自学Oracle数据库
1.Oracle概述
1.1常见数据库
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库。数据库通常分为层次式数据库、网络式数据库和关系式数据库三种;不同的数据库是按不同的数据结构来联系和组织的。将反映和实现数据联系的方法称为数据模型。层次结构模型实质上是一种有根结点的定向有序树,按照层次模型建立的数据库系统称为层次模型数据库系统;按照网状数据结构建立的数据库系统称为网状数据库系统;关系式数据结构把一些复杂的数据结构归结为简单的二元关系(即二维表格形式),由关系数据结构组成的数据库系统被称为关系数据库系统。
数据库管理系统(Database Management System)是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库,简称DBMS。它对数据库进行统一的管理和控制,以保证数据库的安全性和完整性。用户通过DBMS访问数据库中的数据。数据库管理系统是数据库系统的核心,是管理数据库的软件。
常见的关系型数据库有:DB2,Sybase,Oracle,MySQL,Access,MS SQL Server...
Oracle简介
Oracle甲骨文公司是第一个跨整个产品线(数据库、业务应用软件和应用软件开发与决策支持工具)开发和部署100%基于互联网的企业软件的公司。Oracle是世界领先的信息管理软件供应商和世界第二大独立软件公司。其主要的有:
数据库服务器:oracle(9i,10g/11g,12c),MySQL
应用服务器:WegLogic,GlassFish
开发语言:Java
开发集成环境:NetBean
oracle 数据库是当前最主流的数据库之一。
2.Oracle安装与组成
安装oracle 11g数据库
详见《oracle 10g 11g-R2 32位安装.docx》
Oracle 11g数据库的组成
一般Oracle数据库管理系统由:实例和数据库两部分组成。
1、数据库是一系列物理文件的集合(数据文件,控制文件,联机日志,参数文件等);Oracle数据库由操作系统文件组成,这些文件也称为数据库文件,为数据库信息提供实际物理存储区。Oracle数据库包括逻辑结构和物理结构。数据库的物理结构包含数据库中的一组操作系统文件。数据库的逻辑结构是指数据库创建之后形成的逻辑概念之间的关系,如表、视图、索引等对象。
2、实例则是一组Oracle后台进程/线程以及在服务器分配的共享内存区。Oracle可以创建多个oracle数据库,一个oracle数据库将又由实例和数据库构成。如默认安装时创建的orcl数据库外还可再创建其它数据库。
Oracle 11g数据库服务
Oracle * VSS Writer Service -- Oracle卷映射拷贝写入服务,VSS(Volume Shadow Copy Service)能够让存储基础设备(比如磁盘,阵列等)创建高保真的时间点映像,即映射拷贝(shadow copy)。它可以在多卷或者单个卷上创建映射拷贝,同时不会影响到系统的系统能。(非必须启动)
OracleDBConsole* -- Oracle数据库控制台服务;在运行Enterprise Manager(企业管理器EM)的时候,需要启动这个服务;此服务被默认设置为自动开机启动的(非必须启动)
OracleJobScheduler* -- Oracle作业调度服务。此服务被默认设置为禁用状态(非必须启动)
OracleMTSRecoveryService -- 服务端控制。该服务允许数据库充当一个微软事务服务器MTS、COM/COM+对象和分布式环境下的事务的资源管理器。恢复、闪回需要开启该服务(非必须启动)
OracleOraDb11g_home1ClrAgent -- Oracle数据库.NET扩展服务的一部分。 (非必须启动)
OracleOraDb11g_home1TNSListener -- 监听器服务,服务只有在数据库需要远程访问或使用SQL Developer等工具的时候才需要,此服务被默认的设置为开机启动(非必须启动)
OracleService* -- 数据库服务,是Oracle核心服务该服务,是数据库启动的基础, 只有该服务启动,Oracle数据库才能正常操作。此服务被默认的设置为开机启动。(必须启动)
SQL Plus 连接
打开SQL Plus:
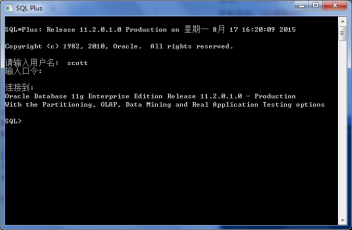
在上述界面中可以输入用户名,如在安装时解锁了的用户scott,口令为:tiger
输入语句查询该用户下的对象:
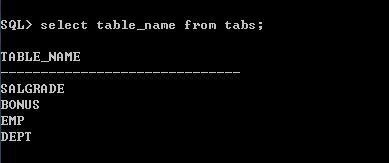
另外;也可以直接在命令行中输入sqlplus scott/tiger 进入并登录
SQLDeveloper 连接
打开SQL Developer;在出现界面的左边右击鼠标,新建连接:
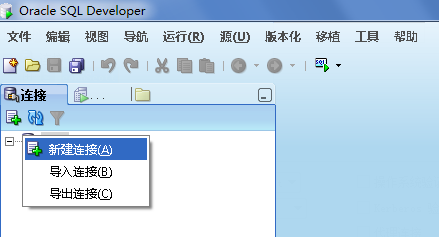
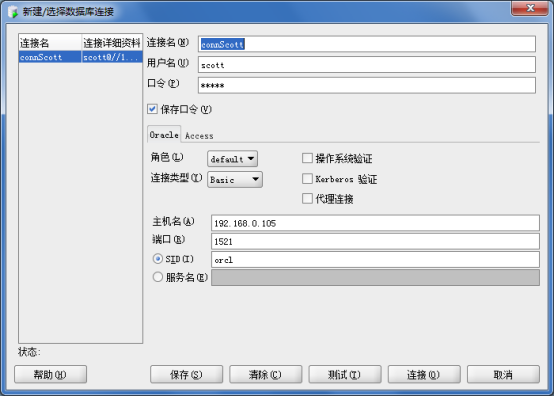
注意在上图中;
主机名:如果是本机的按照配置在网络管理中的服务的配置设置,可以为localhost;如果是连接其它机器的数据库则指定其ip;
SID:是指定数据库服务器上的全局数据库名称,默认安装的话一般是orcl

PLSQLDeveloper 连接
安装PLSQL Develper;

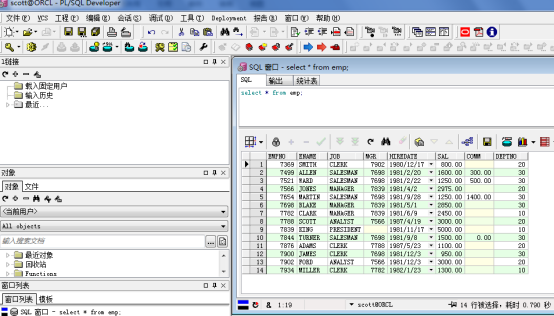
3 SQL语言
3.1、SCOTT用户数据表(重点,背)
在数据库的学习过程之中,最为重要的部分就是SCOTT用户下的四张数据表,对于这四张数据表,要求今天一定要记下这四张表的表结构以及每个字段的作用和类型。
在SCOTT用户中的四张表:部门表(dept)、雇员表(emp)、工资等级表(salgrade)、工资表(bonus)。
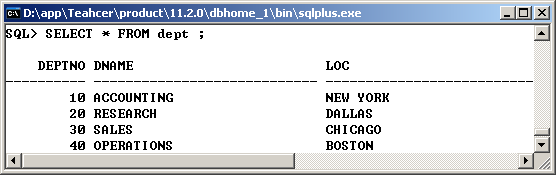
1、 部门表:dept
|
No. |
字段名称 |
类型 |
描述 |
|
1 |
DEPTNO |
NUMBER(2) |
部门编号,最多由两位数字所组成 |
|
2 |
DNAME |
VARCHAR2(14) |
部门名称,由14位的字符长度组成(四个中文) |
|
3 |
LOC |
VARCHAR2(13) |
部门位置 |
Oracle数据库之中的字符串都使用VARCHAR2类型表示。
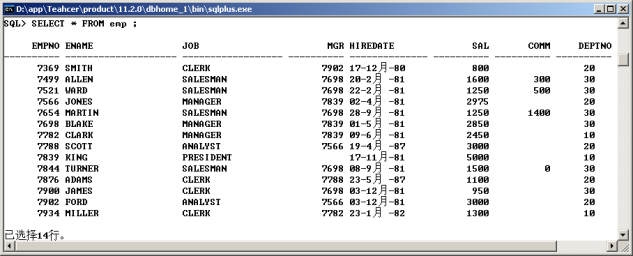
2、 雇员表:emp
|
No. |
字段名称 |
类型 |
描述 |
|
1 |
EMPNO |
NUMBER(4) |
雇员编号,最多右4位数字所组成 |
|
2 |
ENAME |
VARCHAR2(10) |
雇员姓名 |
|
3 |
JOB |
VARCHAR2(9) |
职位 |
|
4 |
MGR |
NUMBER(4) |
领导编号 |
|
5 |
HIREDATE |
DATE |
雇佣日期,此数据类型包含有日期时间 |
|
6 |
SAL |
NUMBER(7,2) |
基本工资,由2位小数和5位整数所组成 |
|
7 |
COMM |
NUMBER(7,2) |
佣金(销售) |
|
8 |
DEPTNO |
NUMBER(2) |
部门编号 |
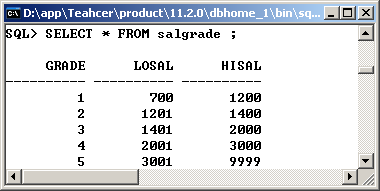
3、 工资等级表:salgrade
|
No. |
字段名称 |
类型 |
描述 |
|
1 |
GRADE |
NUMBER |
等级编号 |
|
2 |
LOSAL |
NUMBER |
此等级的最低工资 |
|
3 |
HISAL |
NUMBER |
此等级的最高工资 |
4、 工资表:bonus
|
No. |
字段名称 |
类型 |
描述 |
|
1 |
ENAME |
VARCHAR2(10) |
雇员姓名 |
|
2 |
JOB |
VARCHAR2(9) |
职位 |
|
3 |
SAL |
NUMBER |
工资等级 |
|
4 |
COMM |
NUMBER |
佣金 |
这四张表之中只有bonus表是没有数据的。
3.2、简单查询
所谓的简单查询指的是查询一张表之中全部数据行的记录。简单查询的语法如下。
语法:简单查询
|
SELECT [DISTINCT] * | 列名称 [别名] , ... è 确定数据显示列 FROM 表名称 [别名] ; |
对于简单查询而言,其每一个子句(FROM子句、SELECT子句)的执行顺序如下:
· 第一步:执行FROM语句,以确定要显示的数据来源;
· 第二步:执行SELECT子句,确定要显示的数据列。
对于SELECT子句而言,如果要显示全部的数据列,那么就使用“*”,如果要查询固定的数据列,则需要写上列的名称。
范例:查询emp表中的全部记录
|
SELECT * FROM emp ; |
范例:查询每个雇员的编号、姓名、职位、基本工资
|
SELECT empno,ename,job,sal FROM emp ; |
范例:查询所有雇员的职位
职位信息一定会存在有重复数据,所以首先发出如下的查询。
|
SELECT job FROM emp ; |
下面使用DISCTINCT消除掉所有的重复列。,
|
SELECT DISTINCT job FROM emp ; |
但是对于重复的数据消除还是有一点需要说明的是:只有在两行中所有列的数据全部相同的时候才可以消除掉重复。
范例:查询每个雇员的姓名、职位
|
SELECT DISTINCT ename,job FROM emp ; |
除了基本的查询列之外,各个列之间也可以方便的实现数学的四则运算。
范例:现在要求查询出每个雇员的编号、姓名、基本年薪(月薪:sal * 12)
|
SELECT empno,ename,sal*12 FROM emp ; |
这个时候发现直接将“sal*12”作为了列的名称,但是这样的名称明显不合适,所以可以使用别名的方式进行指定。
范例:为查询设置别名
|
SELECT empno,ename,sal*12 income FROM emp ; |
有了别名之后可以发现,查询之后列名称可以自动的进行替换。
在使用简单查询的时候,除了查询列名称之外,也可以查询单独的常量(日期、字符串、数字),但是所有的常量会随着每一行数据重复显示,对于常量的编写有如下要求(字符串和数字):
· 字符串:要求使用“'”声明,例如:'hello';
· 数字:直接编写数字,例如:1、2、3。
|
SELECT empno , 'hello' FROM emp ; |
虽然别名和常量都是字符串,但是别名声明的时候是不加单引号的,只有在常量的时候字符串才加上单引号。
同时还需要说明的是,在查询之中,SELECT子句里面也可以使用“||”进行连接。
范例:观察“||”符的使用
|
SELECT empno || ename FROM emp ; |
现在使用了“||”连接在了一起,但是整体的输出效果并不理想,所以希望以如下的格式进行数据的显示:
· 编号:7369,姓名:SMITH,职位:CLERK。
|
SELECT '编号:' || empno || ',姓名:' || ename || ',职位:' || job info FROM emp ; |
以上的这种操作的意义不大,只是作为一个知识点清楚就行了。
3.3、限定查询
简单查询会将一张数据表之中的全部数据行进行返回,如果说现在表中的数据行过多,那么肯定无法进行浏览,所以必须对显示的数据行的返回做一个限定。
限定查询指的是在简单查询的基础上增加若干个查询的限定条件,所有的限定条件使用WHERE子句表示,此时的语法如下。
|
SELECT [DISTINCT] * | 列名称 [别名] , ... FROM 表名称 [别名] WHERE 限定条件(s) ; |
此时给出的三个子句执行顺序如下:
· 第一步:执行FROM子句确定数据的来源;
· 第二步:执行WHERE子句,对要显示的数据进行条件过滤;
· 第三步:执行SELECT子句,对要显示的数据列进行控制。
在使用WHERE子句的时候可以同时设置多个条件,而这多个条件主要就是通过逻辑运算连接,逻辑运算分为三种:
· AND:表示与操作,所有的判断条件全部返回true,才表示通过过滤,有一个false就不显示;
· OR:表示或操作,若干个判断条件之中有一个返回true,那么最终的结果就是true;
· NOT:表示取反操作,即:true变为false、false变为true。
但是除了逻辑的连接条件之外,也可以使用以下的一些判断符号。关系运算符、范围运算、模糊查询。
3.3.1、关系运算符
关系运算主要使用以下的几种符号表示:>、<、>=、<=、<>(!=);
范例:要求查询出所有工资高于1500的雇员编号、姓名、职位、工资
· 工资高于1500意味着不是所有的数据行都显示,需要执行过滤,使用“sal>1500”表示;
· 现在要求查询的是部分字段,所以要通过SELECT来控制显示的数据列。
|
SELECT empno,ename,job,sal FROM emp WHERE sal>1500 ; |
范例:查询smith的完整信息
这个时候给出的smith是雇员的姓名,所以自然发出了如下的查询。
|
SELECT * FROM emp WHERE ename='smith' ; |
发现这个时候并没有任何的数据返回,因为Oracle数据库之中的数据是区分大小写的(命令不区分),所以这个时候就必须修改字符串的常量。
|
SELECT * FROM emp WHERE ename='SMITH' ; |
范例:查询所有办事员(CLERK)的详细信息
现在一定要按照job字段查。
|
SELECT * FROM emp WHERE job='CLERK' ; |
范例:查询所有办事员的详细信息,同时要求工资大于1000
现在一定是要设置两个查询条件,而且这两个查询条件应该同时满足。使用AND进行连接
|
SELECT * FROM emp WHERE job='CLERK' AND sal>1000 ; |
范例:查询出所有销售人员或工资大于等于3000的全部雇员信息
所有的销售人员通过job字段执行过滤,工资使用sal字段执行过滤。两个条件的连接使用OR完成。
|
SELECT * FROM emp WHERE job='SALESMAN' OR sal>=3000 ; |
如果在整个查询之中使用了NOT,那么就表示取反。
范例:结果取反
|
SELECT * FROM emp WHERE NOT (job='SALESMAN' OR sal>=3000) ; |
逻辑运算只有AND和OR是进行连接的,NOT是针对于结果求反。
3.3.2、范围查询:BETWEEN…AND
那么现在试想一个问题,如果说现在要求查询出工资在1500 ~ 3000(包含1500和3000)之间的全部雇员信息。最早的方式是使用两个关系运算而后进行连接。
范例:传统思路实现
|
SELECT * FROM emp WHERE sal>=1500 AND sal<=3000 ; |
但是现在查询的毕竟是一个范围,既然是范围,那么就可以采用如下语法完成:
|
字段 BETWEEN 最小值 AND 最大值 è 包含有最大值和最小值的相等验证 |
范例:利用BETWEEN…AND完成
|
SELECT * FROM emp WHERE sal BETWEEN 1500 AND 3000 ; |
那么BETWEEN..AND除了可以在数字类型的字段上使用之外,也可以在字符串(几乎没用)或者是日期上使用。
范例:在字符串上使用BETWEEN..AND(纯粹娱乐)
|
SELECT * FROM emp WHERE ename BETWEEN 'KING' AND 'WARD' ; |
范例:查询所有在1981年雇佣的雇员
现在如果要使用BETWEEN..AND,必须确定两个值:
· 开始值:1981-01-01,“01-1月-81”
· 结束值:1981-12-31,“31-12月-1981”
emp表之中的hiredate字段保存的是雇佣日期,但是发现这个雇佣日期的格式“08-9月 -81”,日-月-年表示,如果日的位数不足2位,那么就自动加上前导0,如果月不足2位不做任何的修饰。
|
SELECT * FROM emp WHERE hiredate BETWEEN '01-1月-81' AND '31-12月-1981' ; |
这个时候就可以按照时间的范围进行查询,再加上日后的一些统计功能。
3.3.3、NULL判断
NULL在数据库原理之中表示的是一个不确定的内容。但是对于NULL的判断不能够直接使用关系进行操作。
范例:错误的判断 —— 查询所有不领取佣金的雇员
|
SELECT * FROM emp WHERE comm=null ; |
对于NULL的判断要使用特定的两个符号完成:IS NULL(为空返回true)、IS NOT NULL(非空返回true)。
范例:查询所有领取佣金的雇员 —— comm不为null
|
SELECT * FROM emp WHERE comm IS NOT NULL ; |
|
SELECT * FROM emp WHERE NOT comm IS NULL ; |
范例:查询所有不领取佣金的雇员
|
SELECT * FROM emp WHERE comm IS NULL ; |
NULL只能采用如上的方式完成。
3.3.4、范围查询:IN、NOT IN
那么首先来考虑以下一种查询:查询雇员编号是7369、7566、7788、9999(不存在的)的雇员,这个时候如果按照之前的做法,查询编写如下。
|
SELECT * FROM emp WHERE empno=7369 OR empno=7566 OR empno=7839 OR empno=9999 ; |
但是这个时候所给出的实际上就是查询的范围,如果是范围的查询,就可以换为IN完成。
范例:使用IN查询
|
SELECT * FROM emp WHERE empno IN (7369,7566,7839,9999) ; |
这个时候就可以查询出指定范围的查询,而且更加的简短。
范例:使用NOT IN查询
|
SELECT * FROM emp WHERE empno NOT IN (7369,7566,7839,9999) ; |
|
SELECT * FROM emp WHERE NOT empno IN (7369,7566,7839,9999) ; |
注意:关于IN和NOT IN在NULL的处理问题
如果在使用IN或NOT IN判断范围之中出现了NULL,那么下面请观察可能造成的问题。
范例:使用IN之中出现NULL —— 没有任何影响
|
SELECT * FROM emp WHERE empno IN (7369,7566,7839,null) ; |
范例:使用NOT IN之中出现NULL —— 没有任何的数据返回
|
SELECT * FROM emp WHERE empno NOT IN (7369,7566,7839,NULL) ; |
在使用NOT IN判断的过程之中,如果范围里面存在有NULL,那么就表示不会有任何的数据返回。
3.3.5、模糊查询:LIKE
模糊查询就是指的是关键字查询,在SQL中使用LIKE语句完成,但是在使用LIKE语句的时候需要注意两个标记符:
· “_”:表示匹配任意的一位字符;
· “%”:表示匹配任意多个字符,可能是0位、1位、多位。
范例:要求查询出姓名以字母A开头的雇员信息
|
SELECT * FROM emp WHERE ename LIKE 'A%' ; |
范例:查询雇员姓名之中第二个字母包含有A的雇员信息。表示第一位任意,第二位是A,之后随便了。
|
SELECT * FROM emp WHERE ename LIKE '_A%' ; |
范例:查询雇员姓名之中任意位置包含有字母A的雇员信息
|
SELECT * FROM emp WHERE ename LIKE '%A%' ; |
LIKE虽然可以实现模糊查询,但是它只能够在少量数据的情况下完成查询。
注意:关于LIKE的说明
对于LIKE在开发之中一定是会存在使用要求的,对于LIKE有如下的两点说明。
说明一:LIKE不仅仅可以在字符串上使用,也可以在任意的数据类型上使用,例如:数字、日期
|
SELECT * FROM emp WHERE ename LIKE '%A%' OR sal LIKE '%1%' OR hiredate LIKE '%9%' ; |
对于这一特征应该并不陌生,在之前使用的BETWEEN…AND也可以在各个类型上使用。
说明二:在使用LIKE的时候如果没有设置任何的关键字,则表示查询全部数据
|
SELECT * FROM emp WHERE ename LIKE '%%'; |
在以后的开发之中,以上的特征一定会使用。
讨论:在SELECT子句之中设置的别名WHERE是否可以使?
不可能使用,因为SELECT是在WHERE之后执行的。
3.4、数据排序(重点)
如果现在要想针对于显示的数据按照指定的字段进行排序,则要使用ORDER BY子句。语法如下。
|
SELECT [DISTINCT] * | 列名称 [别名] , ... è 3、设置要显示的数据列 FROM 表名称 [别名] è 1、确定数据来源 WHERE 限定条件(s) è 2、针对于数据行进行筛选 [ORDER BY 排序字段 [ASC |DESC] ,排序字段 [ASC |DESC] , .. ]; è 4、数据列排序 |
ORDER BY这个子句永远写在SQL的最后一行,永远是最后一个执行,那么ORDER BY是唯一可以使用SELECT别名的子句。在进行排序的时候有两种排序模式:
· ASC:默认的排序方式,不写也是ASC,表示的是升序;
· DESC:人为设置的排序方式,表示降序。
范例:查询所有雇员的信息,要求按照工资由高到低排序
|
SELECT * FROM emp ORDER BY sal DESC ; |
范例:查询所有雇员的信息,要求按照工资由高到低排序,如果工资相同,按照雇佣日期由早到晚排序
|
SELECT * FROM emp ORDER BY sal DESC ,hiredate ASC ; |
范例:查询所有10部门雇员的信息,要求按照工资由高到低排序,如果工资相同,按照雇佣日期由早到晚排序
|
SELECT * FROM emp WHERE deptno=10 ORDER BY sal DESC ,hiredate ASC ; |
对于此时给出的SQL的执行顺序:FROM è WHERE è SELECT è ORDER BY。
3.6、单行函数(重点,背)
单行函数是完成某些特定功能的工具,这个部分还是要求进行一些巩固的记忆。单行函数的基本语法如下:
|
返回值类型 单行函数名称(参数 | 列 , …) |
而根据使用的环境不同单行函数分为如下几种:字符串函数、数值函数、日期函数、转换函数、通用函数。
3.6.1、字符串函数
字符串函数的主要功能是进行字符串数据的处理的,常用的字符串函数有如下几个:UPPER()、LOWER()、INITCAP()、SUBSTR()、TRIM()、LENGTH()、REPLACE()。
1、 大小写转换函数
· 字符串转大写:字符串 UPPER(列 | 字符串);
· 字符串转小写:字符串 LOWER(列 | 字符串)。
范例:观察使用
|
SELECT UPPER('Hello') FROM emp ; |
为了验证函数要求必须是完整的SQL语句,但是以上语句执行之后发现返回的数据有14行记录,而且造成这种问题主要是因为emp表有14行记录。那么为了验证函数方便,特意使用一张系统的临时表:dual。
|
SELECT UPPER('Hello') FROM dual ; |
|
SELECT LOWER('Hello') FROM dual ; |
在一些系统之中如果存在有不区分大小写的操作,那么几乎都是会统一的将数据变为大写或小写。那么为了演示此类功能,做一个简单的应用(没有研究的价值),由用户输入一个雇员姓名,而后查询此雇员的完整信息。
范例:完成代码
|
SELECT * FROM emp WHERE ename='&inputname' ; |
用户输入数据的时候很少会去考虑大小写问题,所以必须由系统自动处理,使用一个UPPER函数。
|
SELECT * FROM emp WHERE ename=UPPER('&inputname') ; |
2、 首字母大写
· 语法:字符串 INITCAP(列 | 字符串);
范例:显示每个雇员的编号、姓名、职位,其中对于姓名要求首字母大写
|
SELECT empno,ename,INITCAP(ename),job FROM emp ; |
3、 计算字符串长度
· 语法:数字 LENGTH(列 | 字符串)
范例:查询出雇员姓名长度为5的全部雇员信息
|
SELECT * FROM emp WHERE LENGTH(ename)=5 ; |
4、 去掉左右空格
· 语法:字符串 TRIM(列 | 字符串)
范例:验证函数
|
SELECT TRIM(' hello World '), LENGTH(TRIM(' hello World ')) FROM dual ; |
使用trim()函数的时候只能够去掉左右两边的空格,而中间的空格是无法取消的。
3.6.3、日期函数
如果要想进行日期的操作,那么首先一定要取得的是当前的日期时间,在Oracle中为了方便用户取得当前日期时间,提供有一个SYSDATE伪列。所谓的伪列指的是不是真实存在于表上的列,但是又可以直接使用的列。
范例:验证SYSDATE
|
SELECT SYSDATE , SYSTIMESTAMP FROM dual; |
但是取得了当前的日期时间之后,那么后面可以使用以下的三个计算公式进行日期时间操作:
· 日期 + 数字 = 日期,表示若干天之后的日期;
· 日期 – 数字 = 日期,表示若干天之前的日期;
· 日期 – 日期 = 数字,表示两个日期之间所经历的天数。
范例:观察公式使用
|
SELECT SYSDATE-10 , SYSDATE + 120 , SYSDATE + 2000 FROM dual ; |
范例:计算天数 —— 计算每一位雇员到今天为止雇佣的天数
|
SELECT ename,hiredate,SYSDATE-hiredate FROM emp ; |
3.6.4、转换函数
现在为止已经接触到了Oracle中的字符串、数字、日期,那么这三种数据类型也可以实现互相的转换操作,使用的函数:TO_CHAR()、TO_DATE()、TO_NUMBER()。
1、 日期或数字转字符串
· 语法:字符串 TO_CHAR(列 | 日期 | 数字,转换格式)
在之前使用SYSDATE求出的日期时间按照“24-3月 -14”这样的格式排列,但是这种做法有点反中国人。所以这个时候就可以使用TO_CHAR()进行格式化显示,但是如果要想格式化,还需要几个转换标记的支持:年(yyyy)、月(mm)、日(dd)、时(hh、hh24)、分(mi)、秒(ss)。
范例:格式化日期时间显示
|
SELECT TO_CHAR(SYSDATE,'yyyy-mm-dd') , TO_CHAR(SYSDATE,'yyyy-mm-dd hh24:mi:ss') , TO_CHAR(SYSDATE,'fmyyyy-mm-dd hh24:mi:ss') FROM dual ; |
2、 字符串转日期
· 语法:日期 TO_DATE(列 | 字符串,转换格式)
范例:将字符串格式化为日期
|
SELECT TO_DATE('1989-09-19','yyyy-mm-dd') FROM dual ; |
这类的操作如果是直接操作数据库的话还有那么一点点的用处,如果是通过程序操作,那么肯定使不上。
3、 字符串转数字
· 语法:数字 TO_NUMBER(列 | 字符串)
范例:测试程序
|
SELECT TO_NUMBER('1') + TO_NUMBER('2') FROM dual ; |
|
SELECT '1' + '2' FROM dual ; |
对于Oracle数据库而言,各个数据类型之间是存在一种自动的转换原则,如果现在字符串是由数字组成,执行数学计算时,自动变为数字,如果字符串的格式符合日期格式,也会在运算时自动变为日期。
3.6.5、通用函数
以上的部分函数大部分的数据库都是支持的,但是Oracle有一些自己的特色,有两个代表函数:NVL()、DECODE()。
1、 处理NULL数据
· 语法:数字 NVL(列,默认值);
在讲解此函数之前首先完成一个功能。
范例:现在要求显示出每个雇员的编号、姓名、职位、基本工资、佣金、年薪
|
SELECT empno,ename,job,sal,comm,(sal+comm)*12 income FROM emp ; |
现在发现只要是没有佣金的雇员在计算年薪的时候都会出现问题,结果都是null。之所以出现这样的情况,主要是因为NULL与任何数值执行数学计算最终结果永远都是NULL。
那么为了在数据为null的时候程序依然可以得到正确的结果,就可以通过NVL()函数处理。
范例:使用NVL()函数
|
SELECT empno,ename,job,sal,comm,(sal+NVL(comm,0))*12 income FROM emp ; |
3.7分组统计查询(重点,难点)
3.7.1、统计函数(分组函数)
在之前使用过一个COUNT()函数,此函数的功能是统计每张数据表之中的数据量,而这个函数就是统计函数的一种,在SQL中常用的统计函数一共有五个:COUNT()、AVG()、SUM()、MIN()、MAX();
范例:统计公司的总人数、平均工资、每月支付的总工资
|
SELECT COUNT(empno) , AVG(sal) , AVG(sal+NVL(comm,0)) , SUM(sal) FROM emp ; |
范例:求出公司的最高工资和最低工资
|
SELECT MAX(sal) , MIN(sal) FROM emp ; |
在Oracle之中所有的函数几乎都是可以不分数据类型的。
面试题:请解释COUNT(*)、COUNT(字段)、COUNT(DISTINCT 字段)的区别?
|
SELECT COUNT(*) , COUNT(empno) , COUNT(comm) , COUNT(DISTINCT job) FROM emp ; |
· COUNT(*):可以准确的统计出表中的数据量;
· COUNT(字段):如果此字段上没有null,那么最终的效果与“COUNT(*)”相同,如果存在有null,则null不统计;
· COUNT(DISTINCT 字段):重复的数据不统计。
3.9两个重要的数据伪列(重点)
在之前使用过SYSDATE,这个列虽然没有在表中定义,但是却可以使用,所以这就是一个伪列,可是在Oracle之中还有两个非常重要的伪列:RONUM、ROWID。
3.9.1、行号:ROWNUM(核心)
ROWNUM是一个在查询之中可以根据数据行自动生成的一个行标记伪列。
范例:观察ROWNUM使用
|
SELECT ROWNUM , empno,ename,job,deptno,sal FROM emp ; |
ROWNUM这个列原本就不在emp表之中,但是由于其是伪列,所以可以直接查询。执行之后发现随着数据行的增加,ROWNUM可以自动的进行行号累加,但是必须强调的是ROWNUM并不是固定的。是在每次查询的时候动态生成的,而在Oracle之中使用ROWNUM可以实现两个功能:
· 功能一:取得第一行记录;
· 功能二:取得前N行记录。
范例:取得第一行数据
|
SELECT ROWNUM , empno,ename,job,deptno,sal FROM emp WHERE ROWNUM=1 AND deptno=10 ; |
范例:取得前N行记录
|
SELECT ROWNUM , empno,ename,job,deptno,sal FROM emp WHERE ROWNUM<=10 ; |
但是需要记住的是,ROWNUM本身并没有提供取得指定范围行的功能。因为ROWNUM属于动态生成
范例:错误的应用
|
SELECT ROWNUM , empno,ename,job,deptno,sal FROM emp WHERE ROWNUM BETWEEN 6 AND 10 ; |
如果要想正确的取得指定范围行的记录,则必须使用子查询,例如:以上一例的要求,取得6 ~ 10行记录,那么首先要取得前10行记录,而后再通过前10行取得里面的后五行记录。
所以现在可以有如下的一个变量代入:
· 当前页:currentPage = 2;
· 每页显示的数据行数:lineSize = 5;
|
SELECT * FROM ( SELECT ROWNUM rn, empno,ename,job,deptno,sal FROM emp WHERE ROWNUM<=10) temp è 10 = currentPage * lineSize ; WHERE temp.rn>5 ; è 5 = (currentPage - 1) * lineSize; |
范例:取前5条(1 ~ 5)
这个时候有两种写法,一种就是直接取前5条(语法上没错,但是不通用)
· currentPage = 1、lineSize = 5;
|
SELECT ROWNUM rn, empno,ename,job,deptno,sal FROM emp WHERE ROWNUM<=5 ; |
|
SELECT * FROM ( SELECT ROWNUM rn, empno,ename,job,deptno,sal FROM emp WHERE ROWNUM<=5) temp WHERE temp.rn>0 ; |
那么现在就可以给出日后分页查询的基本语法格式。
|
SELECT * FROM ( SELECT ROWNUM rn, 列,列,列,... FROM 表名称 WHERE ROWNUM<=(currentPage * lineSize)) temp WHERE temp.rn>((currentPage - 1) * lineSize) ; |
在使用Oracle进行项目开发过程之中,此类程序语句一定会出现,所以必须会。
3.9.2、行ID:ROWID(了解)
在数据库之中,虽然每一行都有自己的字段数据,可是除了这些之外还有每一行数据保存在磁盘上的物理地址。对于每行数据的物理地址,就可以通过ROWID取得了,观察如下的一种查询。
范例:观察ROWID
|
SELECT ROWID,deptno,dname,loc FROM dept ; |
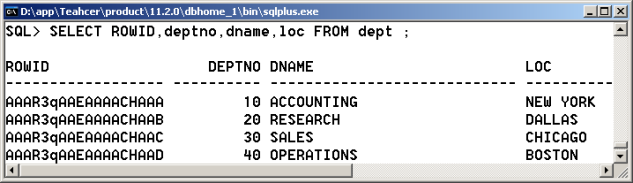
发现这个时候每行数据的ROWID不同,那么以“AAAR3qAAEAAAACHAAA”ROWID组成进行说明,每一个ROWID里面包含如下的几个组成部分:
· 数据对象号:AAAR3q;
· 相对文件号:AAE;
· 数据块号:AAAACH;
· 数据行号:AAA。
下面通过两个代码(其中有一个面试题)来说明ROWID简单作用。
为了演示方便首先将dept表复制为mydept表(复制后的表没有约束问题,即:数据可以重复)。
范例:将dept复制为mydept
|
CREATE TABLE mydept AS SELECT * FROM dept ; |
范例:先观察此时的mydept里面的每一个ROWID。
|
SELECT ROWID,deptno,dname,loc FROM mydept ; |
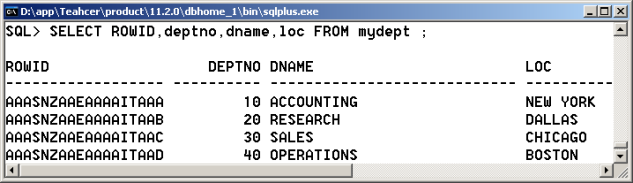
那么此时由于数据表的设计不严谨,所以mydept表里面出现了这样的一条记录。
|
INSERT INTO mydept(deptno,dname,loc) VALUES (10,'ACCOUNTING','NEW YORK') ; |
那么此时在mydept表中存在有两个10部门信息,但是要求现在删除一个重复的,保留最早增加的。如果此时直接使用DELETE语句,按照部门编号删除会导致两行数据被删除,所以只能够利用ROWID进行处理。
范例:此时重复数据的ROWID为“AAASNZAAEAAAAIWAAA”,所以执行删除
|
DELETE FROM mydept WHERE ROWID='AAASNZAAEAAAAIWAAA' ; |
此种方式是作为行唯一的物理地址标识使用的,但是从实际的工作来讲,只要不是太傻的人,都不会出现这样的问题。因为在实际的工作环境数据表是需要存在有约束,一旦有约束就可以避免此类问题。
面试题:现在的mydept表由于最早设计的问题,导致里面存在了大量的重复数据。
|
INSERT INTO mydept(deptno,dname,loc) VALUES (10,'ACCOUNTING','NEW YORK') ; INSERT INTO mydept(deptno,dname,loc) VALUES (10,'ACCOUNTING','NEW YORK') ;
INSERT INTO mydept(deptno,dname,loc) VALUES (20,'RESEARCH','DALLAS') ; INSERT INTO mydept(deptno,dname,loc) VALUES (20,'RESEARCH','DALLAS') ; INSERT INTO mydept(deptno,dname,loc) VALUES (20,'RESEARCH','DALLAS') ;
INSERT INTO mydept(deptno,dname,loc) VALUES (30,'SALES','CHICAGO') ; INSERT INTO mydept(deptno,dname,loc) VALUES (30,'SALES','CHICAGO') ; |
要求,通过一条语句删除掉所有重复数据,保留最早增加的数据,删除之后的数据如下。

为了更好的分析,首先更改一下思路,现在要求查询出mydept表中重复的数据,这个直接使用分组,而后增加一个HAVING子句,统计个数,大于1就表示重复。
|
SELECT deptno,dname,loc,MIN(ROWID) FROM mydept GROUP BY deptno,dname,loc HAVING COUNT(deptno)>1 ; |
这个时候发现重复数据只需要依据分组,就可以找到最早的ROWID。
范例:编写语句
· 第一步,继续使用分组,统计出所有最早的ROWID(要保留的)
|
SELECT MIN(ROWID) FROM mydept GROUP BY deptno,dname,loc ; |
· 第二步:保留以上的ROWID
|
DELETE FROM mydept WHERE ROWID NOT IN ( SELECT MIN(ROWID) FROM mydept GROUP BY deptno,dname,loc) ; |
这样的题目你如果赶到了,那么对你就有用了,但是这个只是ROWID的一些算是实际的用法。虽然有ROWID的支持,但是在程序开发之中不要使用ROWID做任何的代码支持。
Oralce进阶
1、序列的定义及使用;
2、 视图的定义及使用;
3、 同义词的定义及使用;
4、 索引的基本原理;
5、 用户管理与权限分配;
6、 数据库的备份问题;
3、具体内容
今天所讲解的主要内容是围绕着DDL与DCL两个概念。
3.1、序列(核心)
在许多的数据库之中都会存在有自动增长列的概念。但是在Oracle(Oracle 12C之前)之中并没有为用户提供这种直接的自动增长列,都是提供半自动化的手工增长序列。在Oracle中序列依然属于数据库对象,所以序列的创建语法如下:
|
CREATE SEQUENCE 序列名称 [INCREMENT BY 步长] [START WITH 开始值] [MAXVALUE 最大值 | NOMAXVALUE] [MINVALUE 最小值 | NOMINVALUE] [CYCLE | NOCYCLE] [CACHE 缓存个数 | NOCACHE] ; |
如果直接使用了“CREATE SEQUENCE 序列名称”创建序列的话,那么默认的步长是1,开始值也是1,没有最大值,最小值1,采用非循环序列(NOCYCEL)、默认的缓存个数是20个。
范例:创建序列
|
CREATE SEQUENCE myseq ; |
序列本身依然属于数据库的对象,所以序列的信息可以通过“user_sequences”查看序列的详细信息。
范例:查看序列的数据字典
|
SELECT * FROM user_sequences ; |
这个时候数据字典返回的数据信息如下:
· 序列名称(SEQUENCE_NAME):MYSEQ;
· 最小值(MIN_VALUE):1;
· 最大值(MAX_VALUE):1.0000E+28;
· 步长(INCREMENT_BY):1;
· 循环(CY):N(不是循环序列);
· 缓存个数(CACHE_SIZE):20;
· 最后一次增长数值(LAST_NUMBER):1。
这个时候序列已经定义完成了,但是如何去使用这个序列呢?在Oracle中提供了两个操作的伪列来使用序列
· 取得当前的序列内容:序列对象名称.currval;
· 取得序列的下一个增长内容:序列对象名称.nextval。
但是如果要想操作currval伪列之前必须首先使用nextval伪列进行操作,否则会出现错误。
|
SELECT myseq.currval FROM dual ; |
|
SELECT myseq.currval FROM dual * 第 1 行出现错误: ORA-08002: 序列 MYSEQ.CURRVAL 尚未在此会话中定义 |
范例:正常调用
|
SELECT myseq.nextval FROM dual ; SELECT myseq.currval FROM dual ; SELECT * FROM user_sequences ; |
发现每当调用nextvalu伪列最后的值与LAST_NUMBER的值相同的时候,LAST_NUMBER就会再继续增长指定CACHE个数的序列。所谓的缓存指的是在数据库之中自动为用户已经生成好了指定个数的序列值,这个时候在用户使用序列时不再需要现场计算,而是直接取用,但是由于这些内容保存在缓存之中,如果此时数据库的实例关闭了,那么就可能会出现跳号的问题。
如果要想实现数据表的自动增长列,那么肯定是不能够在表创建的时候设置,需要在进行数据增加的时候采用手工的方式控制序列内容。
范例:数据库创建脚本
|
-- 删除数据表 DROP TABLE member PURGE ; -- 创建表 CREATE TABLE member( mid NUMBER , name VARCHAR2(20) , CONSTRAINT pk_mid PRIMARY KEY(mid) ) ; |
这个时候所创建的数据表的形式与之前没有任何的区别,关键在于数据的增加上。
范例:增加数据
|
INSERT INTO member(mid,name) VALUES (myseq.nextval,'MLDN') ; |
如果序列不需要使用了,使用DROP删除。
范例:删除序列
|
DROP SEQUENCE myseq ; |
不过以上都是创建的基本序列,实际上在进行序列创建的时候也可以进行一些其它配置。
范例:创建一个步长为2的序列
|
DROP SEQUENCE myseq ; CREATE SEQUENCE myseq INCREMENT BY 2 ; |
范例:创建序列,让其从100开始
|
DROP SEQUENCE myseq ; CREATE SEQUENCE myseq INCREMENT BY 2 START WITH 100 ; |
范例:设置一个循环序列(1、3、5、7、9)
如果要想设置一个循环序列,那么需要满足于以下的要求:
· 打开循环的标记:CYCLE;
· 步长:INCREMENT BY 2;
· 最大值:9;
· 最小值:1。
|
DROP SEQUENCE myseq ; CREATE SEQUENCE myseq INCREMENT BY 2 START WITH 1 MINVALUE 1 MAXVALUE 9 CYCLE CACHE 3 ; |
因为缓存的个数一定要小于最高的长度。
3.2、视图(次重点)
在进行数据库操作之中,查询是最头疼的,而且对于各种的复杂查询实际上是会感觉到很崩溃的。但是在开发之中为了分工明确,往往在进行数据库设计的过程之中,那么设计人员会根据业务的需求提前准备好若干个SQL语句,而这些SQL语句为了方便管理,往往都会将其保存在视图之中,所以所谓的视图指的就是封装了一条查询语句的对象。
视图的创建语法如下:
|
CREATE [OR REPLACE] VIEW 视图名称 AS 子查询 ; |
在创建视图的时候可以使用的语法形式:
· CREATE VIEW:表示的是创建新视图,但是如果创建的视图名称已经存在会出现错误;
· CREATE OR REPLACE VIEW:表示创建新视图或者是替换视图,如果视图不存在,那么就会创建一个新的,如果视图已经存在了,则使用新的语句替换掉旧的。
范例:创建一个视图
|
CREATE OR REPLACE VIEW myview AS SELECT d.deptno,d.dname,d.loc,temp.count,temp.avg FROM dept d , ( SELECT deptno dno,COUNT(empno) count,AVG(sal) avg FROM emp GROUP BY deptno) temp WHERE d.deptno=temp.dno(+) ; |
特别提醒:关于Oracle 11g之后的问题
在Oracle 11g之前,scott用户本身都具备有了创建视图的权限,但是从Oracle 11g之后就不再具备了,可以先执行如下的命令授权(随后讲解)。
|
CONN sys/change_on_install AS SYSDBA ; GRANT CREATE VIEW TO scott ; CONN scott/tiger ; |
当视图创建完成之后就可以直接查询视图对象(myview)。
|
SELECT * FROM myview ; |
此时程序人员只需要通过一条很简单的查询语句就可以实现复杂的查询功能。
视图实际上本身也可以直接进行更新操作,但是这种更新也只是针对于简单视图。
范例:创建一个包含有全部雇员编号、姓名、职位、工资、部门名称、位置的视图
|
CREATE OR REPLACE VIEW myview AS SELECT e.empno,e.ename,e.job,e.sal,d.dname,d.loc FROM emp e,dept d WHERE e.deptno=d.deptno ; |
这个时候的视图是由多张基表(实体表)所组成,那么下面进行更新操作。
范例:更新视图
|
UPDATE myview SET sal=9000,dname='啊见部' WHERE empno=7369 ; |
|
UPDATE myview SET sal=9000,dname='啊见部' WHERE empno=7369 * 第 1 行出现错误: ORA-01776: 无法通过联接视图修改多个基表 |
虽然复杂视图无法更新,但是简单视图还是可以更新的,所以下面来学习两个子句控制更新。
1、 WITH CHECK OPTION子句:保证视图的创建条件不被更新
如果说现在有以下一个视图:
|
CREATE OR REPLACE VIEW myview AS SELECT * FROM emp WHERE deptno=20 ; |
此视图是创建了一张只包含20部门雇员信息的数据。这个时候“deptno=20”是整个视图的创建条件。那么不应该被更新,可是默认情况下却可以更新。
|
UPDATE myview SET deptno=40 WHERE empno=7369 ; |
这个时候发现更新语句可以正常执行完毕,更新之后发现虽然更新的是视图,但是影响的是实体表。可是这样的更新并不合理。
范例:建立一个新的视图
|
CREATE OR REPLACE VIEW myview AS SELECT * FROM emp WHERE deptno=20 WITH CHECK OPTION ; |
此时创建的视图如果再次执行更新就会出现错误。
|
ORA-01402: 视图 WITH CHECK OPTION where 子句违规 |
2、 WITH READ ONLY
使用“WITH CHECK OPTION”子句只能够保证创建条件不被更新,但是其它字段依然可以更新。
范例:将smith的工资修改为9000
|
UPDATE myview SET sal=9000 WHERE empno=7369 ; |
这个时候可以正常的执行完毕,而且会影响原始数据表,但是视图本身并没有包含任何的真实数据,它都属于映射数据。所以视图最好的创建原则就是不能更新,作为只读。
|
CREATE OR REPLACE VIEW myview AS SELECT * FROM emp WHERE deptno=20 WITH READ ONLY ; |
这个时候再次更新会出现如下的错误提示:
|
ORA-42399: 无法对只读视图执行 DML 操作 |
虽然视图可以很好的帮助项目实现分工,但是这也只是针对于正规项目,如果是正规项目,视图的数量是非常庞大的,要远远多于表的数量。
3.3、同义词
同义词 = 近义词,在之前一直使用一张dual的虚拟表,那么这张虚拟表到底是属于谁的呢?
经过分析发现,dual是属于sys的表,因为不同用户之间的表访问应该加上用户名,即:如果在scott用户下要想访问dual,则应该使用的是“sys.dual”来操作,这个实际上就是同义词的概念。
dual = sys.dual,等于说“dual”是一个同义词。如果用户要想创建属于自己的同义词,则可以使用如下的语法完成:
|
CREATE [PUBLIC] SYNONYM 同义词名称 FOR 用户名.表名称 ; |
范例:将scott.emp表创建成emp的同义词
|
CREATE SYNONYM emp FOR scott.emp ; |
同义词创建完成之后就可以利用“emp”这个同义词的名字访问scott.emp表。
|
SELECT * FROM emp ; |
但是此时所创建的同义词只能够被sys一个用户使用。
|
CONN system/manager ; |
如果希望一个同义词可以被所有的用户都使用,那么就创建公共同义词。
|
CONN sys/change_on_install AS SYSDBA ; DROP SYNONYM emp ; CREATE PUBLIC SYNONYM emp FOR scott.emp ; CONN system/manager ; SELECT * FROM emp ; |
同义词的讲解只是为了解释dual而出来的,本身没有任何的实际意义,有这么个概念就行了。
3.4、索引
索引是一种相对而言提升数据库性能的操作手段。但是一定要记住,永远不会存在有绝对性的性能调整。
范例:假设现在有如下的一个查询
|
SET AUTOTRACE ON ; SELECT * FROM emp WHERE sal>1500 ; |
那么现在假设emp表中有30W条记录,而在20W条记录之后就绝对不会存在满足于以上条件的数据了,可是呢,这个时候查询依然会采用逐行扫描(全表扫描)的方式完成。那么这个时候绝对是属于浪费时间的操作。那么怎么解决呢?
最好的方式就是进行排序,而后发现不满足的地方就不查询了。那问题是,排序是在查询完成后进行的,而且每种查询的条件也不同。这个时候如何排序就成为了要思考的问题了,这种排序一定是针对于sal排序,而且可以在查询的时候立刻给予查询的支持(只查询满足条件的部分数据)。那么这个时候唯一可以采用的方案就是建立一棵树。假设说现在给出的sal数据如下:“1500、1250、1100、950、800、2450、1600、2850、3000、5000”。
树的实现原理:使用第一个数据作为根节点,如果比根节点小的放在左子树,比根节点大的放在右子树。
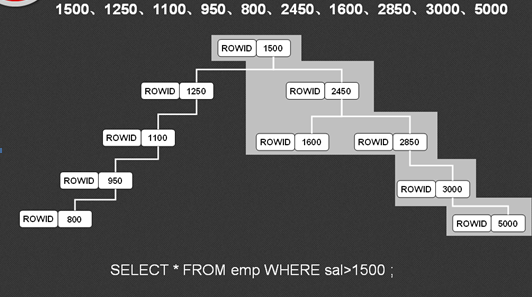
如果说现在有了这样一棵树的支持,那么在进行查询数据的时候就一定不会使用全表扫描了,那么查询性能就会提升,而这样的树就可以通过索引进行创建,在Oracle中索引的创建方式有两种:
· 如果字段设置了主键约束或者是唯一约束,那么就会自动创建索引;
· 用户可以直接创建一个索引对象。
范例:在sal字段上创建索引
|
CREATE INDEX emp_sal_ind ON emp(sal) ; |
当索引创建完成之后,下面再次发出查询指令。这个时候发现出现的所按照索引的方式进行扫描,性能有所提升。
那么在整个操作过程之中,树是一个最为关键的实现操作,那么这棵树的数据都是由数据表提供的,应该与数据表同步,那么如果说这个时候发生了更新操作,而且更新操作的就是设置索引的字段,那么树一定要发生变化。
删除索引
【语法】
DROP INDEX <index_name>;
【示例】
--删除索引
Drop index index_emp_empno;
Drop index index_emp_ename;
Drop index index_emp_ename_job;
Drop index index_emp_job_sal;
思考一种环境:现在有一个数据库的A表,那么这张表平均每秒要更新20次,同时这张表要按照每秒并发查询30次的方式供用户进行指定条件的检索,那么请问如何可以提升性能,假设此表中的数据已经3亿条,每天的更新量有3000W条。
如果要想保证查询性能,那么首先唯一能想到的就是索引,但是如果直接使用索引呢?由于索引依靠树来进行检索,那么如果每次更新记录,就会造成树的修改,而数据量一大,树的修改所耗费的时间就会很长,那么使用索引后反而会影响到性能,怎么解决呢?
牺牲数据的实时性,准备两张表或者是两个数据库,一个数据库专门负责处理更新问题,另外一个数据库专门负责处理查询问题,等到用户使用量小的时候做一个差异性的增加,而后由服务器统一的进行索引的生成。
所以总结如下:
索引是建立在数据库表中的某些列的上面,是与表关联的,可提供快速访问数据方式,但会影响增删改的效率;常用类型(按逻辑分类):单列索引和组合索引、唯一索引和非唯一索引。
什么时候要创建索引
(1)在经常需要搜索、主键、连接的列上
(2)表很大,记录内容分布范围很广
(3)在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的
(4)在经常使用在WHERE子句中的列上面创建索引
什么时候不要创建索引
(1)表经常进行 INSERT/UPDATE/DELETE 操作
(2)表很小(记录超少)
(3)列名不经常作为连接条件或出现在 WHERE 子句中
(4)对于那些定义为text, image和bit, blob数据类型的列不应该增加索引
3.5、用户权限控制
对于权限控制除非是你一个人从无到有开发,否则跟你真没什么联系。交给数据库管理人员。对于DCL语言而言主要就是由两个命令组成:GRANT、REVOKE。
1、 如果要想进行用户的操作,那么首先要具备用户的管理权限,可以使用sys用户操作,利用sys登录
方式一
Sqlplus
Sys
123 as sysdba
方式二:
Sqlplus /nolog
Conn sys/123 as sysdba
|
CONN sys/change_on_install AS SYSDBA ; |
2、 创建用户对象,用户名:dog / wangwang
|
CREATE USER dog IDENTIFIED BY wangwang ; |
此时用户已经创建成功,但是如果直接使用此用户登录,这个时候会出现如下的错误提示:
|
ORA-01045: user DOG lacks CREATE SESSION privilege; logon denied |
提示用户缺少创建SESSION的权限,每一个用户连接到服务器上之后都使用一个SESSION表示,如果没有创建SESSION的权限就表示无法登录。
3、 为dog用户授予创建SESSION的权限
|
GRANT CREATE SESSION TO dog ; |
此时将“CREATE SESSION”的权限授予了dog用户,那么dog用户就可以进行登录了。但是即使登录之后也什么都干不了,例如,现在执行以下的程序。
|
CREATE SEQUENCE myseq ; CREATE TABLE mytab ( id NUMBER , name VARCHAR2(20) , CONSTRAINT pk_id PRIMARY KEY(id) ) ; |
4、 继续为dog用户授权
|
GRANT CREATE TABLE TO dog ; |
但是发现现在的权限还是不够,因为一个新用户本身是不带有任何权限的,那么如果没有权限就无法进行操作,可是如果都是这样分开授权,那么授权人员也该累死了。所以为了方便进行权限的管理,在Oracle中提供了两个角色:CONNECT、RESOURCE。
5、 将角色授予用户
|
GRANT CONNECT,RESOURCE TO dog ; |
那么这个时候的dog用户就具备了操作的基本权限。在所有的系统之后标准的作法是在登录的时候取用户权限。在Oracle 11g之后对于部分权限采用实时性的操作。
6、 用户管理
当用户创建成功之后,那么现在就需要对用户进行维护,首先最麻烦的问题就在于用户丢失密码。
A、 修改用户密码
|
ALTER USER dog IDENTIFIED BY miaomiao ; |
B、 锁定用户
|
ALTER USER dog ACCOUNT LOCK ; |
C、 解锁用户
|
ALTER USER dog ACCOUNT UNLOCK ; |
此时已经实现了用户的授权(系统权限),可是除了系统权限之外,还有对象权限(针对于不同的用户的权限)。例如,现在使用dog用户访问scott.emp表。
|
SELECT * FROM scott.emp ; SELECT * FROM scott.emp * 第 1 行出现错误: ORA-00942: 表或视图不存在 |
所谓的对象权限指的是一个用户所具备的权限,那么主要的就是四个:SELECT、INSERT、DELETE、UPDATE。
例如:给demo001_user中的mytab表赋予正删改查的权限
grant insert, update,select on demo001_user.mytab to demo001_user;
7、 将scott.emp表的查询和增加权限授予dog用户
|
GRANT SELECT,INSERT ON scott.emp TO dog ; |
不同用户之间如果要访问必须有权限的配置。
8、 撤消权限
|
REVOKE SELECT,INSERT ON scott.emp FROM dog ; REVOKE CONNECT,RESOURCE FROM dog ; REVOKE CREATE SESSION,CREATE TABLE FROM dog ; |
权限撤消之后,dog用户就什么都没有了,但是dog用户有创建表,这些资源依然被保留。
9、 删除用户
|
DROP USER dog CASCADE ; |
删除之后,所对应的所有资源就都被清空了。
3.6、数据库备份(理解)
此部分的内容主要是给那些有可能独立开发的程序员准备的,初期大家只需要了解。
3.6.1、数据的导出与导入
此种方式主要是针对于一个用户下的所有数据资源进行的备份,备份的时候会提供有一个可以再恢复数据的*.SQL文件,下面就针对于scott用户做一个备份。
1、数据导出
· 首先将所有的备份数据保存在d:\backup目录下;
· 使用cmd进入命令行方式,输入“D:”,之后建立文件夹“md backup”;
· 输入exp指令;
· 输入用户名和密码,之后会出现“导出文件: EXPDAT.DMP”;
导出指定的表(表模式)
exp scott/123@orcl file=d:/info001.dmp tables=(emp) log=d:/info001.log
导出整个数据库
(这是dba的权限,所以现授权dba)
exp scott/123@orcl file=d:/info002.dmp full=y log=d:/info002.log
2、数据导入
· 通过命令行方式进入到备份文件所在的目录;
· 输入imp指令;
· 导入文件: EXPDAT.DMP;
· 导入整个导出文件 (yes/no): no > yes
Imp demo001_user/123 file=e:\sampDB2.dmp FULL='YES' log=e:\sampDB2.log
3.6.2、数据库的冷备份
所谓的冷备份就是指的数据库的归档备份。此类的备份在企业之中使用较多,而且备份的效果也是最好的。
如果要使用数据库冷备份,则必须由超级管理员进行,主要备份如下的内容:
· 控制文件:控制整个Oracle的实例服务信息,通过“v$controlfile”找到;
· 重做日志文件:灾难恢复,通过“v$logfile”找到;
· 数据文件:保存真实数据的文件块,通过“v$datafile”找到;
· 数据的核心配置文件(pfile),通过“SHOW PARAMETER pfile”找到。
1、 使用超级管理员登录
|
CONN sys/change_on_install AS SYSDBA ; |
2、 查询所有的控制文件
|
SELECT * FROM v$controlfile ; |
3、 查询所有的日志文件路径
|
SELECT * FROM v$logfile ; |
4、 找到数据文件
|
SELECT * FROM v$datafile ; |
5、 找到pfile文件
|
SHOW PARAMETER pfile ; |
6、 记录好以上所有文件的路径,而后关闭数据库实例(在sqlplus里操作)
|
SHUTDOWN immediate ; |
7、 将以上文件全部拷贝到备份路径下;
8、 重新启动数据库实例;
|
STARTUP ; |
这类方式只适合于可以关闭的情况。
三、Oracle 中的触发器
(一)触发器简介
触发器的定义就是说某个条件成立的时候,触发器里面所定义的语句就会被自动的执行。
因此触发器不需要人为的去调用,也不能调用。
(二)触发器语法
create or replace trigger 名字before|after insert|delete|update
on 表名
for each row begin
sql 语句
end;
(三)触发器案例
trigger_name:触发器名称
before | after : 指定触发器是在触发事件发生之前触发还暗示发生之后触发
trigger_event:触发事件,在DML触发器中主要为insert、update、delete等
table_name:表名,表示发生触发器作用的对象
for each row:指定创建的是行级触发器,若没有该子句则创建的是语句级触发器
when trigger_condition:添加的触发条件
trigger_body:触发体,是标准的PL/SQL语句块
(1) 结合序列完成表中字段的值自动增加create or replace trigger t1 before
insert on ta
for each row begin
-- :new 新添加到数据库的当前这条 sql 语句
-- :new. 字段 新添加到数据库的当前这条 sql 语句 中的指定字段
:new.id := s5.nextval;
end;
对表进行添加动作的时候,表中的主键值就会实现自动增长功能。完成数据备份功能
复制一张表
create table copyta as select * from ta where 1=2;
创建备份触发器
create or replace trigger t2 before
delete or update on ta
for each row begin
insert into copyta values(:old.id,:old.name,:old.hir); end;
如果对当前表执行删除或者是更新动作那么表中原来的数据就会保存早备份表中。
删除触发器
drop trigger 触发器名称 ;
触发器案例:
create sequence seq_test ;
create or replace trigger modify_stu
before insert on student
for each row
declare
next_id number;
begin
select seq_test.nextval into next_id from dual;
:new.id :=next_id;
end;
insert into student(stu_no,stu_name,stu_age,stu_major) values('NO1','张三',20,'中文系');
select * from student ;
create or replace trigger modify_stu
after insert or delete or update of stu_name
on student
for each row
begin
if inserting then
insert into stu_log values(1,'insert',sysdate,:new.stu_name);
elsif deleting then
insert into stu_log values(2,'delete',sysdate,:old.stu_name);
elsif updating then
insert into stu_log values(3,'update_old',sysdate,:old.stu_name);
insert into stu_log values(4,'update_new',sysdate,:new.stu_name);
end if;
end;
insert into student values(1,'NO2','李四',21,'数学系'); --插入一条数据
delete student where stu_name='张三'; --删除一条数据
update student set stu_age=19 where stu_name='李四'; --修改李四的年龄
update student set stu_name='王二' where stu_name='李四'; --修改李四的
select * from student
select * from stu_log
四、Oracle 中的存储过程
(一)存储过程简介
存储过程(Stored Procedure )是一组为了完成特定功能的 SQL 语句集,经编译后存储在数据库中。用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数) 来执行它。存储过程是数据库中的一个重要对象,任何一个设计良好的数据库应用程序都应该用到存储过程。 存储过程是由流控制和 SQL 语句书写的过程,这个过程经编译和优化后存储在数据库服务器中,应用程序使用时只要调用即可。
(二)存储过程语法
create or replace procedure 存储过程名称
is
begin
Sql 语句
end 存储过程名称 ;
(三)存储过程案例
1、没有参数的存储过程
create or replace procedure p1
is
begin
dbms_output.put_line(' 执行了 '); end p1;
2、带输入参数的存储过程
create or replace procedure p2(newname in varchar2)
is
begin
dbms_output.put_line(' 执行了 '||newname); end p2;
调用存储过程 p2 第一种调用方式: call p2(' 小黑 '); 第二种调用方式: declare
newname varchar2(32); begin
newname := ' 小红 '; p2(newname);
end;
3、携带输出参数的存储过程
create or replace procedure p3(newcount out number)
is
begin
-- into 关键字 将查询的结果赋值给变量 newcount select count(*) into newcount from ta;
dbms_output.put_line(' 执行了 ');
end p3;
4、调用存储过程 p3 declare
newcount number; begin
p3(newcount);
dbms_output.put_line(' 数据库中一共有 '||newcount||' 条数据 ');
end;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号