从数据集中抽取特征
大多数数据挖掘算法都依赖于数值或类别型特征,从数据集中抽取数值和类别型特征,并选出最佳特征。
特征可用于建模, 模型以机器挖掘算法能够理解的近似的方式来表示现实
特征选择的另一个优点在于:降低真实世界的复杂度,模型比现实更容易操纵
特征选择
scikit-learn中的VarianceThreshold转换器可用来删除特征值的方差达不到最低标准 的特征。
import numpy as np x= np.arange(30).reshape((10,3))#10个个体、3个特征的数据集 print(x) x[:,1] = 1 #把所有第二列的数值都改为1 print(x) from sklearn.feature_selection import VarianceThreshold vt = VarianceThreshold() #VarianceThreshold转换器,用它处理数据集 Xt = vt.fit_transform(x) print(Xt)#第二列消失 print(vt.variances_)#输出每一列的方差 结果: [[ 0 1 2] [ 3 4 5] [ 6 7 8] [ 9 10 11] [12 13 14] [15 16 17] [18 19 20] [21 22 23] [24 25 26] [27 28 29]] [[ 0 1 2] [ 3 1 5] [ 6 1 8] [ 9 1 11] [12 1 14] [15 1 17] [18 1 20] [21 1 23] [24 1 26] [27 1 29]] [[ 0 2] [ 3 5] [ 6 8] [ 9 11] [12 14] [15 17] [18 20] [21 23] [24 26] [27 29]] [ 74.25 0. 74.25]
例子:用Adult数据集借助特征为复杂的现实世界建模,预测一个人是否年收入多于五万美元
import os import pandas as pd data_folder = os.path.join(os.getcwd(),'Data','adult') adult_filename = os.path.join(data_folder,'adult.data.txt') adult = pd.read_csv(adult_filename,header=None, names=["Age", "Work-Class", "fnlwgt", "Education", "Education-Num", "Marital-Status", "Occupation", "Relationship", "Race", "Sex", "Capital-gain", "Capital-loss", "Hours-per-week", "Native-Country", "Earnings-Raw"]) adult.dropna(how='all', inplace=True) #我们需要删除包含无效数字的行(设置inplace参数为真,表示改动当前数据框,而不是新建一个)。 # print(adult["Work-Class"].unique())#数据框的unique函数就能得到所有的工作情况 adult["LongHours"] = adult["Hours-per-week"] > 40 #通过离散化过程转换为类别型特征,把连续值转换为类别型特征 #测试单个特征在Adult数据集上的表现, X = adult[["Age", "Education-Num", "Capital-gain", "Capital-loss","Hours-per-week"]].values y = (adult["Earnings-Raw"] == ' >50K').values from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import chi2 transformer = SelectKBest(score_func=chi2, k=3) #使用SelectKBest转换器类,用卡方函数打分,初始化转换器 Xt_chi2 = transformer.fit_transform(X, y)#调用fit_transform方法,对相同的数据集进行预处理和转换 print(transformer.scores_)#每一列的相关性 from sklearn.tree import DecisionTreeClassifier from sklearn.cross_validation import cross_val_score clf = DecisionTreeClassifier(random_state=14) scores_chi2 = cross_val_score(clf, Xt_chi2, y, scoring='accuracy') print(scores_chi2)
结果:
[ 8.60061182e+03 2.40142178e+03 8.21924671e+07 1.37214589e+06
6.47640900e+03]
[ 0.82577851 0.82992445 0.83009306] #正确率达到83%
创建特征
特征之间相关性很强,或者特征冗余,会增加算法处理难度。出于这个原因,创建特征。
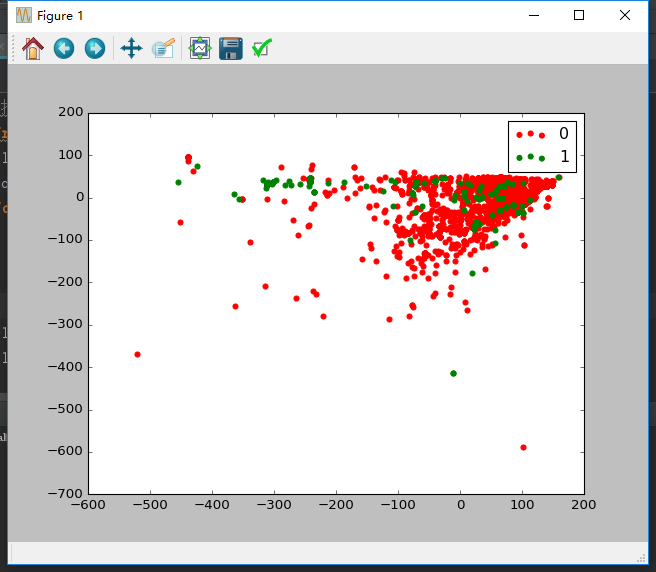
from collections import defaultdict import os import numpy as np import pandas as pd data_folder = os.path.join(os.getcwd(), "Data") data_filename = os.path.join(data_folder, "adult", "ad.data.txt") #前几个特征是数值,但是pandas会把它们当成字符串。要修复这个问题,我们需要编写将字符串转换为数字的函数,该函数能够把只包含数字的字符串转换为数字,把其余的转化为“NaN” def convert_number(x): try: return float(x) except ValueError: return np.nan converters = defaultdict(convert_number) converters[1558] = lambda x: 1 if x.strip() == "ad." else 0 #把类别这一列各个类别值由字符串转换为数值 for i in range(1558):#要这样定义才使得字典前面有定义 converters[i]=lambda x:convert_number(x) ads = pd.read_csv(data_filename, header=None, converters=converters) # print(ads[:5]) ads.dropna(inplace=True)#删除空行 #抽取用于分类算法的x矩阵和y数组 X = ads.drop(1558, axis=1).values y = ads[1558] from sklearn.decomposition import PCA #主成分分析算法(Principal Component Analysis,PCA)的目的是找到能用较少信息描述数据集的特征组合,用PCA算法得到的数据创建模型,不仅能够近似地表示原始数据集,还能提升分类任务的正确率 pca = PCA(n_components=5) Xd = pca.fit_transform(X) np.set_printoptions(precision=3, suppress=True) print(pca.explained_variance_ratio_ )#每个特征的方差 from sklearn.tree import DecisionTreeClassifier from sklearn.cross_validation import cross_val_score clf = DecisionTreeClassifier(random_state=14) scores_reduced = cross_val_score(clf, Xd, y, scoring='accuracy') print(scores_reduced) #把PCA返回的前两个特征做成图形 from matplotlib import pyplot as plt classes = set(y) colors = ['red', 'green'] for cur_class, color in zip(classes, colors): mask = (y == cur_class).values plt.scatter(Xd[mask, 0], Xd[mask, 1], marker='o', color=color, label=int(cur_class)) plt.legend() plt.show() 结果: [ 0.854 0.145 0.001 0. 0. ] [ 0.944 0.924 0.925]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号