【Python开发】浅谈Python的垃圾回收机制
一、引入
基本在高级语言中都存在一种处理内存的垃圾回收机制。很多网上文章给的解释都很官方,让人很难理解其原理。这里我在自我的理解范围去简单谈一下Python的垃圾回收机制。“垃圾”,顾名思义就是没用的东西。这里的垃圾是指用不到的内存空间。比如定义如下变量:
a = 6 # 开辟一个内存空间,值为6。内存空间绑定了一个变量a
如果当变量a不再绑定这个内存地址的时候,但是这个内存空间还是存在的。长此以往会占用很大的内存,造成内存溢出。如果开发人员在开发的过程中忙于处理这些没用的内存也会损耗很多的精力而且特别繁杂。因此,Python的开发者就在Python解释器中加入了内存回收机制(简称:GC)。
垃圾回收机制有三种形式:
1.引用计数
2.标记-清除
3.分代回收
二、引用计数
1. 介绍
引用分为两种:直接引用和间接引用
# 直接引用
a = 6
# 间接引用
a = 6
x = [6,a]
引用计数很好理解,就是变量值被变量名关联的次数。举个简单的例子:
# 定义变量
a = 6
b = a
c = a
# 输出一下空间地址
print(id(a))
print(id(b))
print(id(c))
#输出
4382698384
4382698384
4382698384
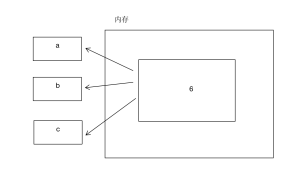
通过这个例子可以看到,他们三者关联的是同一个内存地址。也就是同一个内存地址被引用了3次,假如当这个引用次数变为0的时候,开辟的内存空间就会被收回。这也就是引用计数的原理。画个图:
2. 缺点
从引用计数可以发现,直接引用然后根据引用次数去销毁内存空间是没问题的,如果是间接引用的话情况就有所变化。举个例子:
l1=['xxx',]
l2=['yyy',]
l1.append(l2)
l2.append(l1)
print(l1)
print(l2)
del l1
del l2
先上图:
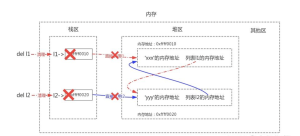
从图中可以看到,当我们执行完del的时候,l1,l2直接引用已经没有任何关联地址了。按照正常的理论应该销毁绑定的内存空间。但是实际上两个列表还是相互关联。所以引用次数并不为0,不满足引用计数的条件。造成了循环应用。由此,为了解决这个弊端就出现了标记-清除。
三、标记-清除
1. 介绍
像list,set,dict,class等都可以间接引用,所以可能产生循环引用问题。而“标记-清除”就是为了解决循环引用的问题。整个过程分两个阶段。一是标记,二是清除。
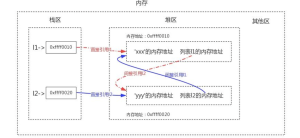
这里简单提一点,内存中有栈区和堆区。变量名和内存地址是存在栈区的,变量值是存在堆区的。我们将引用计数所解决不了的问题放到这一步骤来看。上边我们知道,当l1与l2删除引用的话,两个列表依然还在关联。这样在启用标记清除算法时,发现栈区内不再有l1与l2,于是列表1与列表2都没有被标记为存活,二者会被清理掉,这样就解决了循环引用带来的内存泄漏问题。
2. 缺点
通过介绍可以发现,它存在一个缺陷,在标记清除算法时,要遍历整个堆中的所有对象。导致的结果就是存在标记的不需要清除的对象也会反复进行遍历,非常消耗时间。
四、分代回收
1. 介绍
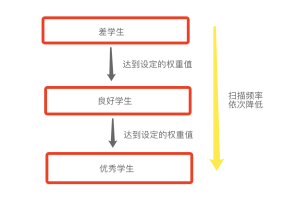
分代回收的思想是:在历经多次遍历的情况下,都没有被回收的变量,回收机制就会认为,该变量是常用变量,遍历的频率会降低。
举个简单的例子:
在一个班级内,为了督促同学们写作业。交作业的良好状态我们分为差、良好、优秀。交一次作业就给这位同学发一朵小红花。开始都将这些学生定义为差等级。当某位同学的小红花数量到达一定的权重就将它分类到良好等级。再到达一定的权重我们将他划分到优秀等级。就这样,随着分类。我们所做的工作量就是优秀等级的学生两周看一次作业,良好学生一周看一次作业,差生2天看一次作业。这样就大大减轻了工作量。分代就是基于这种理念计算的。回收还是按照引用计数作为依据。
2. 缺点
本文来自博客园,作者:Master先生,转载请注明原文链接:https://www.cnblogs.com/mastersir/p/16260383.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号