

雪花算法(snowflake)作分库分表shard key,数据倾斜,分表不均问题
之前有一篇文章介绍分布式id生成粗略选型,提到雪花算法作为一个优秀的方案,满足了我们在分布式下的id生成需求。但如果直接把雪花算法生成的id作为分表键(shard key)在低并发下是会有问题的。下面来一起看下。
现象
我们分表数量是256张表(tb_0,tb_1,tb_2...tb_255),分表规则用雪花算法生成的id对256取余(snowflakeId % 256)。跑了一段时间后,发现,数据总数落到256中的前几张表(tb_0,tb_1等下标值小的表里),后面下标值大的表则几乎无数据,发生了分表倾斜。
分析
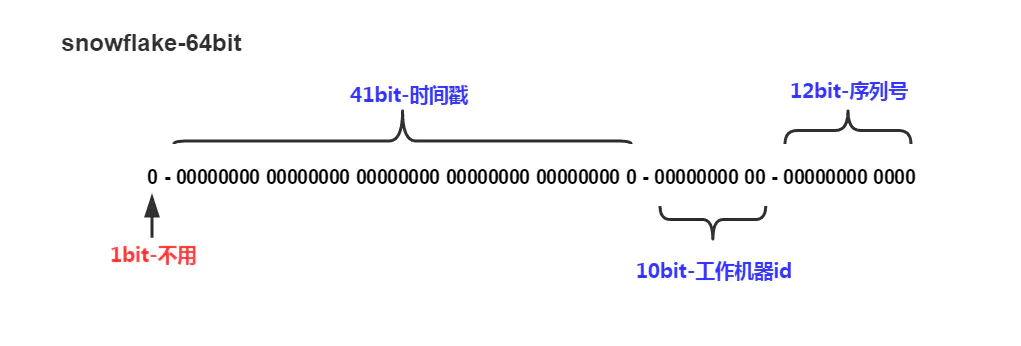
回到算法本身,如前文分布式id生成粗略选型介绍所述,雪花算法是由三部分组成,高位的时间戳,中间的机器编号,加低位的自增序列。我们重点关注低位的自增序列。
生成最终id核心实现代码
return ((currentMillis - EPOCH) << 22) | (workerId << 12) | sequence;
按照算法的实现(实现代码可以百度,一大把),12 bit自增序列号可以表示 2^12 = 4096 个 ID,所以理论上每毫秒(注意是每毫秒ms)的自增长序列(sequence)都从0开始,到4095为止。如果到了4095,则重新从0开始循环(毫秒值也进入下一毫秒)。说到这里是不是发现什么了?再划下重点————每毫秒都是从0开始。核心实现

//如果是同一时间生成的,则进行毫秒内序列 if (lastTimestamp == timestamp) { sequence = (sequence + 1) & sequenceMask; //毫秒内序列溢出 if (sequence == 0) { //阻塞到下一个毫秒,获得新的时间戳 timestamp = tilNextMillis(lastTimestamp); } } //时间戳改变,毫秒内序列重置 else { sequence = 0L; }
那么我们来看下低并发下的结果表现(高低并发怎么界定?TPS低于1000的都算吧,而其实很多业务系统的单机TPS是达不到1000的)。由于系统并发比较低,每次请求毫秒数几乎都不同,那么,sequence都是0,或者很小的数字。所以,就导致算法生成的id分表后基本集中在前几个下标小的分表里。
解决方案
美团点评的实现里(核心类https://github.com/Meituan-Dianping/Leaf/blob/master/leaf-core/src/main/java/com/sankuai/inf/leaf/snowflake/SnowflakeIDGenImpl.java)其实有对这个问题做过优化,关键优化代码
sequence = RANDOM.nextInt(100);
就是对每毫秒起始的sequence取随值,美团的随机范围是0到100。最终的效果就是生成的id会均匀分布在tb_0到tb_100。而我们如果分表数是256,则需要改成
sequence = RANDOM.nextInt(256);
总结
雪花算法是一个优秀的分布式id生成算法,而且为高并发设计。如果直接将雪花算法的id用作分库分表的shard key,需要注意业务系统在低并发下分表不均的问题,解决方案也在上面给出。控制算法低位的序列始终在一个范围(分表数)内,随机生成。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构