Vue 组件中 data 为什么必须是函数
1. 前言
在学习vue的时候,一直纳闷一件事:组件的data数据为什么必须要以函数返回的形式,为什么不是简单的对象形式呢?遂带着问题去翻官方文档,文档中自然也写明了这么做的原因,本篇博文以官方文档给出的原因为基础,并加上具体的例子,来阐述这么设计的原因。
2.正文
组件是可复用的vue实例,一个组件被创建好之后,就可能被用在各个地方,而组件不管被复用了多少次,组件中的data数据都应该是相互隔离,互不影响的,基于这一理念,组件每复用一次,data数据就应该被复制一次,之后,当某一处复用的地方组件内data数据被改变时,其他复用地方组件的data数据不受影响,如下面这个例子:
<template>
<div class="title">
<h1>按钮被点击了{{ count }}次</h1>
<button v-on:click="count++">点击</button>
</div>
</template>
<script>
export default {
name: 'BtnCount',
data () {
return {
count: 0
}
}
}
</script>
<style scoped>
.title {
background-color: red
}
</style>
该组件被复用了三次,但每个复用的地方组件内的count数据相互不受影响,它们各自维护各自内部的count。

能有这样效果正是因为上述例子中的data不是一个单纯的对象,而是一个函数返回值的形式,所以每个组件实例可以维护一份被返回对象的独立拷贝,如果我们将上述例子中的data修改为:
data : {
count: 0
}
那么就会造成无论在哪个组件里改变了count值,都会影响到其他两个组件里的count。
这是因为当data如此定义后,这就表示所有的组件实例共用了一份data数据,因此,无论在哪个组件实例中修改了data,都会影响到所有的组件实例。
3.总结
组件中的data写成一个函数,数据以函数返回值形式定义,这样每复用一次组件,就会返回一份新的data,类似于给每个组件实例创建一个私有的数据空间,让各个组件实例维护各自的数据。而单纯的写成对象形式,就使得所有组件实例共用了一份data,就会造成一个变了全都会变的结果。
目标Vue版本:2.5.17-beta.0
vue源码注释:https://github.com/SHERlocked93/vue-analysis
声明:文章中源码的语法都使用 Flow,并且源码根据需要都有删节(为了不被迷糊 @_@),如果要看完整版的请进入上面的github地址,本文是系列文章,文章地址见底部~
1. 异步更新
上一篇文章我们在依赖收集原理的响应式化方法 defineReactive 中的 setter 访问器中有派发更新 dep.notify() 方法,这个方法会挨个通知在 dep 的 subs 中收集的订阅自己变动的watchers执行update。一起来看看 update 方法的实现:
如果不是 computed watcher 也非 sync 会把调用update的当前watcher推送到调度者队列中,下一个tick时调用,看看 queueWatcher :
这里使用了一个 has 的哈希map用来检查是否当前watcher的id是否存在,若已存在则跳过,不存在则就push到 queue 队列中并标记哈希表has,用于下次检验,防止重复添加。这就是一个去重的过程,比每次查重都要去queue中找要文明,在渲染的时候就不会重复 patch 相同watcher的变化,这样就算同步修改了一百次视图中用到的data,异步 patch 的时候也只会更新最后一次修改。
这里的 waiting 方法是用来标记 flushSchedulerQueue 是否已经传递给 nextTick 的标记位,如果已经传递则只push到队列中不传递 flushSchedulerQueue 给 nextTick,等到 resetSchedulerState 重置调度者状态的时候 waiting 会被置回 false 允许 flushSchedulerQueue 被传递给下一个tick的回调,总之保证了 flushSchedulerQueue 回调在一个tick内只允许被传入一次。来看看被传递给 nextTick 的回调 flushSchedulerQueue 做了什么:
在 nextTick 方法中执行 flushSchedulerQueue 方法,这个方法挨个执行 queue 中的watcher的 run 方法。我们看到在首先有个 queue.sort() 方法把队列中的watcher按id从小到大排了个序,这样做可以保证:
- 组件更新的顺序是从父组件到子组件的顺序,因为父组件总是比子组件先创建。
- 一个组件的user watchers(侦听器watcher)比render watcher先运行,因为user watchers往往比render watcher更早创建
- 如果一个组件在父组件watcher运行期间被销毁,它的watcher执行将被跳过
在挨个执行队列中的for循环中,index < queue.length 这里没有将length进行缓存,因为在执行处理现有watcher对象期间,更多的watcher对象可能会被push进queue。
那么数据的修改从model层反映到view的过程:数据更改 -> setter -> Dep -> Watcher -> nextTick -> patch -> 更新视图
2. nextTick原理
2.1 宏任务/微任务
这里就来看看包含着每个watcher执行的方法被作为回调传入 nextTick 之后,nextTick 对这个方法做了什么。不过首先要了解一下浏览器中的 EventLoop、macro task、micro task几个概念,不了解可以参考一下 JS与Node.js中的事件循环 这篇文章,这里就用一张图来表明一下后两者在主线程中的执行关系:
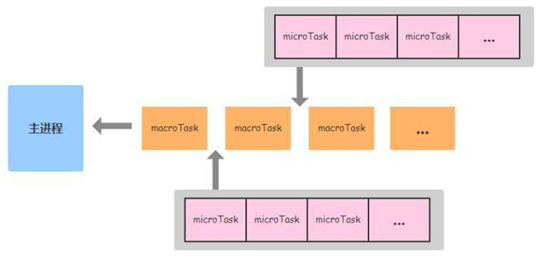
解释一下,当主线程执行完同步任务后:
- 引擎首先从macrotask queue中取出第一个任务,执行完毕后,将microtask queue中的所有任务取出,按顺序全部执行;
- 然后再从macrotask queue中取下一个,执行完毕后,再次将microtask queue中的全部取出;
- 循环往复,直到两个queue中的任务都取完。
浏览器环境中常见的异步任务种类,按照优先级:
macro task:同步代码、setImmediate、MessageChannel、setTimeout/setIntervalmicro task:Promise.then、MutationObserver
有的文章把 micro task 叫微任务,macro task 叫宏任务,因为这两个单词拼写太像了 -。- ,所以后面的注释多用中文表示~
先来看看源码中对 micro task 与 macro task 的实现: macroTimerFunc、microTimerFunc
flushCallbacks 这个方法就是挨个同步的去执行callbacks中的回调函数们,callbacks中的回调函数是在调用 nextTick 的时候添加进去的;那么怎么去使用 micro task 与 macro task 去执行 flushCallbacks 呢,这里他们的实现 macroTimerFunc、microTimerFunc 使用浏览器中宏任务/微任务的API对flushCallbacks 方法进行了一层包装。比如宏任务方法 macroTimerFunc=()=>{ setImmediate(flushCallbacks) },这样在触发宏任务执行的时候 macroTimerFunc() 就可以在浏览器中的下一个宏任务loop的时候消费这些保存在callbacks数组中的回调了,微任务同理。同时也可以看出传给 nextTick 的异步回调函数是被压成了一个同步任务在一个tick执行完的,而不是开启多个异步任务。
注意这里有个比较难理解的地方,第一次调用 nextTick 的时候 pending 为false,此时已经push到浏览器event loop中一个宏任务或微任务的task,如果在没有flush掉的情况下继续往callbacks里面添加,那么在执行这个占位queue的时候会执行之后添加的回调,所以 macroTimerFunc、microTimerFunc 相当于task queue的占位,以后 pending 为true则继续往占位queue里面添加,event loop轮到这个task queue的时候将一并执行。执行 flushCallbacks 时 pending 置false,允许下一轮执行 nextTick 时往event loop占位。
可以看到上面 macroTimerFunc 与 microTimerFunc 进行了在不同浏览器兼容性下的平稳退化,或者说降级策略:
macroTimerFunc:setImmediate -> MessageChannel -> setTimeout。首先检测是否原生支持setImmediate,这个方法只在 IE、Edge 浏览器中原生实现,然后检测是否支持 MessageChannel,如果对MessageChannel不了解可以参考一下这篇文章,还不支持的话最后使用setTimeout;
为什么优先使用setImmediate与MessageChannel而不直接使用setTimeout呢,是因为HTML5规定setTimeout执行的最小延时为4ms,而嵌套的timeout表现为10ms,为了尽可能快的让回调执行,没有最小延时限制的前两者显然要优于setTimeout。microTimerFunc:Promise.then -> macroTimerFunc。首先检查是否支持Promise,如果支持的话通过Promise.then来调用flushCallbacks方法,否则退化为macroTimerFunc;
vue2.5之后nextTick中因为兼容性原因删除了微任务平稳退化的MutationObserver的方式。
2.2 nextTick实现
最后来看看我们平常用到的 nextTick 方法到底是如何实现的:
nextTick 在这里分为三个部分,我们一起来看一下;
- 首先
nextTick把传入的cb回调函数用try-catch包裹后放在一个匿名函数中推入callbacks数组中,这么做是因为防止单个cb如果执行错误不至于让整个JS线程挂掉,每个cb都包裹是防止这些回调函数如果执行错误不会相互影响,比如前一个抛错了后一个仍然可以执行。 - 然后检查
pending状态,这个跟之前介绍的queueWatcher中的waiting是一个意思,它是一个标记位,一开始是false在进入macroTimerFunc、microTimerFunc方法前被置为true,因此下次调用nextTick就不会进入macroTimerFunc、microTimerFunc方法,这两个方法中会在下一个macro/micro tick时候flushCallbacks异步的去执行callbacks队列中收集的任务,而flushCallbacks方法在执行一开始会把pending置false,因此下一次调用nextTick时候又能开启新一轮的macroTimerFunc、microTimerFunc,这样就形成了vue中的event loop。 - 最后检查是否传入了
cb,因为nextTick还支持Promise化的调用:nextTick().then(() => {}),所以如果没有传入cb就直接return了一个Promise实例,并且把resolve传递给_resolve,这样后者执行的时候就跳到我们调用的时候传递进then的方法中。
Vue源码中 next-tick.js 文件还有一段重要的注释,这里就翻译一下:
在vue2.5之前的版本中,nextTick基本上基于micro task来实现的,但是在某些情况下micro task具有太高的优先级,并且可能在连续顺序事件之间(例如#4521,#6690)或者甚至在同一事件的事件冒泡过程中之间触发(#6566)。但是如果全部都改成macro task,对一些有重绘和动画的场景也会有性能影响,如 issue #6813。vue2.5之后版本提供的解决办法是默认使用micro task,但在需要时(例如在v-on附加的事件处理程序中)强制使用macro task。
为什么默认优先使用 micro task 呢,是利用其高优先级的特性,保证队列中的微任务在一次循环全部执行完毕。
强制 macro task 的方法是在绑定 DOM 事件的时候,默认会给回调的 handler 函数调用 withMacroTask 方法做一层包装 handler = withMacroTask(handler),它保证整个回调函数执行过程中,遇到数据状态的改变,这些改变都会被推到 macro task 中。以上实现在 src/platforms/web/runtime/modules/events.js 的 add 方法中,可以自己看一看具体代码。
刚好在写这篇文章的时候思否上有人问了个问题 vue 2.4 和2.5 版本的@input事件不一样 ,这个问题的原因也是因为2.5之前版本的DOM事件采用 micro task ,而之后采用 macro task,解决的途径参考 < Vue.js 升级踩坑小记> 中介绍的几个办法,这里就提供一个在mounted钩子中用 addEventListener 添加原生事件的方法来实现,参见 CodePen点击预览。
3. 一个例子
说这么多,不如来个例子,执行参见 CodePen点击预览
执行以下看看结果:
为什么是这样的结果呢,解释一下:
- 同步方式: 当把data中的name修改之后,此时会触发name的
setter中的dep.notify通知依赖本data的render watcher去update,update会把flushSchedulerQueue函数传递给nextTick,render watcher在flushSchedulerQueue函数运行时watcher.run再走diff -> patch那一套重渲染re-render视图,这个过程中会重新依赖收集,这个过程是异步的;所以当我们直接修改了name之后打印,这时异步的改动还没有被patch到视图上,所以获取视图上的DOM元素还是原来的内容。 - setter前: setter前为什么还打印原来的是原来内容呢,是因为
nextTick在被调用的时候把回调挨个push进callbacks数组,之后执行的时候也是for循环出来挨个执行,所以是类似于队列这样一个概念,先入先出;在修改name之后,触发把render watcher填入schedulerQueue队列并把他的执行函数flushSchedulerQueue传递给nextTick,此时callbacks队列中已经有了setter前函数了,因为这个cb是在setter前函数之后被push进callbacks队列的,那么先入先出的执行callbacks中回调的时候先执行setter前函数,这时并未执行render watcher的watcher.run,所以打印DOM元素仍然是原来的内容。 - setter后: setter后这时已经执行完
flushSchedulerQueue,这时render watcher已经把改动patch到视图上,所以此时获取DOM是改过之后的内容。 - Promise方式: 相当于
Promise.then的方式执行这个函数,此时DOM已经更改。 - setTimeout方式: 最后执行macro task的任务,此时DOM已经更改。
注意,在执行 setter前函数 这个异步任务之前,同步的代码已经执行完毕,异步的任务都还未执行,所有的 $nextTick 函数也执行完毕,所有回调都被push进了callbacks队列中等待执行,所以在setter前函数 执行的时候,此时callbacks队列是这样的:[setter前函数,flushSchedulerQueue,setter后函数,Promise方式函数],它是一个micro task队列,执行完毕之后执行macro task setTimeout,所以打印出上面的结果。
另外,如果浏览器的宏任务队列里面有setImmediate、MessageChannel、setTimeout/setInterval 各种类型的任务,那么会按照上面的顺序挨个按照添加进event loop中的顺序执行,所以如果浏览器支持MessageChannel, nextTick 执行的是 macroTimerFunc,那么如果 macrotask queue 中同时有 nextTick 添加的任务和用户自己添加的 setTimeout 类型的任务,会优先执行 nextTick 中的任务,因为MessageChannel 的优先级比 setTimeout的高,setImmediate 同理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号