本篇本来是想写神经网络反向传播算法,但感觉光写这个不是很完整,所以就在前面将相关的求导内容一并补上。所谓的神经网络求导,核心是损失函数对线性输出 \(\mathbf{z} \;\; (\mathbf{z} = \mathbf{Wa} + \mathbf{b})\) 求导,即反向传播中的 \(\delta = \frac{\partial \mathcal{L}}{\partial \mathbf{z}}\) ,求出了该值以后后面的对参数求导就相对容易了。
\(\text{Jacobian}\) 矩阵
函数 \(\boldsymbol{f} : \mathbb{R}^n \rightarrow \mathbb{R}^m\) ,则 \(\text{Jacobian}\) 矩阵为:
\[\frac{\partial \boldsymbol{f}}{\partial \mathbf{x}} =
\begin {bmatrix}
\frac{\partial f_1}{\partial x_1} & \frac{\partial f_1}{\partial x_2} & \cdots & \frac{\partial f_1}{\partial x_n} \\
\frac{\partial f_2}{\partial x_1} & \frac{\partial f_2}{\partial x_2} & \cdots & \frac{\partial f_2}{\partial x_n} \\
\vdots & \vdots & \ddots \\
\frac{\partial f_m}{\partial x_1} &\frac{\partial f_m}{\partial x_2} & \cdots & \frac{\partial f_m}{\partial x_n}
\end {bmatrix}
\in \mathbb{R}^{m \times n}
\]
即 \((\frac{\partial \boldsymbol{f}}{\partial \mathbf{x}})_{ij} = \frac{\partial f_i}{\partial x_j}\)
神经网络中的激活函数多为对应元素运算 ( element-wise ) ,设输入为K维向量 \(\mathbf{x} = [x_1, x_2, ..., x_K ]^\text{T}\) , 输出为K维向量 \(\mathbf{z} = [z_1, z_2, ..., z_K]^\text{T}\) ,则激活函数为 \(\mathbf{z} = f(\mathbf{x})\) ,即 \(z_i = [f(\mathbf{x})]_i = f(x_i)\) ,则其导数按 \(\text{Jacobian}\) 矩阵的定义为一个对角矩阵:
\[\begin{align*}
\frac{\partial f(\mathbf{x})}{\partial \mathbf{x}} =
\begin {bmatrix}
\frac{\partial f(x_1)}{\partial x_1} & \frac{\partial f(x_1)}{\partial x_2} & \cdots & \frac{\partial f(x_1)}{\partial x_k} \\
\frac{\partial f(x_2)}{\partial x_1} & \frac{\partial f(x_2)}{\partial x_2} & \cdots & \frac{\partial f(x_2)}{\partial x_k} \\
\vdots & \vdots & \ddots \\
\frac{\partial f(x_k)}{\partial x_1} &\frac{\partial f(x_k)}{\partial x_2} & \cdots & \frac{\partial f(x_k)}{\partial x_k}
\end {bmatrix}
& = \begin {bmatrix}
f'(x_1) & 0 &\cdots & 0 \\
0 & f'(x_2) & \cdots & 0 \\
\vdots & \vdots & \ddots \\
0 & 0 & \cdots & f'(x_k)
\end {bmatrix} \\[2ex]
& = \text{diag}(f'(\mathbf{x})) \in \mathbb{R}^{k \times k}
\end{align*}
\]
\(\text{Sigmoid}\) 激活函数
\(\text{Sigmoid}\) 函数的形式为:
\[\sigma(z) = \frac{1}{1+e^{\,-z}} \;\;\in (0,1)
\]
其导数为:
\[\sigma'(z) = -\frac{(1+e^{-z})'}{(1 + e^{-z})^2} = -\frac{-e^{-z}}{(1+ e^{-z})^2} = \frac{e^{-z}}{1 + e^{-z}} \cdot \frac{1}{1 + e^{-z}} = \sigma(z) (1 - \sigma(z))
\]
若输入为 K 维向量 \(\mathbf{z} = [z_1, z_2, ..., z_K]^\text{T}\) ,根据上文的定义,其导数为
\[\begin{align*}
\sigma'(\mathbf{z}) &=
\begin {bmatrix}
\sigma(z_1) (1 - \sigma(z_1)) &0& \cdots & 0 \\
0 & \sigma(z_2) (1 - \sigma(z_2)) & \cdots & 0 \\
\vdots & \vdots & \ddots \\
0 & 0 & \cdots & \sigma(z_k) (1 - \sigma(z_k))
\end {bmatrix} \\[3ex]
& = \text{diag} \left(\sigma(\mathbf{z}) \odot (1-\sigma(\mathbf{z}))\right)
\end{align*}
\]
\(\text{Tanh}\) 激活函数
\(\text{Tanh}\) 函数可以看作是放大并平移的 \(\text{Sigmoid}\) 函数,但因为是零中心化的 (zero-centered) ,通常收敛速度快于 \(\text{Sigmoid}\) 函数,下图是二者的对比:
\[\text{tanh}(z) = \frac{e^{z} - e^{-z}}{e^z + e^{-z}} = \frac{2}{1 + e^{-2z}} - 1 = 2\sigma(2z) - 1 \;\; \in(-1,1)
\]
![]()
其导数为:
\[\text{tanh}'(z) = \frac{(e^z + e^{-z})^2 - (e^z - e^{-z})^2}{(e^z + e^{-z})^2} = 1 - \text{tanh}^2(z)
\]
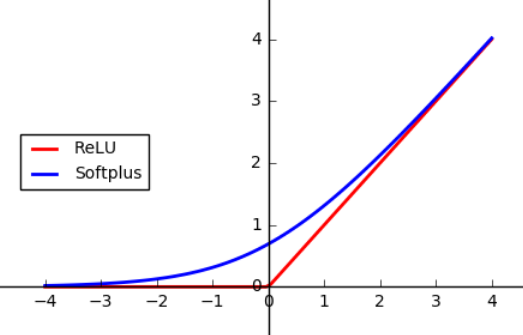
\(\text{Softplus}\) 激活函数
\(\text{Softplus}\) 函数可以看作是 \(\frak{ReLU}\) 函数的平滑版本,形式为:
\[\text{softplus}(z) = \text{log}(1+ e^z)
\]
![]()
而其导数则恰好就是 \(\text{Sigmoid}\) 函数:
\[\text{softplus}'(z) = \frac{e^z}{1 + e^z} = \frac{1}{1+ e^{-z}}
\]
另外:
\[\text{softplus}(z) - \text{softplus}(-z) = \text{log}\frac{1 + e^z}{1 + e^{-z}} = \text{log}\frac{e^z (e^{-z} + 1)}{e^{-z} + 1} = z
\]
\(\text{Softmax}\) 激活函数
\(\text{softmax}\) 函数将多个标量映射为一个概率分布,其形式为:
\[y_i = \text{softmax}(z_i) = \frac{e^{z_i}}{\sum_{k=1}^C e^{z_k}}
\]
\(y_i\) 表示第 \(i\) 个输出值,也可表示属于类别 \(i\) 的概率, \(\sum\limits_{i=1}^C y_i = 1\)。
首先求标量形式的导数,即第 \(i\) 个输出对于第 \(j\) 个输入的偏导:
\[\frac{\partial y_i}{\partial z_j} = \frac{\partial\, \frac{e^{z_i}}{\sum_{k=1}^{C} e^{a_k}}}{\partial z_j}
\]
其中 \(e^{z_i}\) 对 \(z_j\) 求导要分情况讨论,即:
\[\frac{\partial e^{z_i}}{\partial z_j} =
\begin{cases}
e^{z_i}, & \text{if} \;\;\; i = j \\[1ex]
0, & \text{if} \;\;\; i \neq j
\end{cases}
\]
那么当 \(i =j\) 时:
\[\frac{\partial y_i}{\partial z_j} = \frac{e^{z_i} \sum_{k=1}^Ce^{z_k} - e^{z_i}e^{z_j}}{\left(\sum_{k=1}^C e^{z_k}\right)^2} = \frac{e^{z_i}}{\sum_{k=1}^C e^{z_k}} - \frac{e^{z_i}}{\sum_{k=1}^C e^{z_k}} \frac{e^{z_j}}{\sum_{k=1}^C e^{z_k}} =y_i - y_i y_j \tag{1.1}
\]
当 \(i \neq j\) 时:
\[\frac{\partial y_i}{\partial z_j} = \frac{0 - e^{z_i}e^{z_j}}{\left(\sum_{k=1}^C e^{z_k}\right)^2} = -y_iy_j \tag{1.2}
\]
于是二者综合:
\[\frac{\partial y_i}{\partial z_j} = \mathbf{\large1} \{i=j\}\, y_i - y_i\,y_j \tag{1.3}
\]
其中 \(\mathbf{\large 1} \{i=j\} = \begin{cases}1, & \text{if} \;\;\; i = j \\0, & \text{if} \;\;\; i \neq j\end{cases}\)
当 \(\text{softmax}\) 函数的输入为K 维向量 \(\mathbf{z} = [z_1, z_2, ..., z_K]^\text{T}\) 时,转换形式为 \(\mathbb{R}^K \rightarrow \mathbb{R}^K\) :
\[\mathbf{y} = \text{softmax}(\mathbf{z}) = \frac{1}{\sum_{k=1}^K e^{z_k}}
\begin{bmatrix}
e^{z_1} \\
e^{z_2} \\
\vdots \\
e^{z_K}
\end{bmatrix}
\]
其导数同样为 \(\text{Jabocian}\) 矩阵 ( 同时利用 \((1.1)\) 和 \((1.2)\) 式 ):
\[\begin{align*}
\frac{\partial\, \mathbf{y}}{\partial\, \mathbf{z}} & =
\begin {bmatrix}
\frac{\partial y_1}{\partial z_1} & \frac{\partial y_1}{\partial z_2} & \cdots & \frac{\partial y_1}{\partial z_K} \\
\frac{\partial y_2}{\partial z_1} & \frac{\partial y_2}{\partial z_2} & \cdots & \frac{\partial y_2}{\partial z_K} \\
\vdots & \vdots & \ddots \\
\frac{\partial y_K}{\partial z_1} &\frac{\partial y_K}{\partial z_2} & \cdots & \frac{\partial y_K}{\partial z_K}
\end {bmatrix} \\[2ex]
& =
\begin {bmatrix}
\small{y_1 - y_1 y_1} & \small{-y_1y_2} & \cdots & \small{-y_1 y_K} \\
\small{-y_2y_1} & \small{y_2 - y_2 y_1} & \cdots & \small{-y_2 y_K} \\
\vdots & \vdots & \ddots \\
\small{-y_Ky_1} & \small{-y_K y_2} & \cdots & \small{y_K - y_K y_K}
\end {bmatrix} \\[2.5ex]
& =
\text{diag}(\mathbf{y}) - \mathbf{y}\mathbf{y}^\text{T} \\[0.5ex]
&=
\text{diag}(\text{softmax}(\mathbf{z})) - \text{softmax}(\mathbf{z})\, \text{softmax}(\mathbf{z})^\text{T}
\end{align*}
\]
交叉熵损失函数
交叉熵损失有两种表示形式,设真实标签为 \(y\) ,预测值为 \(a\) :
(一) \(y\) 为标量,即 \(y \in \mathbb{R}\) ,则交叉熵损失为:
\[\mathcal{L}(y, a) = - \sum\limits_{j=1}^{k} \mathbf{\large 1}\{y = j\}\, \text{log}\, a_j
\]
(二) \(y\) 为one-hot向量,即 \(y = \left[0,0...1...0\right]^\text{T} \in \mathbb{R}^k\) ,则交叉熵损失为:
\[\mathcal{L}(y, a) = -\sum\limits_{j=1}^k y_j\, \text{log}\, a_j
\]
交叉熵损失函数 + Sigmoid激活函数
已知 \(\mathcal{L}(y, a) = -\sum\limits_{j=1}^k y_j\, \text{log}\, a_j\), \(a_j = \sigma(z_j) = \frac{1}{1+e^{\,-z_j}}\) ,求 \(\frac{\partial \mathcal{L}}{z_j}\) :
\[\frac{\partial \mathcal{L}}{\partial z_j} = \frac{\partial \mathcal{L}}{\partial a_j} \frac{\partial a_j}{\partial z_j} = -y_j \frac{1}{\sigma(z_j)} \sigma(z_j) (1 - \sigma(z_j)) = \sigma(z_j) - 1 = a_j - y_j
\]
交叉熵损失函数 + Softmax激活函数
已知 \(\mathcal{L}(y, a) = -\sum\limits_{i=1}^k y_i\, \text{log}\, a_i\), \(a_j = \text{softmax}(z_j) = \frac{e^{z_j}}{\sum_{c=1}^C e^{z_c}}\) ,求 \(\frac{\partial \mathcal{L}}{\partial z_j}\) :
\[\begin{align*}
\frac{\partial \mathcal{L}}{\partial z_j} = \sum\limits_{i=1}^k\frac{\partial \mathcal{L}}{\partial a_i} \frac{\partial a_i}{\partial z_j} & = \sum\limits_{i=j} \frac{\partial \mathcal{L}}{\partial a_j} \frac{\partial a_j}{\partial z_j} + \sum\limits_{i \neq j} \frac{\partial \mathcal{L}}{\partial a_i} \frac{\partial a_i}{\partial z_j} \\
& = -\frac{y_j}{a_j} \frac{\partial a_j}{\partial z_j} - \sum\limits_{i \neq j} \frac{y_i}{a_i}\frac{a_i}{z_j} \\
& = -\frac{y_j}{a_j} a_j(1 - a_j) + \sum\limits_{i \neq j} \frac{y_i}{a_i} a_i a_j \qquad\qquad \text{运用 (1.1)和(1.2) 式} \\
& = -y_j + y_ja_j + \sum\limits_{i \neq j} y_i a_j \\
& = a_j - y_j
\end{align*}
\]
若输入为 \(K\) 维向量 \(\mathbf{z} = [z_1, z_2, ..., z_k]^\text{T}\) ,则梯度为:
\[\frac{\partial \mathcal{L}}{\partial \mathbf{z}} = \mathbf{a} - \mathbf{y} =
\begin{bmatrix}
a_1 - 0 \\
\vdots \\
a_j - 1 \\
\vdots \\
a_k - 0
\end{bmatrix}
\]
另外运用对数除法运算,上面的求导过程可以简化:
\[\mathcal{L}(y, a) = -\sum\limits_{i=1}^k y_i\, \text{log}\, a_i = -\sum\limits_{i=1}^k y_i\, \text{log}\, \frac{e^{z_i}}{\sum_c e^{z_c}} = -\sum\limits_{i=1}^k y_i z_i + y_i \text{log} \sum_c e^{z_c}
\]
\[\frac{\partial {\mathcal{L}}}{\partial z_i} = -y_i + \frac{e^{z_i}}{\sum_c e^{z_c}} = a_i - y_i
\]
神经网络反向传播算法
通常所谓的“学习”指的是通过最小化损失函数进而求得相应参数的过程,神经网络中一般采用梯度下降来实现这个过程,即:
\[\theta = \theta - \alpha \cdot \frac{\partial}{\partial \theta}\mathcal{L}(\theta)
\]
用神经网络中的常用参数符号替换,并用矩阵形式表示:
\[\begin{align*}
\mathbf{W}^{(l)} &= \mathbf{W}^{(l)} - \alpha \frac{\partial \mathcal{L}}{\partial\, \mathbf{W}^{(l)}} \\[2ex]
\mathbf{b}^{(l)} &=\,\, \mathbf{b}^{(l)} - \alpha \frac{\partial \mathcal{L}}{\partial\, \mathbf{b}^{(l)}}
\end{align*}
\]
其中 \((l)\) 表示第 \(l\) 层。
导数是梯度的组成部分,通常采用数值微分的方法近似下式:
\[f'(x) = \lim\limits_{h \rightarrow 0}\frac{f(x + h) - f(x)}{h}
\]
\(f'(x)\) 表示函数 \(f(x)\) 在 \(x\) 处的斜率,但是由于运算时 \(h\) 不可能无限接近于零,上式容易引起数值计算问题,所以实际中常采用中心差分来近似:
\[f'(x) = \lim\limits_{h \rightarrow 0} \frac{f(x + h) - f(x - h)}{2h}
\]
这样整个梯度的计算可以用以下代码实现:
import numpy as np
def numerical_gradient(f, x): # f为函数,x为输入向量
h = 1e-4
grad = np.zeros_like(x)
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
idx = it.multi_index
temp = x[idx]
x[idx] = temp + h
fxh1 = f(x)
x[idx] = temp - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = temp
it.iternext()
return grad
由于数值微分对每个参数都要计算 \(f(x+h)\) 和 \(f(x-h)\) ,假设神经网络中有100万个参数,则需要计算200万次损失函数。如果是使用 SGD,则是每个样本计算200万次,显然是不可承受的。所以才需要反向传播算法这样能够高效计算梯度的方法。
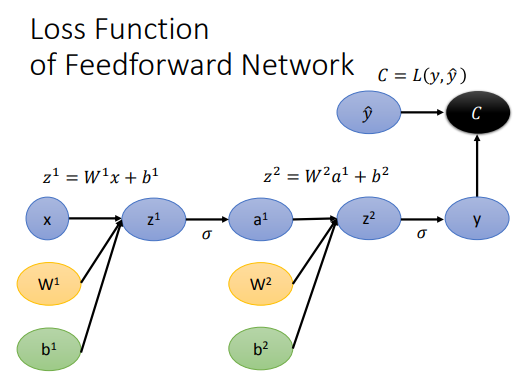
接下来先定义神经网络中前向传播的式子 (\(l\) 表示隐藏层, \(L\) 表示输出层):
![]()
\[\begin{align*}
&\mathbf{z}^{(l)} = \mathbf{W}^{(l)} \mathbf{a}^{(l-1)} + \mathbf{b}^{(l)} \tag{2.1} \\[0.5ex]
&\mathbf{a}^{(l)} = f(\mathbf{z}^{(l)}) \tag{2.2} \\[0.5ex]
&\mathbf{\hat{y}} = \mathbf{a}^{(L)} = f(\mathbf{z}^{(L)}) \tag{2.3} \\[0.5ex]
&\mathcal{L} = \mathcal{L}(\mathbf{y}, \mathbf{\hat{y}}) \tag{2.4}
\end{align*}
\]
现在我们的终极目标是得到 $\frac{\partial {\mathcal{L}}}{\partial \mathbf{W}^{(l)}}$ 和 $\frac{\partial \mathcal{L}}{\partial \mathbf{b}^{(l)}}$ ,为了计算方便,先来看各自的分量 $\frac{\partial {\mathcal{L}}}{\partial {W}_{jk}^{(l)}}$ 和 $\frac{\partial \mathcal{L}}{\partial b_j^{(l)}}$ 。
这里定义 $\delta_j^{(l)} = \frac{\partial \mathcal{L}}{\partial z_j^{(l)}}$ , 根据 $(2.1)$ 式使用链式法则:
$$
\begin{align*}
& \frac{\partial {\mathcal{L}}}{\partial {W}_{jk}^{(l)}} = \frac{\partial \mathcal{L}}{\partial z_j^{(l)}} \frac{\partial z_j^{(l)}}{\partial W_{jk}^{(l)}} = \delta_j^{(l)} \frac{\partial}{\partial W_{jk}^{(l)}} \left(\sum_i W_{ji}^{(l)}a_i^{(l-1)}\right) = \delta_j^{(l)} a_k^{(l-1)} \tag{2.5} \\[1ex]
& \frac{\partial {\mathcal{L}}}{\partial {b}_{j}^{(l)}} = \frac{\partial \mathcal{L}}{\partial z_j^{(l)}} \frac{\partial z_j^{(l)}}{\partial b_{j}^{(l)}} =\delta_j^{(l)} \tag{2.6}
\end{align*}
$$
所以接下来的问题就是求 \(\delta_j^{(l)}\) :
(1) 对于输出层 \(L\) :
\[\delta_j^{L} = \frac{\partial \mathcal{L}}{\partial z_j^{(L)}} = \frac{\partial \mathcal{L}}{\partial a_j^{(L)}} \frac{\partial a_j^{(L)}}{\partial z_j^{(L)}} = \frac{\partial \mathcal{L}}{\partial a_j^{(L)}} f'(z_j^{(L)}) \tag{2.7}
\]
(2) 对于隐藏层 \(l\) ,由 \((2.1)\) 式可知:
\[\begin{cases}
z_1^{(l+1)} &= \sum_j W_{1j}^{(l+1)} a_j^{(l)} + b_1^{(l+1)} \\
z_2^{(l+1)} &= \sum_j W_{2j}^{(l+1)} a_j^{(l)} + b_2^{(l+1)} \\[0.3ex]
& \vdots \\[0.3ex]
z_k^{(l+1)} &= \sum_j W_{kj}^{(l+1)} a_j^{(l)} + b_k^{(l+1)}
\end{cases}
\]
可见 \(a_j^{(l)}\) 对于 \(\mathbf{z}^{(l+1)}\) 的每个分量都有影响,使用链式法则时需要加和每个分量,下图是一个形象表示:
![]()
所以下面求 \(\delta_j^{(l)}\) 时会用 \(k\) 加和:
\[\begin{align*}
\delta_j^{(l)} = \frac{\partial \mathcal{L}}{\partial z_j^{(l)}} &= \left(\sum_k \frac{\partial \mathcal{L}}{\partial z_k^{(l+1)}}\frac{\partial z_k^{(l+1)}}{\partial a_j^{(l)}} \right) \frac{\partial a_j^{(l)}}{\partial z_j^{(l)}} \\[2ex]
&= \left(\sum_k \frac{\partial \mathcal{L}}{\partial z_k^{(l+1)}}\frac{\partial \left(\sum\limits_j W_{kj}^{(l+1)}a_j^{(l)} + b_k^{(l+1)}\right)}{\partial a_j^{(l)}} \right) \frac{\partial a_j^{(l)}}{\partial z_j^{(l)}} \\[1ex]
&= \left(\sum\limits_k \delta_k^{(l+1)} W_{kj}^{(l+1)}\right) f'(z_j^{(l)}) \tag{2.8}
\end{align*}
\]
将上面的 \((2.5) \sim (2.8)\) 式写成矩阵形式,就得到了传说中反向传播算法的四大公式:
\[\begin{align*}
& \boldsymbol{\delta} ^{(L)} = \frac{\partial \mathcal{L}}{\partial \,\mathbf{z}^{(L)}}= \nabla_{\mathbf{a}^{(L)}} \mathcal{L} \,\odot f'(\mathbf{z}^{(L)}) \\
& \boldsymbol{\delta}^{(l)} = \frac{\partial \mathcal{L}}{\partial \,\mathbf{z}^{(l)}} = ((\mathbf{W}^{(l+1)})^{\text{T}} \boldsymbol{\delta}^{(l+1)}) \odot f'(\mathbf{z}^{(l)}) \\[1ex]
& \frac{\partial \mathcal{L}}{\partial \mathbf{W}^{(l)}} = \boldsymbol{\delta}^{(l)} (\mathbf{a}^{(l-1)})^\text{T} =
\begin {bmatrix}
\delta_1^{(l)} a_1^{(l-1)} & \delta_1^{(l)} a_2^{(l-1)} & \cdots & \delta_1^{(l)} a_k^{(l-1)} \\
\delta_2^{(l)} a_1^{(l-1)} & \delta_2^{(l)} a_2^{(l-1)} & \cdots & \delta_2^{(l)} a_k^{(l-1)} \\
\vdots & \vdots & \ddots \\
\delta_j^{(l)} a_1^{(l-1)} &\delta_j^{(l)} a_2^{(l-1)} & \cdots & \delta_j^{(l)} a_k^{(l-1)}
\end {bmatrix}\\
& \frac{\partial \mathcal{L}}{\partial \mathbf{b}^{(l)}} = \boldsymbol{\delta}^{(l)}
\end{align*}
\]
而 \(\boldsymbol{\delta}^{(l)}\) 的计算可以直接套用上面损失函数 + 激活函数的计算结果。
反向传播算法 + 梯度下降算法流程
(1) 前向传播阶段:使用下列式子计算每一层的 \(\mathbf{z}^{(l)}\) 和 \(\mathbf{a}^{(l)}\) ,直到最后一层。
\[\begin{align*}
&\mathbf{z}^{(l)} = \mathbf{W}^{(l)} \mathbf{a}^{(l-1)} + \mathbf{b}^{(l)} \\[0.5ex]
&\mathbf{a}^{(l)} = f(\mathbf{z}^{(l)}) \\[0.5ex]
&\mathbf{\hat{y}} = \mathbf{a}^{(L)} = f(\mathbf{z}^{(L)}) \\[0.5ex]
&\mathcal{L} = \mathcal{L}(\mathbf{y}, \mathbf{\hat{y}})
\end{align*}
\]
(2) 反向传播阶段:
(2.1) 计算输出层的误差: $ \boldsymbol{\delta} ^{(L)} = \nabla_{\mathbf{a}^{(L)}} \mathcal{L} ,\odot f'(\mathbf{z}^{(L)})$
(2.2) 由后一层反向传播计算前一层的误差: \(\boldsymbol{\delta}^{(l)} = ((\mathbf{W}^{(l+1)})^{\text{T}} \boldsymbol{\delta}^{(l+1)}) \odot f'(\mathbf{z}^{(l)})\)
(2.3) 计算梯度: \(\frac{\partial \mathcal{L}}{\partial \mathbf{W}^{(l)}} = \boldsymbol{\delta}^{(l)} (\mathbf{a}^{(l-1)})^\text{T}\) , \(\frac{\partial \mathcal{L}}{\partial \mathbf{b}^{(l)}} = \boldsymbol{\delta}^{(l)}\)
(3) 参数更新:
\[\begin{align*}
\mathbf{W}^{(l)} &= \mathbf{W}^{(l)} - \alpha \frac{\partial \mathcal{L}}{\partial\, \mathbf{W}^{(l)}} \\[2ex]
\mathbf{b}^{(l)} &=\,\, \mathbf{b}^{(l)} - \alpha \frac{\partial \mathcal{L}}{\partial\, \mathbf{b}^{(l)}}
\end{align*}
\]
Reference
- 神经网络反向传播算法
- How the backpropagation algorithm works
- The Softmax function and its derivative
- Notes on Backpropagation
- Computational Graph & Backpropagation
/



 浙公网安备 33010602011771号
浙公网安备 33010602011771号