
Coursera, Deep Learning 5, Sequence Models, week3, Sequence models & Attention mechanism
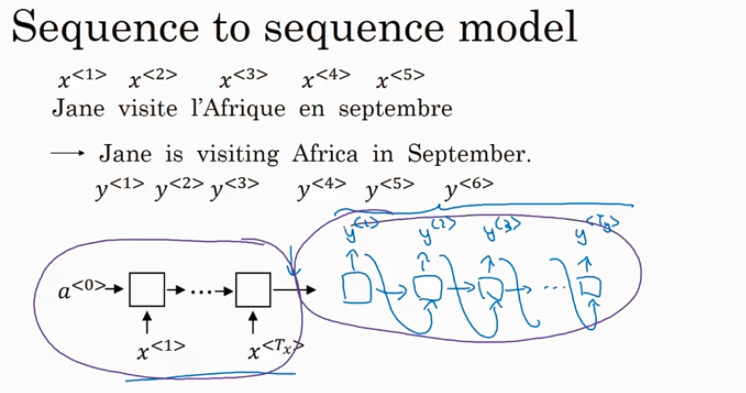
Sequence to Sequence models
basic sequence-to-sequence model:
basic image-to-sequence or called image captioning model:
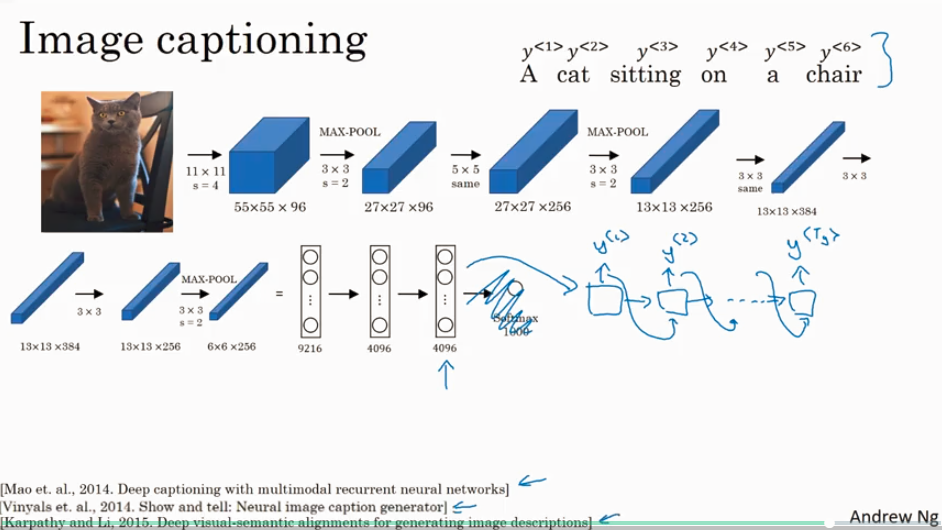
but there are some differences between how you write a model like this to generate a sequence, compared to how you were synthesizing novel text using a language model. One of the key differences is,you don't want a randomly chosen translation,you maybe want the most likely translation,or you don't want a randomly chosen caption, maybe not,but you might want the best caption and most likely caption.So let's see in the next video how you go about generating that.
Picking the most likely sentence
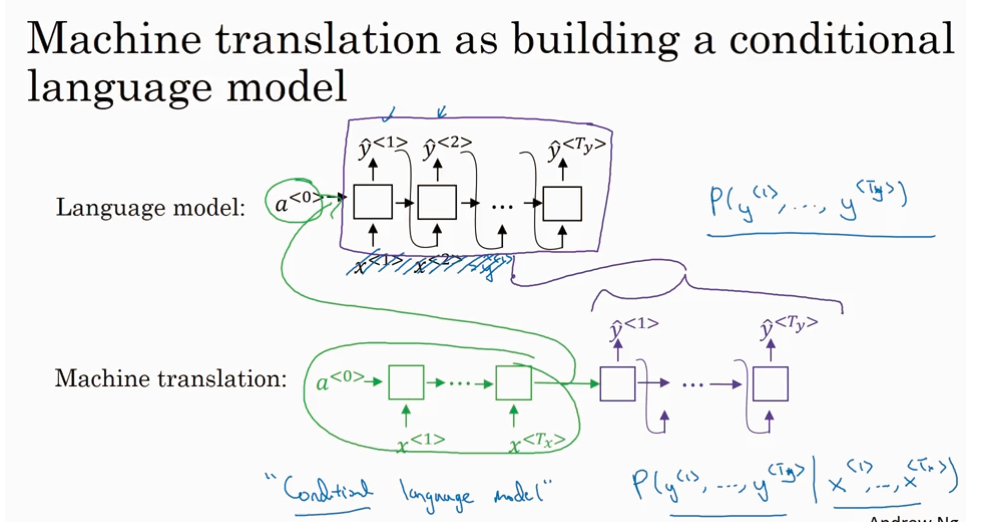
找出最大可能性的P(y|x),最常用的算法是beam search.

在介绍 beam search 之前,先了解一下 greedy search 已经为什么不用 greedy search?
greedy search 的意思是,在已知一个值word的情况下,求下一个值word的最可能的情况,以此类推。。。 下图是一个很好的例子说明 greedy search 不适用的情况, 就不如求核能的 y^ 的组合的概率 p(y^1, y^2, ...|x) 然后找出最大概率,当然这样也有问题,就是比如说 10 个word 的输出,在一个 10,000 大的corpus 里就有 10,000 10 种组合情况,需要诉诸于更好的算法,且继续往下看

