
Coursera, Deep Learning 4, Convolutional Neural Networks - week2
2021.11 update: to add the MobileNet and EfficientNet as Coursera updated to add these
Case Study

(Note: 红色表示不重要)
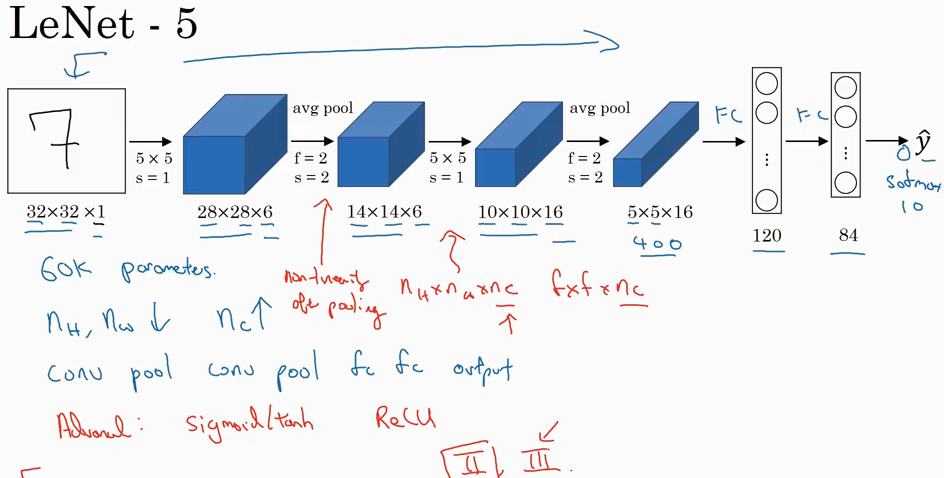
LeNet-5 起初用来识别手写数字灰度图片
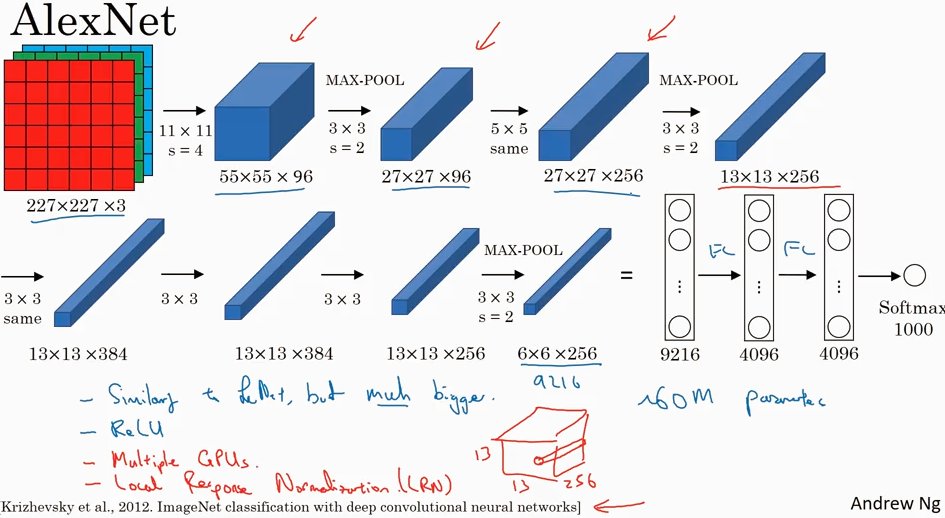
AlexNet 输入的是227x227x3 的图片,输出1000 种类的结果
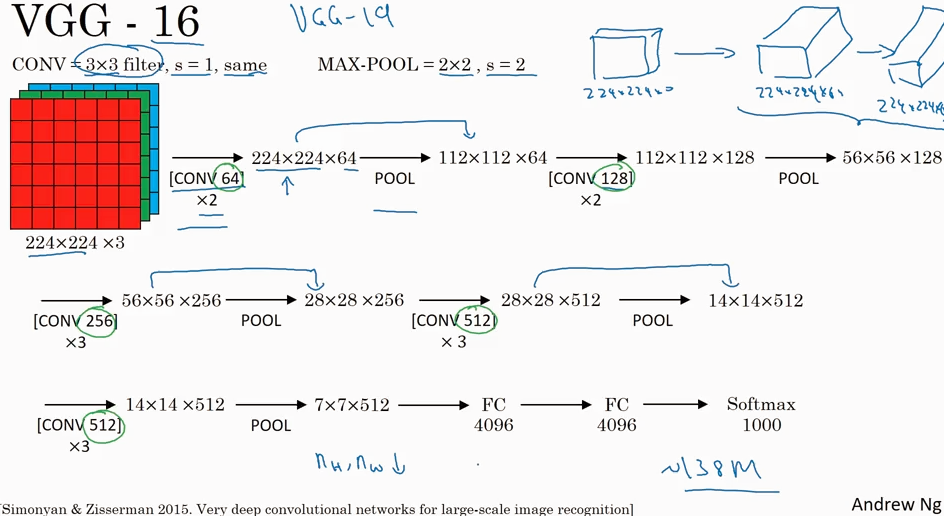
VGG
VGG比AlexNet 结构更简单,filter 都是3x3的,max-pool 都是 2x2的.
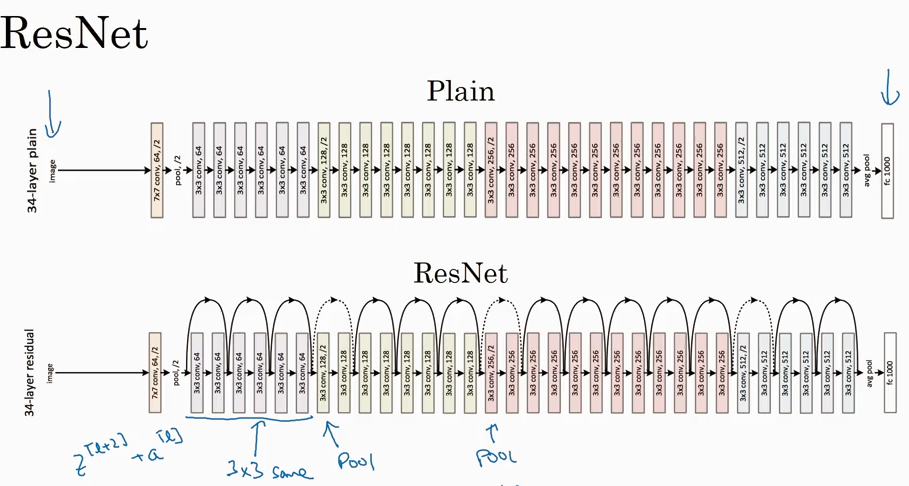
ResNets (Residual Network)
可用让很深的network 工作的很好. This really helps with the vanishing and exploding gradient problems.
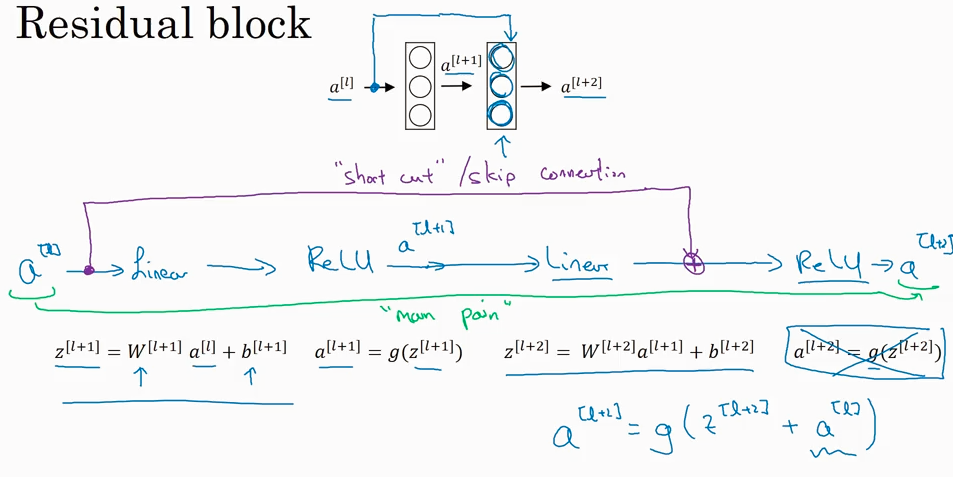
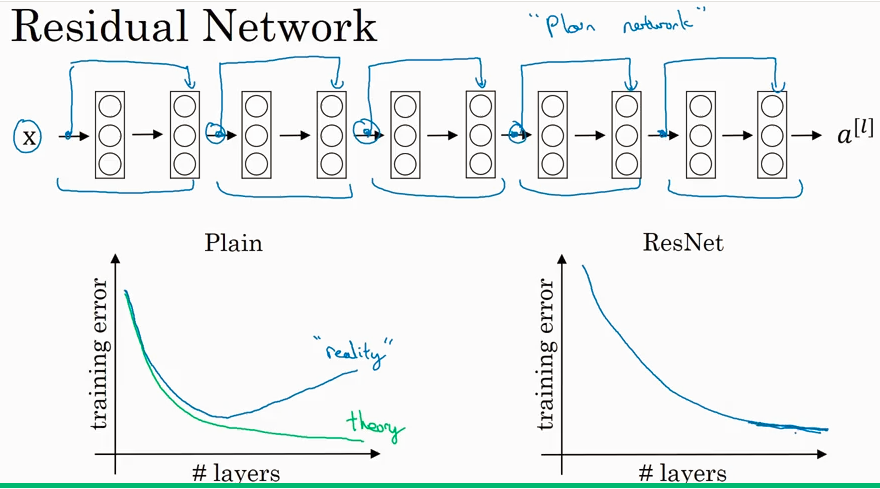
为什么ResNet 会起作用呢?下图中所示如果vanishings时候 W[l+2] =0, 设b也=0. a[l+2] = a[l], 说明很容易保留

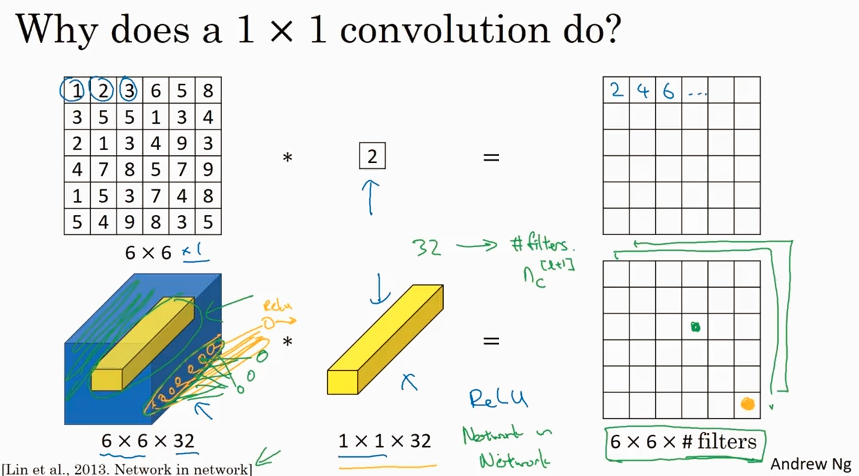
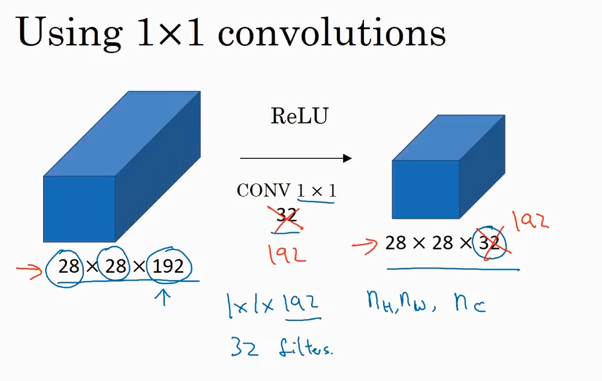
Networks in Networks and 1x1 Convolutions
1x1 convolutions 可以用来减少 channel数据,或者保持一样,甚至可以增大channel.
Inception network
就像大烩菜,把1x1, 3x3, 5x5, pooling 都揉到一起,就成了inception network.

上图中有个问题是 computational cost 很高.
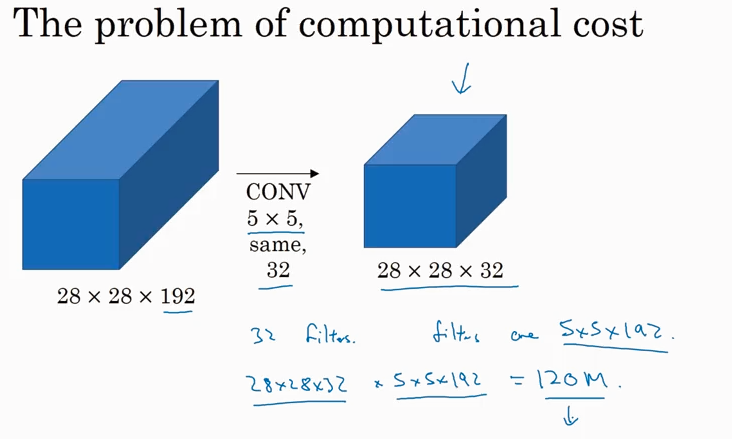
这个问题可以用下面的方便解决。这个方法被证明不影响性能.

下面是一个inception module
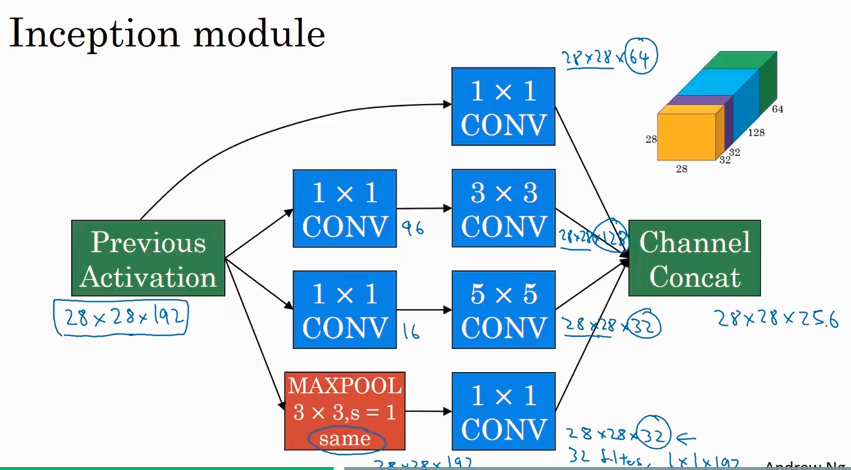
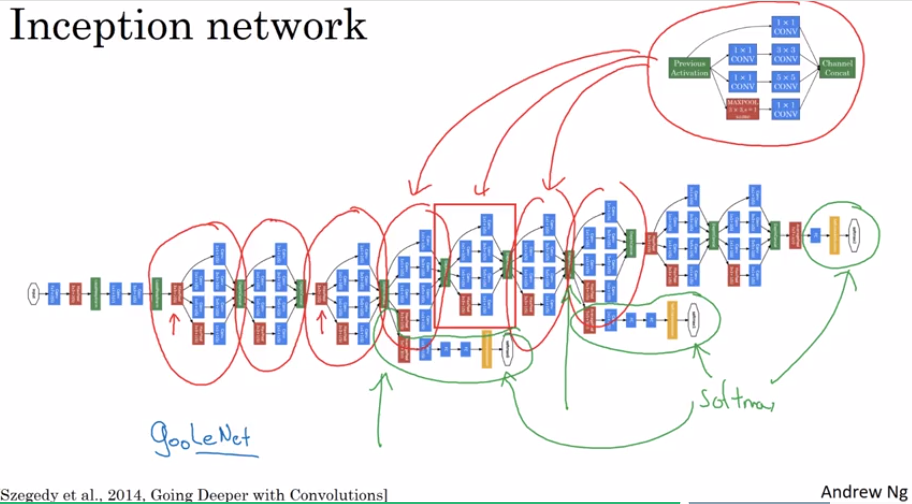
一个incetption network 是有很多的inception module 组成的network. Inception 来自盗梦空间,和很深的网络有关联意思. 在整个网络中间部分分出来的branch 也是用来做predict的,在中间做预测一般是为了防止overfitting.
这个inception network 来自google的开发者,所以也叫 GoogLeNet, 后面的LeNet 是向 LeNet 的作者 Yann LeCun 致敬
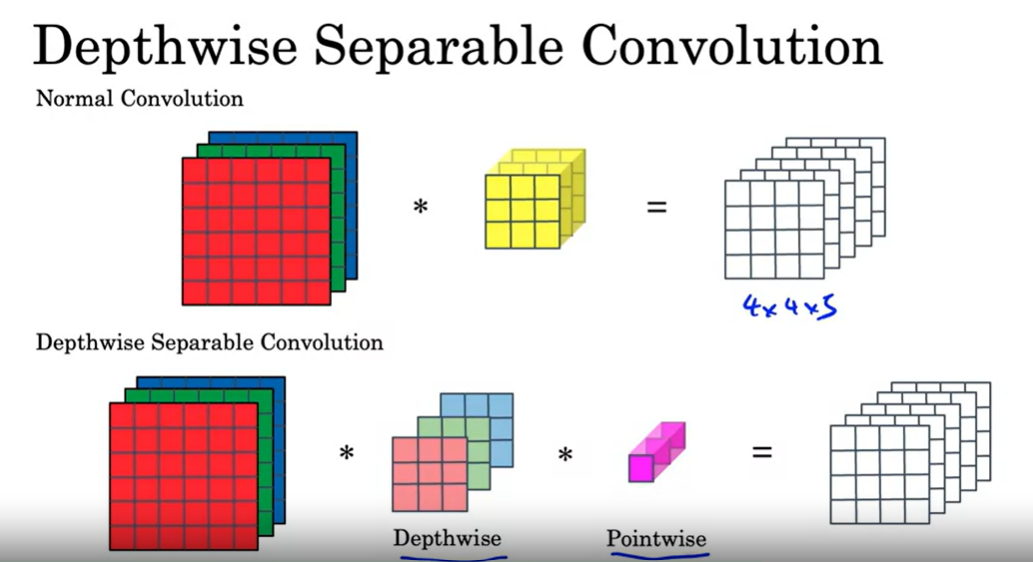
MobileNet
引入了 Depthwise-separable convolution 概念

Normal 和 depthwise-separable convolution 的对比,后者计算量省了很多。
EfficientNet
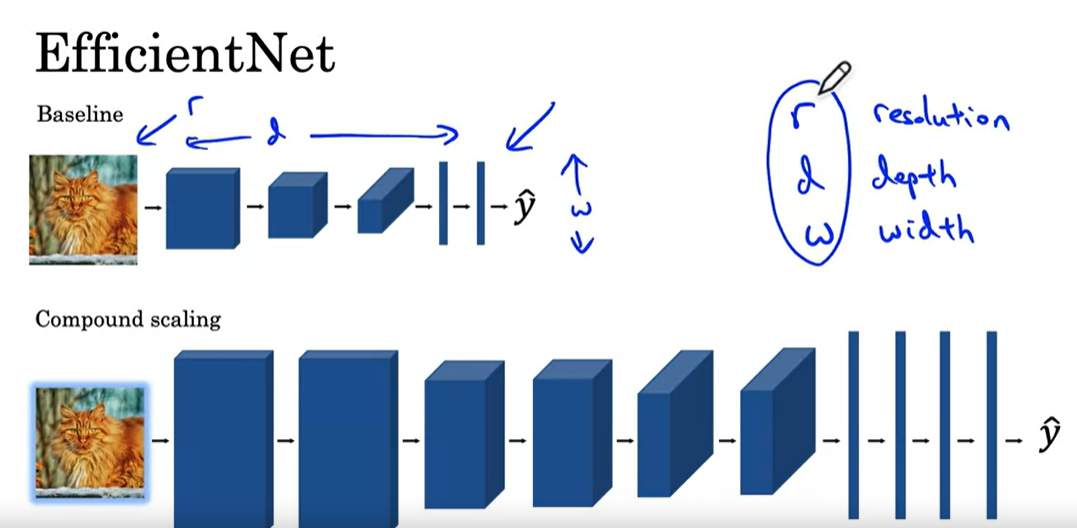
Practical advices for using ConvNets
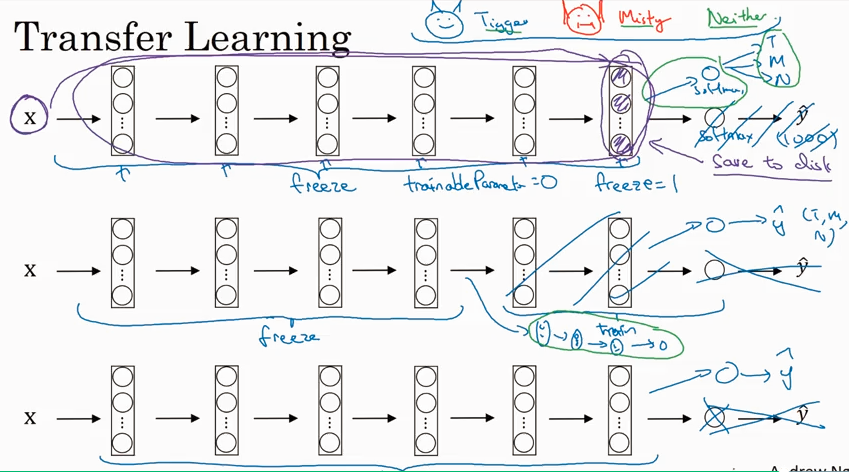
在trainning data 少的情况下,可以用trasfer learning 的方法,在别人比较训练好的model 上修改后面的layer 来得到自己的model. 当然如果trainning set 够大,也可以自己从头到尾训练出自己的model.
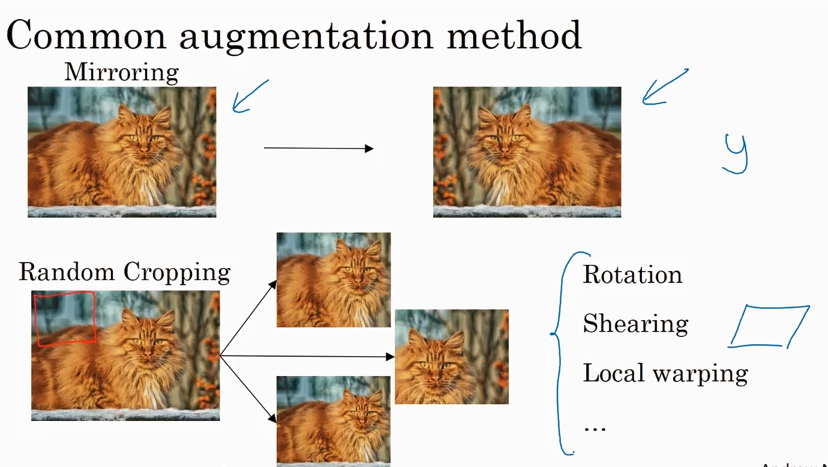
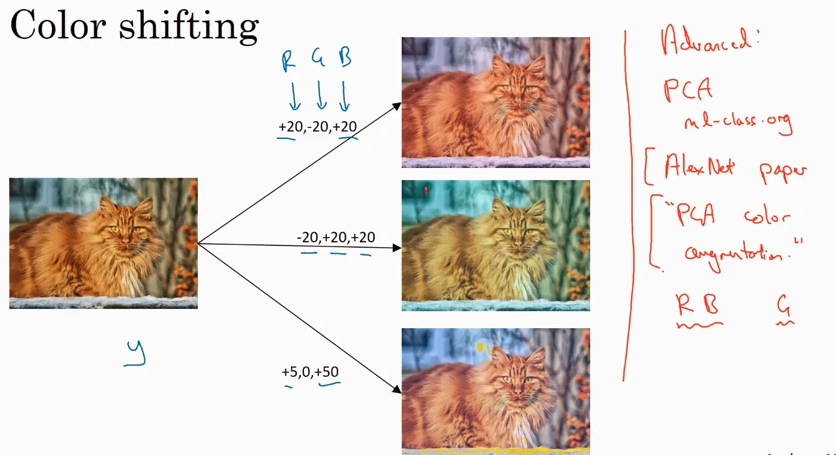
Data augmentation
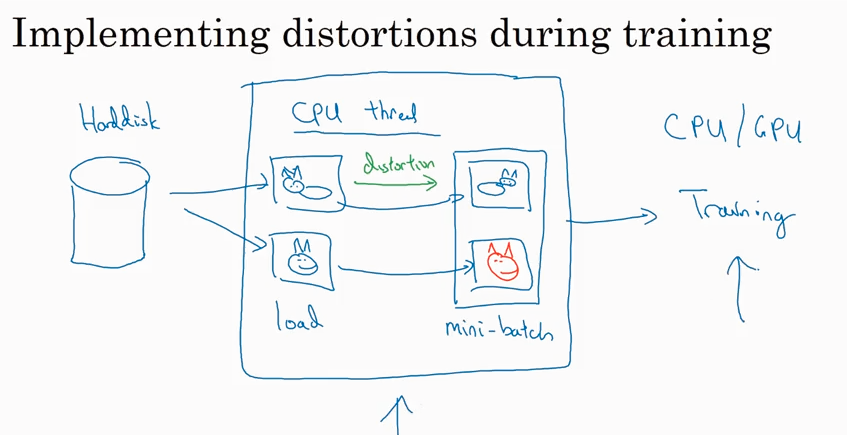
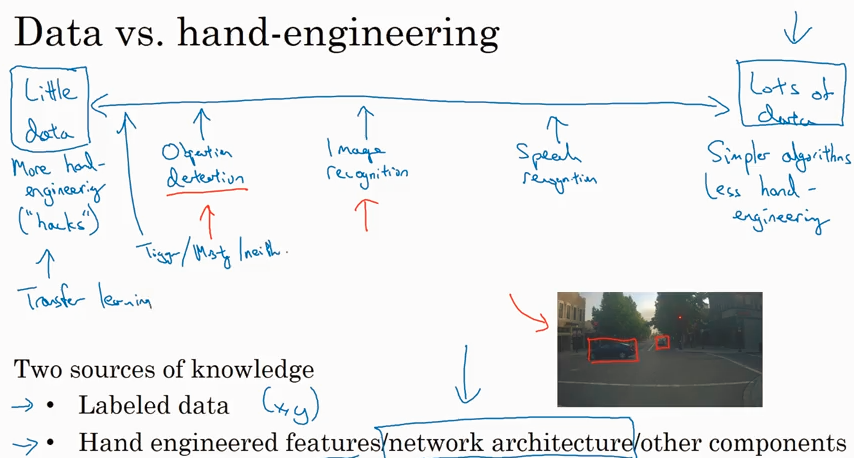
State of computer vision
下面是一些tips针对benchmark/winning competitions, 但是实际工作中不常用.

工作中常用的是下面的方法

