词频统计及其效能分析
学号;2017****7083
姓名:马双双
码云:https://gitee.com/yi545454/word_frequency/tree/SE7083
1.程序分析,对程序中的四个函数做简要说明。要求附上每一段代码及对应的说明。
⑴首先定义def process_file函数,将文件读到缓冲区并关闭,用open()打开文件、read()读取文件、close()关闭文件
def process_file(dst): # 读文件到缓冲区
try: # 打开文件
f1 = open(dst, "r")
except IOError as s:
print (s)
return None
try: # 读文件到缓冲区
bvffer = f1.read()
except:
print ("Read File Error!")
return None
f1.close()
return bvffer
⑵处理缓冲区,统计每个单词的频率,对文本的特殊符号进行修改
def process_buffer(bvffer):
if bvffer:
word_freq = {}
# 下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq
bvffer=bvffer.lower()
for x in '~!@#$%^&*()_+/*-+\][':
bvffer=bvffer.replace(x, " ")
words=bvffer.strip().split()
for word in words:
word_freq[word]=word_freq.get(word,0)+1
return word_freq
⑶遍历切割完的字符串,并输出统计频率Top 10 的单词
def output_result(word_freq):
if word_freq:
sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True)
for item in sorted_word_freq[:10]: # 输出 Top 10 的单词
print(item)
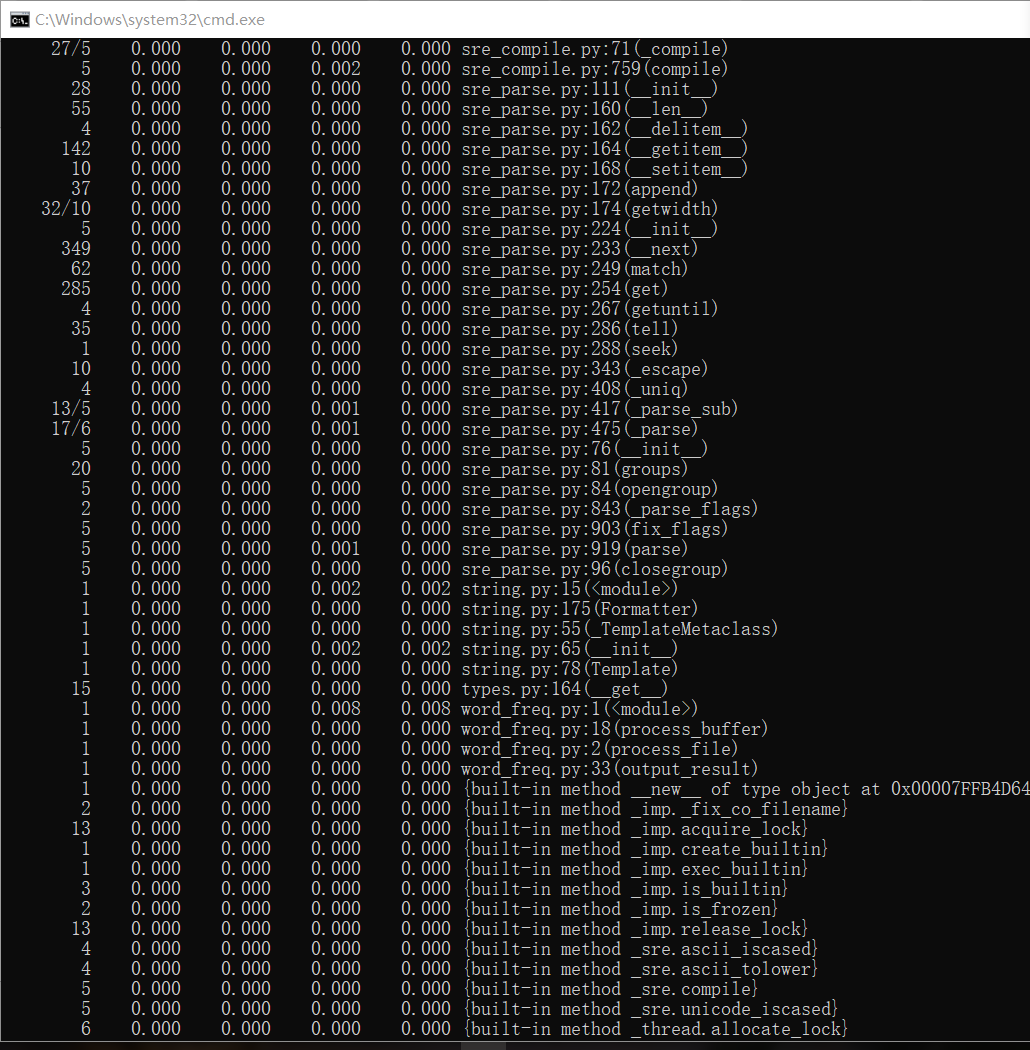
2.性能分析结果及改进。
指出执行次数最多的代码,执行时间最长的代码。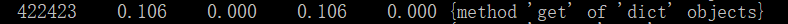
3.程序运行命令、运行结果截图以及改进后的程序运行命令及结果截图 。
此行代码为统计Top10单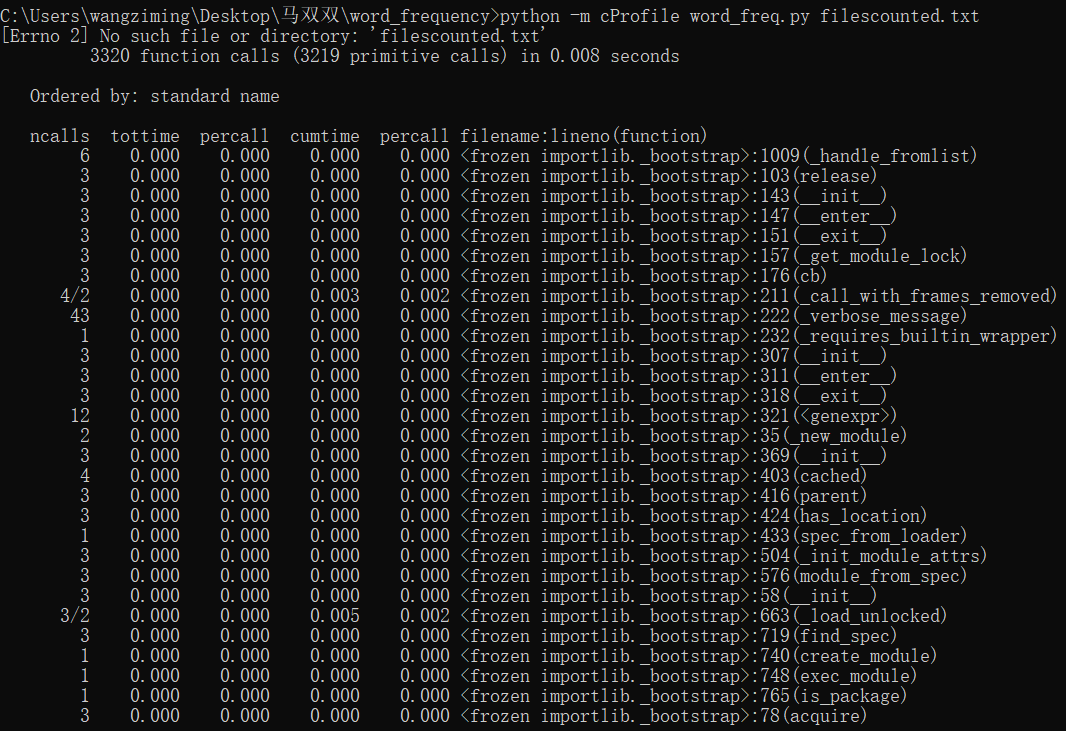
4.给出你对此次任务的总结与反思
通过本次作业复习了一下python的正则表达式和process_file函数,在同学帮助下完成了此次作业,以后有什么问题多请教,会学到很多东西,在百度上解决很多问题。
