共轭梯度法求解协同过滤中的 ALS
协同过滤是一类基于用户行为数据的推荐方法,主要是利用已有用户群体过去的行为或意见来预测当前用户的偏好,进而为其产生推荐。能用于协同过滤的算法很多,大致可分为:基于最近邻推荐和基于模型的推荐。其中基于最近邻推荐主要是通过计算用户或物品之间的相似度来进行推荐,而基于模型的推荐则通常要用到一些机器学习算法。矩阵分解可能是被研究地最多的基于模型的推荐算法,在著名的 Netflix 大赛中也是大放异彩,核心思想是利用低维隐向量为每个用户和物品建模,进而推测用户对物品的偏好。现在的关键问题是如果要用矩阵分解的方法,该如何训练模型,即该如何获得隐向量? 目前主流的方法有两种:随机梯度下降 (简称 SGD,stochastic gradient decent) 和交替最小二乘法 (简称 ALS,alternating least squares),而本文的重点是后者,在阐述其基本原理的同时,引入共轭梯度法来加速模型的训练。
矩阵分解想要解决的问题
这里采用最常见的矩阵分解技术,由 SVD 演化而来。设共有 \(m\) 个用户,\(n\) 个物品,那么用户 - 物品 - 评分矩阵为 \(R \in \mathbb{R}^{m \times n}\) ,其中评分表示用户对物品的偏好。这个矩阵通常非常稀疏,其中大部分的评分元素都是缺失的,而我们的任务就是预测里面的缺失值。对于每个用户 \(u\) 设定一个用户向量 \(x_u \in \mathbb{R}^f\) ,每个物品 \(i\) 设定一个物品向量 \(y_i \in \mathbb{R}^f\) ,那么预测值用二者的内积表示 \(\hat{r}_{ui} = x_u^{\top}y_i\) 。于是可写出想要优化的目标函数:
想要最小化 \((1.1)\) 式最常用的方法就是 SGD (其中 \(\gamma\) 是学习率):
SGD 是一种迭代优化方法 (iterative method),而另一种方法,即本文的主角 ALS ,则是一种直接法 (direct method)。由于 \((1.1)\) 式中 \(x_u\) 和 \(y_i\) 都未知,所以该函数非凸,难以直接优化。然而如果将所有的 \(y_i\) 固定住视其为常数,那么 \((1.1)\) 式就变成了一个 关于 \(x_u\) 的最小二乘问题,可以直接求出解析解。于是可以先固定 \(y_i\) 求出 \(x_u\) ,再固定 \(x_u\) 求出 \(y_i\) ,二者不断交替,这个流程不断重复直至收敛。因而 ALS 全称为交替最小二乘法 (alternating least squares),这其实有点类似于 EM 算法中 E 步和 M 步的交替求解。
下面详细推导 ALS 的算法流程,上面已经定义了用户向量 \(x_u \in \mathbb{R}^f\) ,物品向量 \(y_i \in \mathbb{R}^f\) ,则所有用户可组合成一个矩阵 \(X \in \mathbb{R}^{m \times f}\) ,所有物品组合成一个矩阵 \(Y \in \mathbb{R}^{n \times f}\) ,整个评分矩阵为 \(R = XY^\top \in \mathbb{R}^{m \times n}\) 。则对 \((1.1)\) 式固定 \(Y\) 对 \(x_u\) 求偏导:
其中 \(r_{u*}\) 表示用户 \(u\) 评分过的所有物品, \(Y_u \in \mathbb{R}^{|r_{u*}| \times f}\) 表示用户 \(u\) 评分过的所有物品的矩阵,\(R_u \in \mathbb{R}^{|r_{u*}|}\) 表示用户 \(u\) 所有的物品评分向量。同理固定 \(X\) 对 \(y_i\) 求偏导:
ALS 相对于 SGD 有两个好处:
(1) 注意到 \((1.2)\) 和 \((1.3)\) 式每个 \(x_u\) 和 \(y_i\) 的计算都是独立的,因而可以并行计算提高速度。
(2) 对于隐式反馈数据集来说,用户和物品的组合太多,分分钟到亿级别。若有10000个用户,10000个物品,则会有 \(10000 \times 10000 = 10^8\) 种组合,用 SGD 一个个迭代是比较困难的。当然也可以为每个用户进行少量负采样,但这不是本文的重点,在此略过。而用 ALS 则可以通过一些矩阵转换技巧来高效计算,不过在这之前,先来看下何为隐式反馈数据集?
显式反馈 Vs. 隐式反馈
上文 ALS 的推导使用的是显式反馈数据,特点是都有显式评分,比如 MovieLens 数据集中的 1-5 分或是豆瓣上的 1 到 5 星。这些评分很能反映用户对物品的偏好,像豆瓣上打 5 星表示力荐,打 1 星表示很差。相较而言,隐式反馈数据大都来源于用户的行为,如物品的购买记录,网页的浏览记录,视频的观看时长等等。隐式反馈一般有如下特点:
(1) 数据总量大。比如很多人都在淘宝上买东西留下记录,却很少人会去给好评差评;每天在网上浏览了很多文章,却很少点赞。
(2) 没有负反馈。这点是比较致命的,比如看过一部电影代表对其的偏好,但若没看过一部电影并不代表不喜欢这部电影,可能是在待观看列表里面,然而从数据中这一点无法得知,这导致数据的噪音大。而如果只用有反馈的数据进行建模,会导致严重的过拟合。
如上面第一点所述,实际生活中显式反馈的评分数据是比较少的,而隐式反馈数据却非常丰富,因而重要性越来越高。为了解决其没有负反馈的问题,这里采用 Hu 等人在论文《Collaborative Filtering for Implicit Feedback Datasets》中描述的方法,引入用户对于物品的偏好系数 \(p_{ui}\) :
\(r_{ui}\) 表示用户对物品的反馈,如购买、搜索等行为,上式表明只要有反馈,\(p_{ui}\) 皆为 \(1\) 。此外还引入用户对于物品的置信度 $c_{ui} = 1 + \alpha r_{ui} $, 可以看出即使 \(r_{ui} = 0\) ,\(c_{ui}\) 也不为零,并且随着 \(r_{ui}\) 的增长而增长。Hu 的论文中的场景是电视剧推荐,因而 \(r_{ui}\) 表示观看时长或收看次数。于是写出目标函数:
\((1.4)\) 和 \((1.1)\) 式虽然长得很像,但实际使用会有很大区别,\((1.1)\) 式仅考虑用户评过分的样本,而 \((1.4)\) 式是考虑所有用户和物品的组合,比如 MovieLens 1M 数据集有100万样本,6000个用户,3500部电影,总的组合数是 \(6000 \times 3500 = 2.1 \times 10 ^7\) ,是样本数的 21 倍,如果用 SGD 那将会比显式数据集慢很多。
另外仔细观察 \((1.1)\) 式,固定所有的 \(y_i\) ,求解最优的 \(x_u\) ,从形式上来说就是一个 Ridge Regression 问题,因而 \((1.4)\) 式相当于为每个用户 - 物品组合加上了权重 \(c_{ui}\),因而该算法也被称为 WRR (weighted ridge regression) 。
要优化 \((1.4)\) 式,还是 ALS 的思路,固定 \(Y\) 对 \(x_u\) 求偏导:
其中 \(Y \in \mathbb{R}^{n \times f}\) 为所有物品隐向量组成的矩阵,\(C^u \in \mathbb{R}^{n \times n}\) 为对角矩阵,其对角线上的元素为用户 \(u\) 对所有物品的置信度 \(c_{ui}\),即 \(C^u_{ii} = c_{ui}\) ,由上文可知因为 \(r_{ui} \geqslant 0\) ,所以 \(c_{ui} \geqslant 1\)。\(p(u) \in \mathbb{R}^n\) ,其元素为用户 \(u\) 对所有物品的偏好 \(p_{ui}\) 。
\((1.6)\) 式中的 \(Y^\top C^u Y\) 的计算复杂度达到了 \(\mathcal{O}(f^2n)\) ,在 \(n\) 很大的情况下是难以承受的,因而可以拆分成 \(Y^\top C^u Y = Y^\top Y + Y^\top (C^u - I)Y\),对于每个用户 \(u\) 来说, \(Y^\top Y\) 都是一样的,因而可以提前计算,而 \(C^u\) 对角线的元素大部分都为 \(1\) ,因而 \(C^u - I\) 是一个稀疏矩阵,整体 \(Y^\top C^u Y\) 的计算复杂度降到 \(\mathcal{O}(f^2n_u)\),\(n_u\) 是用户 \(u\) 产生过行为的物品数量,通常 \(n_u << n\) 。
同理,固定 \(X\) 对 \(y_i\) 求偏导得:
下面给出 \((1.6)\) 式的 Python 代码:
import numpy as np
from scipy.sparse import csr_matrix
def ALS(dataset, X, Y, reg, n_factors, alpha=10, user=True):
if user:
data = dataset.train_user # data是所有用户-物品-标签的嵌套字典,形如 {1:{2:1, 3:1, 5:1 ...}, 2: {2:1, 3:1 ...} ...}
m_shape = dataset.n_items
else:
data = dataset.train_item # data是所有物品-用户-标签的嵌套字典
m_shape = dataset.n_users
YtY = Y.T.dot(Y) + reg * np.eye(n_factors)
for s in data:
Cui_indices = list(data[s].keys())
labels = list(data[s].values())
Cui_values = np.array(labels) * alpha
Cui = csr_matrix((Cui_values, (Cui_indices, Cui_indices)), shape=[m_shape, m_shape]) # 构建 C^u - I 稀疏矩阵
pui_indices = list(data[s].keys())
pui = np.zeros(m_shape)
pui[pui_indices] = 1.0
A = YtY + np.dot(Y.T, Cui.dot(Y))
C = Cui + sparse.eye(m_shape, format="csr")
cp = C.dot(pui)
b = np.dot(Y.T, cp)
X[s] = np.linalg.solve(A, b)
另外根据 \((1.5)\) 式也可以拆分成 :
所以还有另一种代码更少且更快的实现方式:
def ALS(dataset, X, Y, reg, n_factors, alpha=10, user=True):
if user:
data = dataset.train_user
else:
data = dataset.train_item
YtY = Y.T.dot(Y)
for s in data:
A = YtY + reg * np.eye(n_factors)
b = np.zeros(n_factors)
for i in data[s]:
factor = Y[i]
confidence = 1 + alpha * data[s][i]
A += (confidence - 1) * np.outer(factor, factor) # 计算外积
b += confidence * factor
X[s] = np.linalg.solve(A, b)
假设 \((Y^\top C^uY + \lambda \,I)^{-1}\) 的矩阵求逆操作复杂度为 \(\mathcal{O}(f^3)\),那么所有用户 \(u\) 的总体计算复杂度为 \(\mathcal{O}(f^2 \mathcal{N}_u + f^3m)\) ,其中 \(\mathcal{N}_u = \sum_un_u\) ,为所有用户行为总量。可以看出该算法的计算复杂度虽然与总体数据量呈线性增长关系,然而会随着 \(f\) 的增加呈指数增长。 总之虽然比原来有改善但其实还是比较慢,所以接下来就轮到共轭梯度法出场了,但在此之前,先来看看传统的梯度下降法有什么问题。
梯度下降法的问题
我们的目标是最小化 \((1.4)\) 式,使得推荐结果和真实值越接近越好,传统的梯度下降法有两个缺点: 一是数据量大时迭代慢,二是函数等高线呈椭球面时,容易呈现一种来回震荡的趋势。下图显示出一种典型的“之字形”优化路径,同样的迭代方向可能不只走了一次,这造成了优化效率低下。
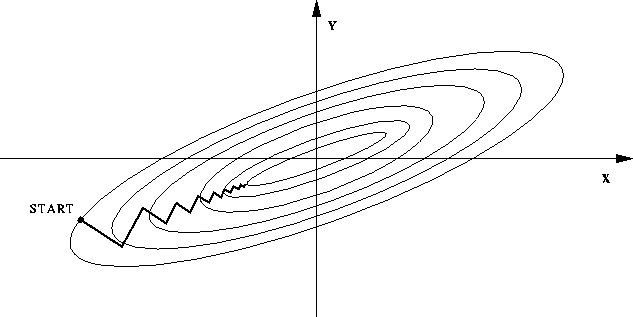
而比较理想的情况应该是这样,每一步的搜索方向都向最优点的方向靠拢:
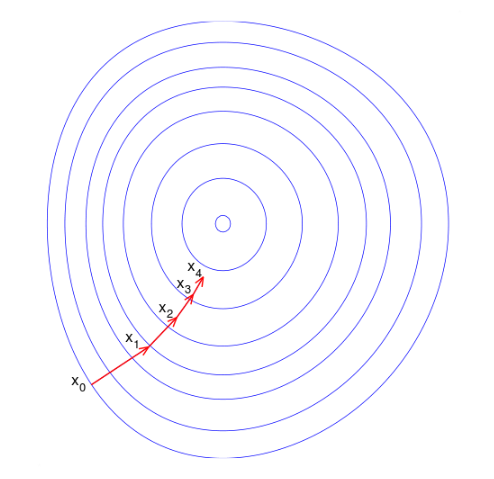
因此很自然的想法是,能不能找一组 n 个迭代方向,每次沿着一个方向只走一次达到该方向的最优解,那么最多走 n 次就能收敛到最优解了。这种方法究竟有没有呢?当然是有的(汗,要是没有我写这篇文章还有什么意义。。),就是共轭梯度法嘛。
共轭梯度法 (conjugate gradient)
共轭梯度法天性适合求解大规模稀疏线性方程组问题,而本文中的矩阵分解恰好可转化为这一类问题。首先来看什么是“共轭”,设 \(\boldsymbol{A}\) 为对称正定矩阵,对于两个非零向量 \(\boldsymbol{u}\) 和 \(\boldsymbol{v}\) ,若 \(\boldsymbol{u}^\top \boldsymbol{A} \boldsymbol{v} = 0\) ,则称 \(\boldsymbol{u}\) 和 \(\boldsymbol{v}\) 关于 \(\boldsymbol{A}\) 共轭。对于 \(n\) 维二次型函数 \(f(\boldsymbol{x}) = \frac12 \boldsymbol{x^\top A x} - \boldsymbol{x^\top b}\) ,\(\boldsymbol{x} \in \mathbb{R}^n\) ,最好的迭代方向为关于 \(\boldsymbol{A}\) 的共轭方向,每次迭代其中一个方向,那么最多 \(n\) 步之后就能到达最优点。
于是剩下的问题是如何得到一组关于 \(\boldsymbol{A}\) 的共轭方向? 所谓的共轭梯度法可理解为 “共轭方向 + 梯度 $\Longrightarrow $ 新共轭方向” ,这样就避免了需要预先给定一组共轭方向,而是每一轮迭代中根据上一轮共轭向量和梯度的线性组合来确定新方向,这样就节约了很多空间。
对于上述的二次型函数,其梯度为 \(\nabla f(\boldsymbol{x}) = \boldsymbol{Ax} - \boldsymbol{b}\) ,若令其为零则等价于求方程 \(\boldsymbol{Ax} = \boldsymbol{b}\) 的解。在上文 ALS 算法中是直接矩阵求逆得 \(\boldsymbol{x} = \boldsymbol{A}^{-1} \boldsymbol{b}\) ,而共轭梯度法作为一种迭代方法来说,设第 \(k\) 步的搜索方向为 \(\boldsymbol{p}_k\) ,则第 \(k + 1\) 步的解为 \(\boldsymbol{x}_{k+1} = \boldsymbol{x}_k + \alpha_k \boldsymbol{p}_k\) 。新的共轭方向为上一轮共轭方向和负梯度的线性组合,即 \(\boldsymbol{p}_{k+1} = - \nabla f( \boldsymbol{x} ) + \beta_k \boldsymbol{p}_k\) 。设残差 \(\boldsymbol{r} = \boldsymbol{b} - \boldsymbol{A x}\) ,则对于二次型函数 \(f(\boldsymbol{x})\) 来说,负梯度就是残差,则 \(\boldsymbol{p}_{k+1} = \boldsymbol{r}_k + \beta_k \boldsymbol{p}_k\) 。而对于新一轮的残差: \(\boldsymbol{r}_{k+1} = \boldsymbol{b} - \boldsymbol{A}\boldsymbol{x}_{k+1} = \boldsymbol{b} - \boldsymbol{A}(\boldsymbol{x}_k + \alpha_k \boldsymbol{p}_k) = \boldsymbol{r}_k - \alpha_k \boldsymbol{Ap}_k\) 。于是完整的共轭梯度法如下所示:

\(\boldsymbol{p}\) 即为每一轮的共轭搜索方向,其初始方向依据梯度下降法设定为梯度的负方向,即残差 \(\boldsymbol{p}_0 = \boldsymbol{r}_0\)。由 \(\boldsymbol{x} = \boldsymbol{A}^{-1} \boldsymbol{b}\) ,那么根据 \((1.6)\) 和 \((1.7)\) 式:
下面给出共轭梯度法的实现代码:
def conjugate_gradient(dataset, X, Y, reg, n_factors, alpha=10, cg_steps=3, user=True):
if user:
data = dataset.train_user
else:
data = dataset.train_item
YtY = Y.T.dot(Y) + reg * np.eye(n_factors)
for s in data:
x = X[s]
r = -YtY.dot(x)
for item, label in data[s].items():
confidence = 1 + alpha * label
r += (confidence - (confidence - 1) * Y[item].dot(x)) * Y[item] # b - Ax
p = r.copy()
rs_old = r.dot(r)
if rs_old < 1e-10:
continue
for it in range(cg_steps):
Ap = YtY.dot(p)
for item, label in data[s].items():
confidence = 1 + alpha * label
Ap += (confidence - 1) * Y[item].dot(p) * Y[item]
# standard CG update
alpha = rs_old / p.dot(Ap)
x += alpha * p
r -= alpha * Ap
rs_new = r.dot(r)
if rs_new < 1e-10:
break
p = r + (rs_new / rs_old) * p
rs_old = rs_new
X[s] = x
完整代码可见推荐系统库 LibRecommender 中的实现 。
从计算效率上来看,共轭梯度法介于梯度下降法和牛顿法之间,克服了梯度下降法收敛慢的问题,也避免了牛顿法需要计算 Hessian 矩阵的缺点。其计算复杂度为 \(\mathcal{O}(\mathcal{N}_u\, E)\) ,空间复杂度为 \(\mathcal{O}(\mathcal{N}_u)\), 其中\(E\) 为迭代次数,而 \(\mathcal{N}_u = \sum_un_u\) ,为所有用户行为总量, 通常每个用户只对少量的物品产生行为,因而可以看到共轭梯度法充分利用了数据的稀疏性,提高了计算效率。
上文提到共轭梯度法最多在 \(n\) 步内即可收敛,然而对于高维数据 (超过百万维的数据并不鲜见) 而言,这依然不能让人满意。不过可以证明,若正定矩阵 \(\boldsymbol{A}\) 有 \(i\) 个不同的特征值,那么共轭梯度法最多可在 \(i\) 步内收敛,这样又大大提高了优化效率。下面使用 MovieLens 1m 数据集进行测试,并与传统的 ALS 进行比较,\(f\) 统一设为 \(100\), 评估指标为 ROC 下 AUC,下图显示共轭梯度法在迭代 3 步后就已经接近收敛了 (注: 这里的 3 步指的是一个 epoch 内的迭代步数,而非 3 个 epoch):
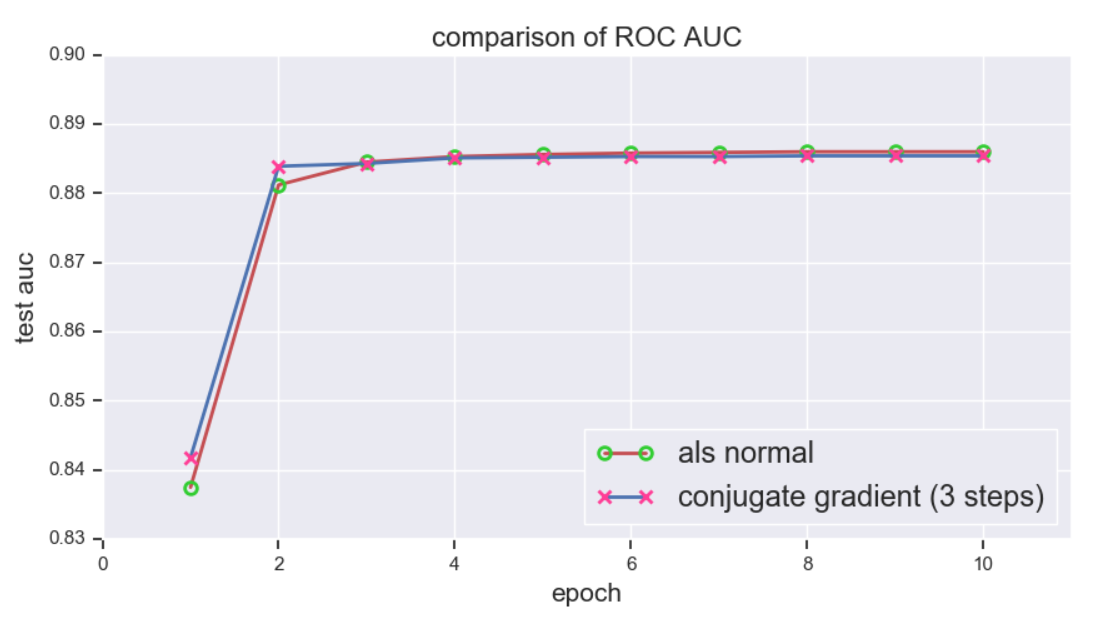
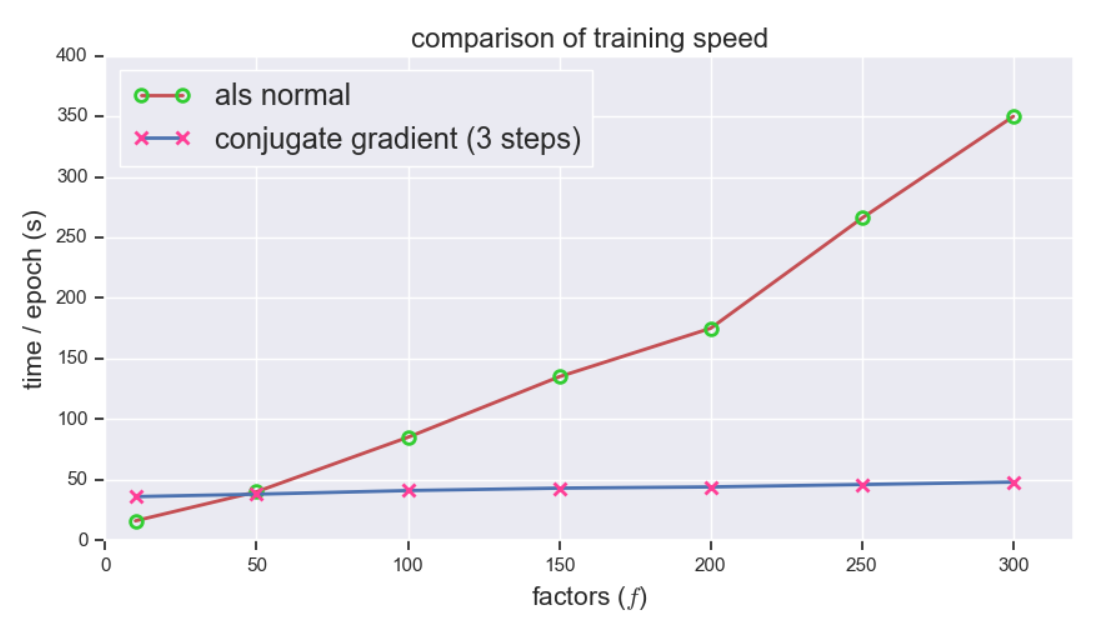
接下来对比训练速度,共轭梯度法展现出惊人的速度,随着 \(f\) 的增长训练时间几乎不变,而相比之下传统 ALS 的训练时间增长神速,可见 \(f\) 越大,提升越明显:
/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号