
Software_programming_RegExp
2019-12-24
处理字符串。
ref: https://www.w3cschool.cn/regexp/tfua1pq5.html
https://www.cnblogs.com/zery/p/3438845.html
基本的语法符号
. - 匹配任意一个字符
[] - 字符集匹配,匹配方括号中定义的字符集之一
[^] - 字符集否定匹配, 匹配没有在方括号中定义的字符
^ - 匹配开始位置
$ - 匹配结束位置
() - 定义子表达式
\n - 子表达式向前引用, n 为 1-9 之间的数字。由于此功能以超出正则语义,需要在字符串中回溯,因此
需要使用 NFA 算法进行匹配。
. 任意次匹配(零次或多次匹配) {m,n} - 至少n 次匹配;{m} 表示m次精确匹配, {m ,} 表示至少 m 次匹配。
? 最多一次匹配(零次或一次匹配)
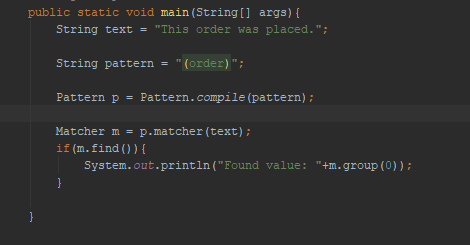
Java RegExp
Pattern pattern = Pattern.compile(正则表达式);
Matcher matcher = pattern.matcher(textContent);
if( matcher.find() ){
matcher.group(0);
}
2019-12-31
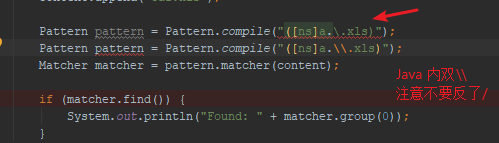
字符区间 [0-9] [A-Za-z0-9]

^ 取反操作 其作用域字符区间里列举的全部,而非紧跟在其后的单个字符。
2020-01-01 10:17:52
\d 数字 [0-9] \D 反
\w [a-zA-Z0-9_] 注意有个下划线, /W 反
\s [\f \r \n \t \v] 不包含\b 退格符 /S 反
\r\n\r\n windows 版本 消除空白
\n\n linux 版本
[\r]?\n[\r]?\n 综合版本
+ 匹配1次或者多次
* 匹配0次或者多次
?匹配0次或者1次
{ 最少数,最多数 }
+? * ? 从贪婪模式转换为 懒惰模式
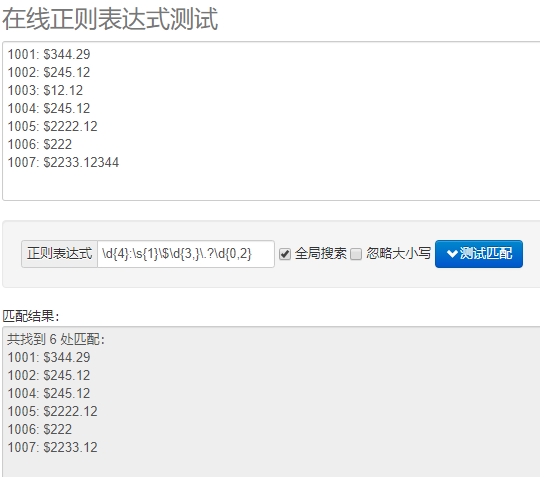
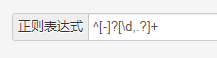
2020-01-13 19:55:31
需要从 包含 美式 的字符中提取出 数字 与 其单位


 浙公网安备 33010602011771号
浙公网安备 33010602011771号