常用ctr算法比较
- 什么是点击率预估?
ctr的主要任务是预测用户点击某个广告的概率,一般是一个二分类问题,通常需要面对海量的样本和特征,所以算法的效率和性能都比较关键。 - 评估指标是什么?
以kaggle上的一个比赛为例(https://www.kaggle.com/c/outbrain-click-prediction/overview/evaluation),该比赛的任务是给定 display_id和ad_id,判断用户点击这个ad_id的概率(display_id应该是与用户相关的),该任务采用的评估指标是 MAP@12(mean average precision),具体的公式如下所示:
![]()
其中|U|是总的display_id的数目,|n|是预测的ad_id的数目,k是cutoff,p(1)表示取每个display_id里得分最高的ad_id看准确率,所以p(k)就表示取每个display_id中概率最高的前k个ad_id作为候选,判断其中有没有用户真实点击的ad_id,并计算准确率。

常用算法比较:
-
lr
优点:简单,高效
缺点:线性模型,无法自动处理特征间的交叉关系,需要手动做特征工程 -
fm
在lr的基础上加入了自动对特征间的交叉关系建模的二阶特征,避免了手动特征工程的繁琐,每个特征都需要学习一个k的隐空间向量,特征两两之间的交叉项系数等于对应特征隐空间向量的内积。 -
ffm
由于ctr预估中的特征通常都是离散的,所以通常需要对特征做one-hot编码,所以可以对one-hot的编码特征进行分组(分为多个field),由同一个原始特征编码出来的one-hot特征属于同一个field。假设有k个field,之前在fm中每个特征都只需要学习一个隐空间向量,这就意味着这个特征在与其他不同field特征相交叉时用的是同一个隐空间向量进行内积。ffm的做法是对每个特征都学习k个隐空间向量,这样每个特征在与其他各个不同field的特征交叉时能自适应得学习到最优的隐空间向量,ffm的参数明显比fm多,所以ffm模型的表达能力比fm强。 -
ftrl
其实ftrl本质上与上述的lr,fm和ffm并不在一个层级上,fm和ffm都是一种建模算法,而ftrl本质上是一种优化算法,ftrl也可以用来优化fm和ffm。不过最常用的是用ftrl来优化lr来获得稀疏解。在各类机器学习训练任务中,为了避免过拟合,通常会在目标函数上增加L2范数的正则项以提高泛化性,另一种常用的正则项是L1范数,其能起到特征选择的作用。对于添加了L2范数的损失函数,一般的sgd优化算法就能较好得优化,对于L1范数,虽然其也是凸函数,但是由于L1范数在零点不可导,sgd在优化时通常会用次梯度代替梯度。但是使用次梯度在优化很难获得稀疏解(为什么?),而这催生了一些针对求解稀疏解的在线最优化算法。
如:截断梯度法,FOBOS算法,RDA算法以及FTRL算法。它们本质上都是优化算法,可以作用于大部分使用了稀疏正则项的目标函数中。这类算法主要适用的场景时高维高数据量的场景,解的稀疏性一方面起到了特征选择的作用,另一方面能够加速预测时间。
ftrl算法是基于多个算法发展而来,我从头捋一遍(参考冯扬的《在线最优化求解》,具体细节可以看那篇文章):-
L1正则化法
梯度下降时对L1范数用的是次梯度进行更新,而这会导致求得的系数没有稀疏性。 -
简单截断法
每隔K步(t mod K = 0 )都对梯度进行一次截断,其他步(t mod K !=0)按照一般的梯度下降更新参数(不考虑L1范数) -
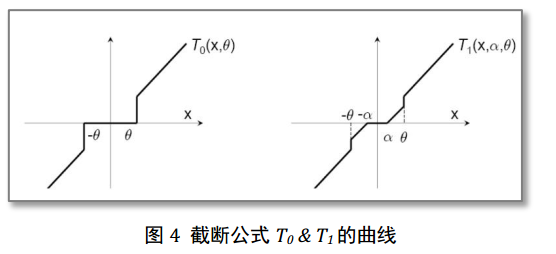
截断梯度法(TG)
截断梯度法与简单截断法比较像,也是每隔K步进行截断,其他步是常规更新参数,与简单截断法不同的是,TG采用的截断函数不同
![]()
-
FOBOS,RDA和FTRL算法
这里这要对比这几种算法的优缺点:
![]()
![]()
![]()
总结一下就是:FOBOS的优点是限制了W的变化不能离已迭代得到的解太远,缺点是产生的解相比RDA求得的解稀疏性不足,且其每次判断是否对每个维度进行截断时只考虑了当次迭代该维度的梯度变化,而RDA则考虑了过去所有迭代该维度梯度变化的平均值,避免了由于当此迭代该维度训练不足引起的梯度截断。RDA的缺点是只限制了W的变化不能离0点太远,而FTRL则结合了FOBOS和RDA的优点。 -
ftrl中,每个维度的学习率是单独考虑的(per-coordinate learning rates)
![]()
-
-
DeepFM
说到deepfm,就要说到神经网络相关算法在ctr方面的进展。为了便于理解,我们从最开始的 矩阵分解算法说起









(一个deepfm讲得比较好的博客:https://blog.csdn.net/w55100/article/details/90295932 )
算法性能比较:
只用了 movielen100k 中的u1.base 作为训练和验证,采用5-fold交叉验证方法评估各个算法在验证集的上mse。u1.base 涉及用户 900+,涉及电影 1600+, 数据量为8w。没有经过特别复杂的调参工作
| 算法 | validation mse |
|---|---|
| fm | 1.18 |
| ffm | 1.20 |
| ftrl | 1.14 |
| deepfm | 1.56 |
| 分析: | |
| fm 和 ffm在只有两个field的时候效果理论上是一致的,这里的结果来看也基本一致。比较令人惊讶的是ftrl竟然是效果最好的,比二阶的算法效果都好,可能是因为ftrl针对每个特征都会单独学习一个学习率。 |
总结:
ctr算法可以分类两大类,一类走的是传统机器学习算法的路线,另一类是走的神经网络的路径(因为不够深,暂且不叫他深度学习,哈哈)。
传统算法是主流也非常有效:lr/gbdt/fm/ffm/
神经网络也在发展中:wide&deep/deepfm

 浙公网安备 33010602011771号
浙公网安备 33010602011771号