Bagging与方差
在集成学习中,通常认为Bagging的主要作用是降低方差,而Boosting的主要作用是降低偏差。Boosting能降低偏差很好理解,因为其原理就是将多个弱学习器组合成强学习器。但Bagging为什么能降低方差?或者说,为什么将多个强学习器组合起来方差就会降低?这是本篇想要探讨的问题,而在这之前我认为有必要先搞清楚方差和偏差的基本概念。
方差
首先来看方差的定义:设X为随机变量,则方差\(Var(X) = E[(X-E[X])^2]\),表示X与平均值\(E[X]\)之间差异的平方的期望值,用于刻画X取值的散布程度。
方差有两个重要的性质,后文会用到:
- c为常数,则
- 独立随机变量之和的方差等于各变量的方差之和:
模型的偏差和方差
通常对于一个模型而言,比起其在训练集的表现,通常我们更关心其在测试集上的表现,或者说希望了解其泛化性能。偏差-方差分解 (bias-variance decomposition)就是其中的一种重要工具。下图形象地展示了偏差与方差的区别:

要理解模型的偏差和方差,首先需要做一个假设 (PRML中称之为“思维实验(thought experiment)")。假设我们有很多个数据集,每个数据集中的样本都是从总体分布\(\mathcal{P}\)中抽样而得。对于其中一个特定的数据集\(\mathcal{D}\),在此数据集上学习算法得到的单模型为\(f(\textbf{x};\mathcal{D})\)。可以看到对于不同的数据集\(\mathcal{D}\),学习到的模型都是不一样的,因此一个学习算法的期望预测为\(\bar{f}(\textbf{x}) = \mathbb{E}_{\mathcal{D}}[f(\textbf{x};\mathcal{D})]\),该值表示对于一个特定的样本\(\textbf{x}\),不同单模型的平均预测值。
偏差 (bias) 定义为:\(bias = \bar{f}(\textbf{x}) - y\),为模型的期望预测与真实值之间的差异。
方差 (variance) 定义为:\(variance = \mathbb{E}_\mathcal{D}[(f(\textbf{x};\mathcal{D})-\bar{f}(\textbf{x}))^2]\),衡量模型对不同数据集\(\mathcal{D}\)的敏感程度,也可以认为是衡量模型的不稳定性。若方差大,则表示数据的微小变动就能导致学习出的模型产生较大差异。可能的情形是在训练集上拟合的很好,到了测试集上由于数据的改变致使准确率下降很多,这是典型的过拟合。
而对比上文中方差的公式 (\(Var(X) = E[(X-E[X])^2]\)),这里实际上是将\(f(\textbf{x})\)视为随机变量,而其随机性来源于从同一个分布抽样得到的不同数据集。
因此有了偏差和方差的定义,我们就能推导出模型的期望泛化误差:

模型的期望泛化误差由偏差和方差组成。一般来说,简单模型偏差高,方差低;复杂模型方差高,偏差低。如下图所示:
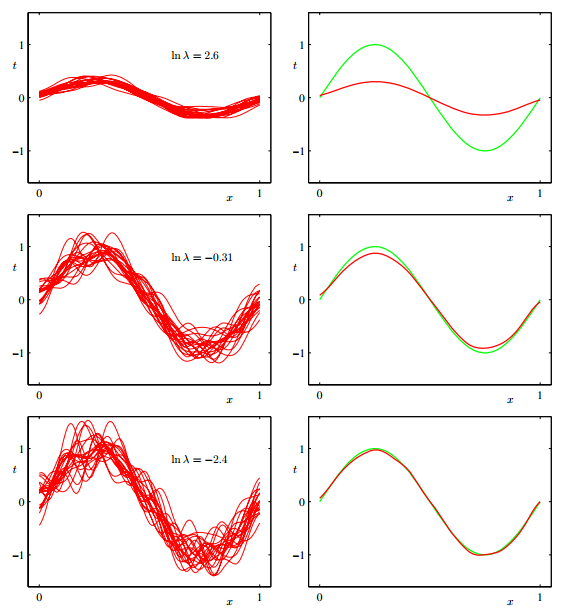
上图显示出模型复杂度对偏差和方差的影响,左面三幅图是100个数据集生成的100个模型,从上至下的单模型复杂度提升;右面三幅图中红线代表左图中各个单模型的平均,绿线表示真实函数。从左面三幅图可以看到模型越复杂方差也会越大,然而将模型平均后会比较接近真实函数,这说明复杂模型偏差小,而简单模型的情况则正好相反。
可以看到,一开始我们说偏差-方差分解的理论是一个“思维实验”,是因为其是带有幻想性质的。现实中我们不会有很多个数据集,而往往只有一个数据集,如果选用的算法比较复杂,即方差大,则更可能的情况是用我们手上的数据集拟合而成的模型恰好是离真实函数较远,这就产生了过拟合,而这种情况实际上经常发生。所以为什么要降低方差?一句话解释:方差大会导致过拟合,进而致使模型泛化性能降低。
通常降低方差的方法之一是将多个模型平均起来。假设有n个独立同分布的模型,每个模型的方差均为\(\sigma^2\),则利用上文中方差的性质 (1) 和 (2) 可得:
这样模型均值的方差仅为单模型方差的\(\frac1n\)。然而在只有一个数据集的情况下只能训练出一个模型,也就没法求平均。所以为了缓解这个问题,可以采用有放回抽样来模拟生成多个数据集,将每个数据集训练得到的模型平均来降低方差,即是Bagging的基本思想。
Bagging
设单模型的期望为\(\mu\),则Bagging的期望预测为
$$E(\frac{1}{n}\sum\limits_{i=1}^n X_i) = \frac1nE(\sum\limits_{i=1}^n X_i) = E(X_i) \approx \mu$$
说明Bagging整体模型的期望近似于单模型的期望,这意味整体模型的偏差也与单模型的偏差近似,所以Bagging通常选用偏差低的强学习器。
Bagging的抽样是有放回抽样,这样数据集之间会有重复的样本,因而违反了公式 (3) 中的独立性假设。在这种情况下设单模型之间具有相关系数 \(0<\rho<1\),则模型均值的方差为:$$Var(\frac{1}{n}\sum\limits_{i=1}^n X_i) = \frac{\sigma^2}{n} + \frac{n-1}{n}\rho\sigma^2$$
上式中随着n增大,第一项趋于0,第二项趋于\(\rho\sigma^2\),所以Bagging能够降低整体方差。而Bagging的拓展算法 —— 随机森林,则通过在树内部结点的分裂过程中,随机选取固定数量的特征纳入分裂的候选项,这样就进一步降低了单模型之间的相关性,总体模型的方差也比Bagging更低。
Reference :
- Christopher M. Bishop. Pattern Recognition and Machine Learning
- Yaser S. Abu-Mostafa, etc. Learning From Data
- 周志华.《机器学习》
- 陈希孺.《概率论与数理统计》
- http://scott.fortmann-roe.com/docs/BiasVariance.html
/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号