个main.gcno文件:
main.cpp
main.gcno
a.out
执行:./a.out
此时,目录结构如下,程序运行后生成了一个 main.gcda 覆盖率文件
main.cpp
main.gcno
main.gcda
a.out
调用 gcc 的 gcov 命令统计代码覆盖率:gcov main.cpp -m
命令行输出:
File 'main.cpp'
Lines executed:81.25% of 16
Creating 'main.cpp.gcov'
可以看到,代码有81.25%的行被执行到,实际看下详细的main.cpp.gcov
-: 0:Source:main.cpp
-: 0:Graph:main.gcno
-: 0:Data:main.gcda
-: 0:Runs:5
-: 0:Programs:1
-: 1:#include <stdio.h>
-: 2:
5: 3:void test_1(){
5: 4: int arr[] = {0,2,4,8};
25: 5: for(size_t i=0;i<sizeof(arr)/sizeof(int);i++){
20: 6: int value = arr[i];
20: 7: if(value%2==0){
18: 8: printf("2: %d\n", value);
18: 9: }else{
2: 10: printf("1: %d\n", value);
-: 11: }
20: 12: }
5: 13:}
-: 14:
#####: 15:void test_2(){
#####: 16: printf("test2");
#####: 17:}
-: 18:
5: 19:int main(){
5: 20: test_1();
-: 21: // test_2();
5: 22: return 0;
-: 23:}
可以看到 test_2 函数前面都打了井号,表示这几个代码根本就没被跑到。
gcovr 的覆盖率指标line, function, branch, decision
如果只用GCC的gcov,只能获得.gcov 文本数据,进一步的前端分析工具有lcov和gcovr,其中lcov是用perl写的,不利于进一步的开发定制和维护,gcovr则是用python写的,建议选用gcovr做C/C++的测试覆盖率前端工具链。
gcovr 统计四种不同的覆盖率,分别是 line, function, branch, decision,每一种类型的覆盖率定义在本文档给予必要的说明。
Line 行覆盖率
分母:编译到可执行程序里的没有被优化的代码行总数,不包括声明和定义代码行,例如函数定义,类定义代码行。
分子:实际被执行到的代码行。
Function 函数覆盖率
分母:编译到可执行程序里没有被内联(inline) 的函数总数。
分子:被执行到的函数的总数。
这个分母和分子受内联和编译优化影响:
- 内联关键字: inline,优化选项:-O2 -O3 都可能会导致分母减少。
- 而如果使用禁止内联编译选项:-fno-inline 以及禁止优化-O0,则可以统计到准确的分母。
实际项目编译选项基本都是-O2以上,以及有许多内联的使用,所以分母是比实际的函数总是略少。
Branch 分支覆盖率
分母:if, switch, for, while 等语句里的逻辑操作符,bool 判断导致的逻辑判断分支总数
分子:if, switch, for, while 等语句里的逻辑判断分支被触达到的总数
https://www.gcovr.com/en/stable/faq.html
实际上,这个branch不是程序员通常所理解的高级语言代码块的分支,而是由C/C++代码编译后的汇编语句形成的控制流图control flow graph (CFG)的逻辑分支。根据 gcovr 的文档,branch的统计也受编译器的各种参数的影响,几乎不可能做到100%。
可以简化理解:
假设if中包含3个判断语句,每一个判断语句有2个状态:true或者false;总的brach数量=3*2=6
例子:
if(x > 0 && y > 0){
x = x + y;
}else{
x = x - y;
}
使用https://godbolt.org/ 查看汇编代码,下面的例子branch覆盖率是 2/4
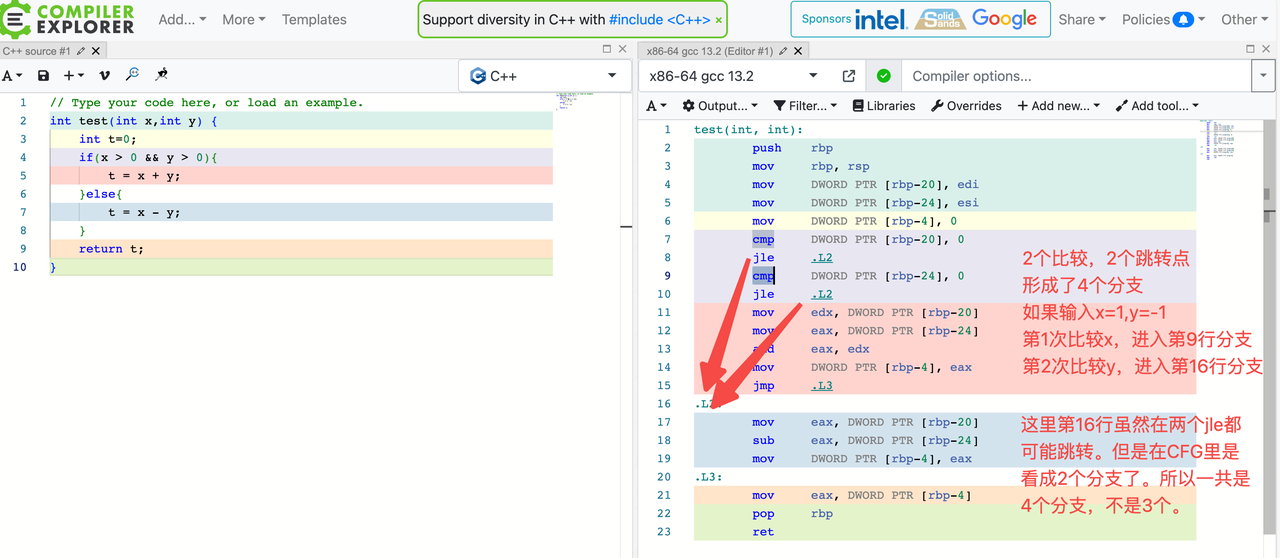
Decision 决策覆盖率
分母:if, switch, for, while 的条件语句的可能结果,一般只有 true/false两种
分子:if, switch, for, while 的条件语句的实际执行结果数。所以一般是 0/2, 1/2, 2/2
实际上,这个 decision 反而更接近于程序员通常所说高级语言里直接看到的代码块「分支」总数。
但是似乎 gcov 生成的数据,对于某些略微复杂的情况,gcovr无法分析 decision 的分母总数。
Gcovr Branch vs Decision 例子
我们以这段代码为例子:
if(x > 0 && y > 0){
x = x + y;
}else{
x = x - y;
}
a) If-else 例子1
测试用例:test_1(-1, -1);

解释:
- 对于 decision 来说,if 语句只有一个决策点(true/false),因此分母是2,false被执行到,因此是1/2
- 对于 branch 来说,有4个逻辑判断分支,只有1个分支触达,因此是 1/4
- x>0
- y>0
- y<=0
- x<=0
- x>0
b) If-else 例子2
测试用例:test_2(1, -1);

解释:
- 对于 decision 来说,if 语句只有一个决策点(true/false),因此分母是2,false被执行到,因此是1/2
- 对于 branch 来说,有4个逻辑判断分支,有两个分支触达,因此是2/4
- x>0
- y>0
- y<=0
- x<=0
- x>0
c) If-else 例子3
测试用例:test_3(-1, 1 );

解释:
- 对于 decision 来说,if 语句只有一个决策点(true/false),因此分母是2,true被执行到,因此是1/2
- 对于 branch 来说,有4个逻辑判断分支,有1个分支触达,因此是1/4
- x>0
- y>0
- y<=0
- x<=0
- x>0
d) If-else 例子4
测试用例:test_4(1, 1 );

解释:
- 对于 decision 来说,if 语句只会导致2个代码块,因此分母是2,其中一个代码块被执行到,因此是1/2
- 对于 branch 来说,有4个逻辑判断分支,有2个分支触达,因此是2/4
- x>0
- y>0
- y<=0
- x<=0
- x>0
e) If-else 例子5
进一步验证,增加一个变量,z,测试用例:test_5(1, -1, 0);

解释:
- 对于 decision 来说,if 语句只有一个决策点(true/false),因此分母是2,false被执行到,因此是1/2
- 对于 branch 来说,有6个逻辑判断分支,有2个分支触达,因此是2/6
- x>0
- y>0
- z==0
- z!=0
- y<=0
- y>0
- x<=0
- x>0
f) If-else 例子6
测试用例,本次我们让z的判断能被执行到:test_6(1, -1, 0);

解释:
- 对于 decision 来说,if 语句只有一个决策点(true/false),因此分母是2,false被执行到,因此是1/2
- 对于 branch 来说,有6个逻辑判断分支,有3个分支触达,因此是3/6
- x>0
- y>0
- z==0
- z!=0
- y<=0
- y>0
- x<=0
- x>0
g) 例子7,switch语句
对于 swich case来说,在case语句是决策点,swithc语句行是分支点。
checkSwitch1(5);
checkSwitch2(10);
checkSwitch3(0);
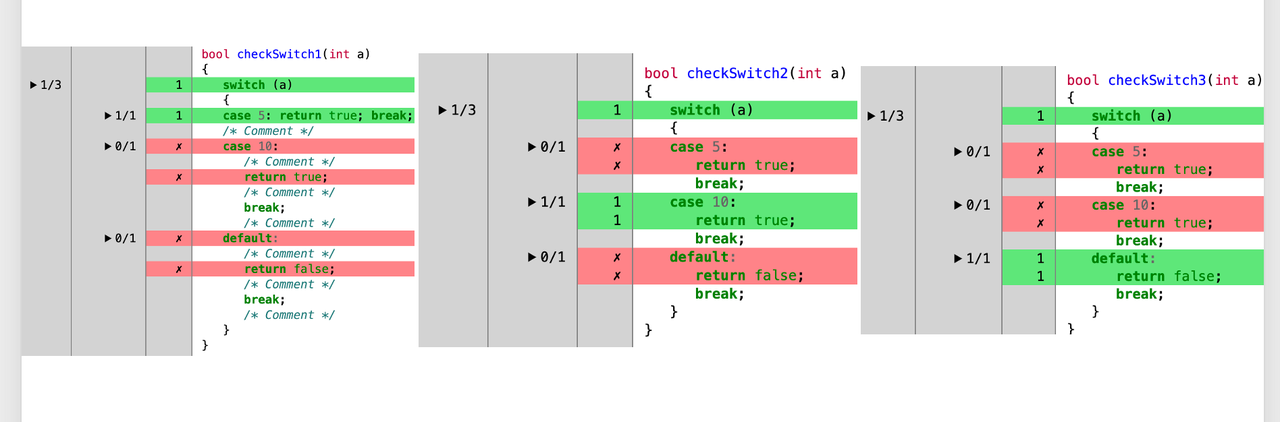
h) 例子8,for 语句
测试用例:checkForLoop(5);

i) 例子9,while/dowhile 语句
测试用例:

MD/MC 覆盖率
a) 根据 gcovr 官方文档:https://www.gcovr.com/en/stable/faq.html
gcovr 的 decision 就是c++程序员认为的 “branches”:
With the gcovr --decisions option, gcovr parses the source code to extract a ISO 26262 compliant metric for decision coverage. This metric can be interpreted as the branch coverage on C/C++-Level. While the feature is not always able to detect the decisions reliabily when the code is written very compact (uncheckable decisions will be marked), it provides a reliable tool for (i.e. MISRA-compliant) code in security-relevant situations.
b)同时实际上 gcovr 的branchs 是在汇编代码的 CFG(控制流图)上做的,它的branch是CFG的arc
What gcovr calls a branch is in fact an arc between basic blocks in the CFG. This means gcovr’s reports have many branches that are not caused by if statements! For example:
- Arcs are caused by C/C++ branching operators: for, if, while, switch/case, &&, ||, ? :. Note that switches are often compiled as a decision tree which introduces extra arcs, not just one per case.
- (Arcs into another function are not shown.)
- Arcs are caused when a function that may throw returns: one arc to the next block or statement for normal returns, and one arc to an exception handler for exceptions, if this function contains an exception handler. Every local variable with a destructor is an exception handler as well.
- Compiler-generated code that deals with exceptions often needs extra branches: throw statements, catch clauses, and destructors.
- Extra arcs are created for static initialization and destruction.
- Arcs may be added or removed by compiler optimizations. If you compile without optimizations, some arcs may even be unreachable!
c)而 gcovr 一开始是没有 decision 这个选项的,后面有个开发者有这个需求就加了:
https://github.com/gcovr/gcovr/pull/350
d) 严格的说,gcovr 的 branches 更接近于 MD/MC 标准:https://maskray.me/blog/2024-01-28-mc-dc-and-compiler-implementations
gcovr依赖gcc 的 gcov来从.gcno和.gcda获得数据,gcov需要在比较高的版本才有严格的MD/MC覆盖率支持,通过编译时增加 --fcondition-coverage ,数据分析给gcov增加 --conditions 来实现。
Jørgen Kvalsvik posted the first MC/DC patch to gcov in March 2022 and PATCH v9 in December 2023. With this patch, we compile source files using gcc --coverage -fcondition-coverage and pass --conditions to gcov. The output should look like:
测试覆盖率的工具链分层
最底层是GCC支持的编译和收集两个底层:
- 编译选项:-g -fprofile-arcs -ftest-coverage
- 收集工具:gcov, gcov-tool
往上一层是覆盖率报告生成工具,有几种:
- lcov, Linux 的覆盖率报告就是用这个生成的,有1.x版本和2.0版本。这个都是用perl 写的,但是它 2.0版本只有预编译了centos的rpm包,没有ubuntu的dep包,安装非常慢。而且,这个工具只输出html 格式,不利于结构化处理。
- gcovr,使用Python写的,内部也是对 gcov 处理结果的二次处理。这个工具可以输出 html、cvs、json等丰富的格式。Python项目也更有利于按需修改。缺点是官方对于bug的修复不是很积极。
用户层,如果用户要做覆盖率统计,多半是需要基于 lcov/gcor > gcov 做进一步的封装,得到一个自己的 xxx_cov 工具或者系统。分层结构是: xxx_cov > gcovr/lcov > gcov/gcov-tool
这就是工具的分层。我们再看另外一个例子,编译工具链的分层:
- 单项目的基本工具链分层:CMake > Makefile/Ninja > gcc/clang/msvc
- 如果考虑多项目,以及开发者增加的上层构建系统封装xx_build_sytem。分层结构大概是这样:xxx_build_sytem > conan > cmake > makefile, ninja > gcc/clang/msvc
进一步,考虑研发系统里面会有下游的流水线,例如自动化编译、测试、报表平台,这些平台:
- 带有服务化的能力
- 背后有数据库来存储各环节元数据
- 有可视化平台显示编译、测试、查询视图
- 进一步应该有一系列的 Web API 方便编程的方式来集成。
把这样的服务化系统看作是 Build & Test Server。那么整体的分层结构是:
- build+test-server > continue integration, continue test suite, build system manager view, build system api > xxx_build_system + xxx_cov > ...
这个和其他系统的MVC分层有类似的地方:
- 数据层(对应上述描述的B&T服务的元数据存储,以及工具链构建出来的文件结构化数据和其他非二进制数据)
- 逻辑层(上述描述的工具链分层的每层的逻辑代码在这里)
- 视图层(对应B&T的Web UI以及命令行UI)
分层的好处
软件开发的难点之一就是治理复杂度。软件开发的一个法则就是:任何一个问题都可以通过增加一个抽象层解决。工具链的分层,也是层层把构建、测试、覆盖统计等工具链的复杂划分到不同层去解决。使得不同层尽可能只要专注在解决自己想要解决的哪层问题。向下,依赖下层工具的能力,向上,暴露本层工具提供的能力。
分层带来的问题
首先,对于构建、测试、收集工具来说,分层也带来一些问题:
- 越底层的工具链,一般是直接的命令行或者脚本系统,属于可编程部分。
- 越上层的管理系统,一般是可视化的UI系统,如果没有强制在设计中贯彻「功能都应该有开放API」,那么上层可视化UI系统的可编程能力弱,到上层做自动化工作反而变的困难,需要涉及很多与不同小组的人之间的「走流程」的部分。反之,如果设计上贯彻「重要功能都有可编程API」,那么整个系统的自动化编程能力就会有很大不同,单个人就能完成某个自动化功能从底层到上层的全链路开发。
其次,由于工具链涉及的技术卡点往往比较碎,特别是在工具链命令行这层解决的问题往往用的都不是常规编程语言技术栈,这里的卡点问题耗时会有许多不确定的地方。
- 例如C++系统的工具链,需要你熟悉/精通 C++语言,但是你日常写的是conan的配置,CMake的配置,Makefile的配置,Python的脚本系统,以及需要处理构建、测试的机器的操作系统、容器、脚本、环境变量、包管理等dirty work,此外还需要理解各种系统运行的单机、分布式机器的物理拓扑结构,处理同构和异构的环境。
- 在这个过程中,你需要掌握和处理许多方言,而不只是会C/C++语言,这个就是实际工程和学校编程语言教学之间比较大的差异。
第三,当你在设计和实现这样的系统过程中,常常需要来回在底层和上层之间游动解决问题。
- 一开始你在下层验证功能的能力,这部分可能就消耗点你许多时间。
- 当你觉得下层的工作准备好了,开始做上层的工作,乐观主义使得上层的工作可以接入。
- 当你做了上层的集成,把流程跑通,这个过程中会反复发现下层功能的问题
- 回到下层,继续诊断和解决问题,这里可能又消耗了许多时间。
- 当下层问题改进后,再次回到上层推进问题。
- 于此同时,其他使用系统的用户可能随时希望这个可以尽快ready。
- 数据量的问题,当你只有一个 hello world 的时候很简单,当你有100w+代码和100+子项目的时候,数据量和系统会带来更多复杂性,以及在PPT上看不到的编译、链接耗时成本。
- 诸如此类...
参考资料:
[1] GCC提供的基本的覆盖率编译选项和收集工具gcov:https://gcc.gnu.org/onlinedocs/gcc/Gcov-Data-Files.html, https://gcc.gnu.org/onlinedocs/gcc/Gcov.html
[2] clion里的覆盖率工具支持:https://www.jetbrains.com/help/clion/code-coverage-clion.html
[3] Perl写的lcov覆盖率收集工具,Linux的覆盖率收集使用lcov,本质上下层调用的是gcov:https://github.com/linux-test-project/lcov
[4] Python写的覆盖率分析工具gcovr,下层调用的是gcov:https://github.com/gcovr/gcovr
[5] gcovr的文档:https://gcovr.com/en/stable/
[6] Rust写的覆盖率分析工具grcov: https://github.com/mozilla/grcov
--end--

 浙公网安备 33010602011771号
浙公网安备 33010602011771号