Coursera, Deep Learning 4, Convolutional Neural Networks - week1
CNN 主要解决 computer vision 问题,同时解决input X 维度太大的问题.

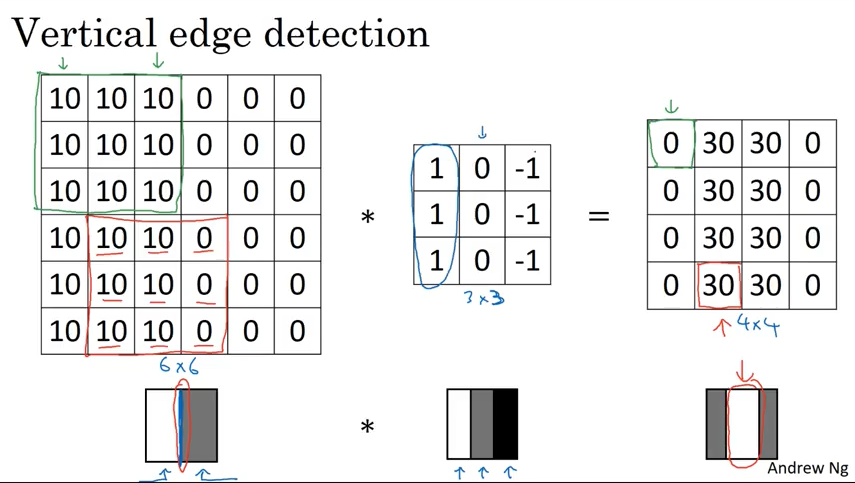
Edge detection
下面演示了convolution 的概念
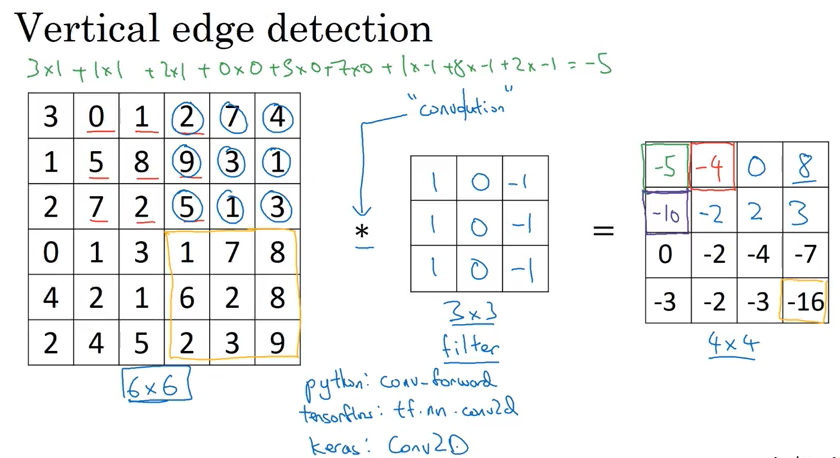
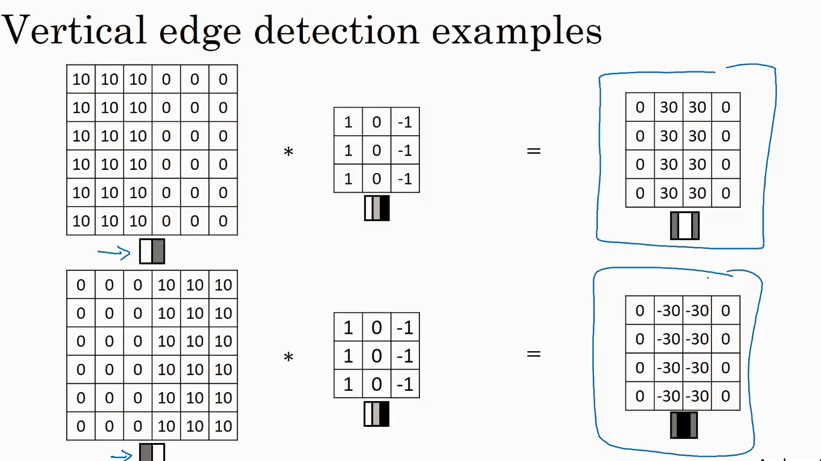
下图的 vertical edge 看起来有点厚,但是如果图片远比6x6像素大的话,就会看到效果非常不错.
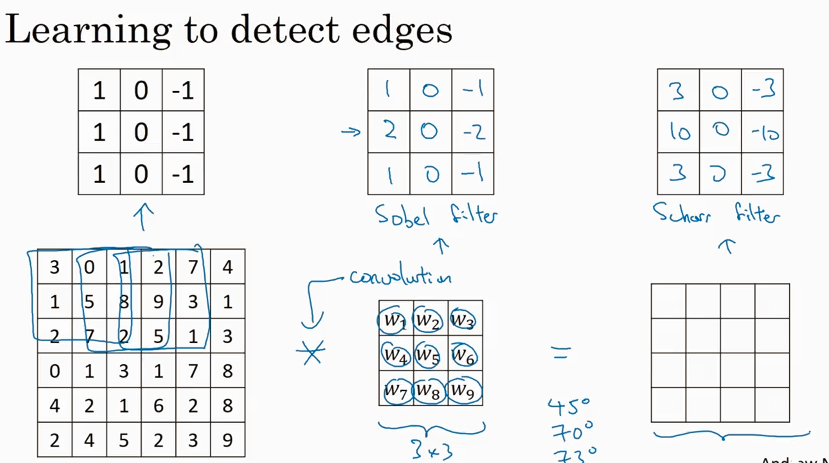
除了前面讲过的第一种filter, 还有两种 (Sobel filter, Scharr filter)
接下来会讲到 CNN 的两个重要的buiding block - padding, strided convolution. 也就是对前面所讲的basic convolution 的两种优化。
Padding
basic convolution 有两个问题, 一个是shrik output, 使得图像越来越小, 另一个是 throw away info from edge, 就是边缘的信息使用率不高. 为了解决这两个问题,在input image外围加了一个边框,就是padding.
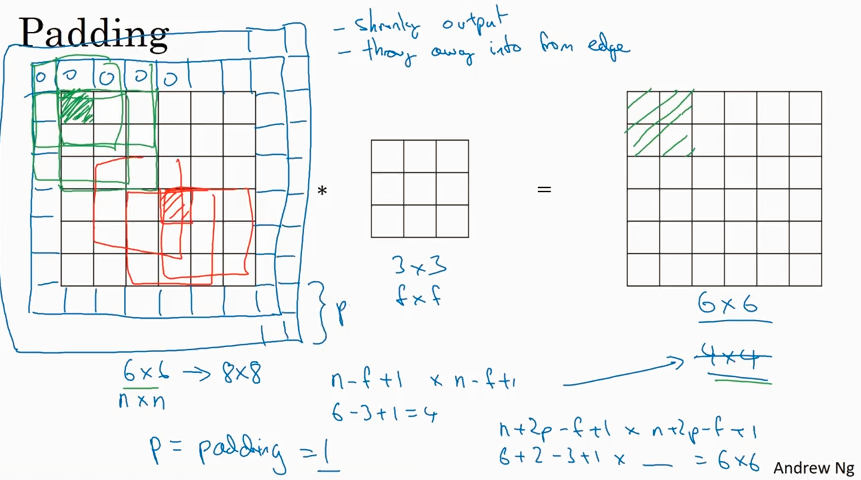
那么怎么来选取padding 值的大小呢?有两种方法 'Valid' (no padding), 和 'Same' (output size is same as input size). 要达到Same 的效果,只需要满足 p = (f-1)/2。 f 值通常选取奇数,Andrew 给出两个原因,一个是可以达到Same的效果,一个是可以在filter 里有center pixel 来描述位置.

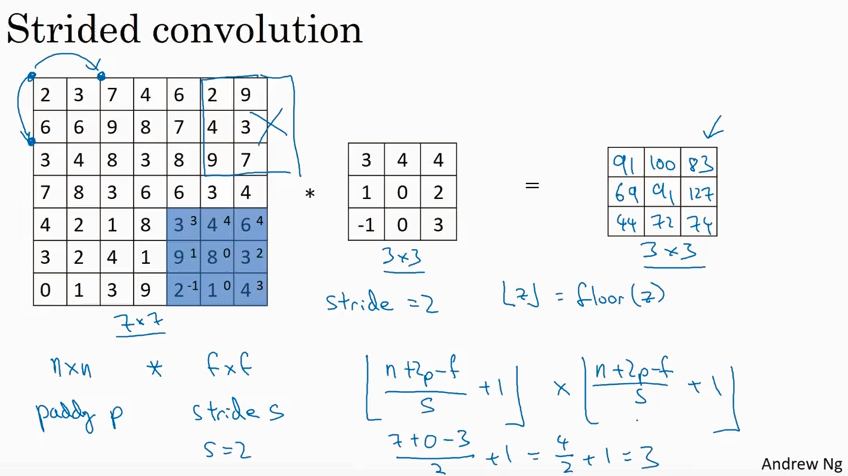
Strided convolution
如果要使得output size 更小,可以用strided convolution 方法,就是计算卷积的时候使得步长s更大。

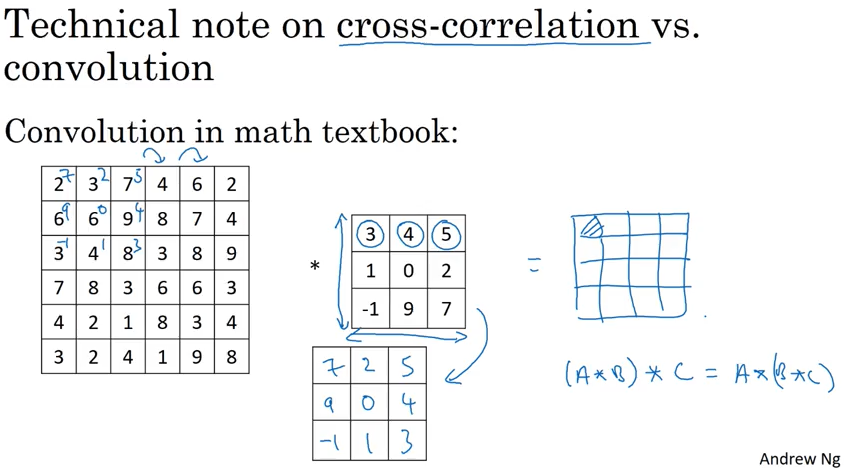
实际上在deep learing 里经常说的convolution 对应的是数学概念里的cross-correlation, 两者的区别是,数学里的convolution 比cross-correlation 多一步对filter翻转的操作. 也就是说deep learning里的convoluton 叫做cross-correlation更确切一些。但是翻转那一步对deep learning 没有影响,所以deep learning 里就用convolution 来指代cross-correlation. Andrew 提到这个是为了让读者在读数学论文时候不至于困惑。
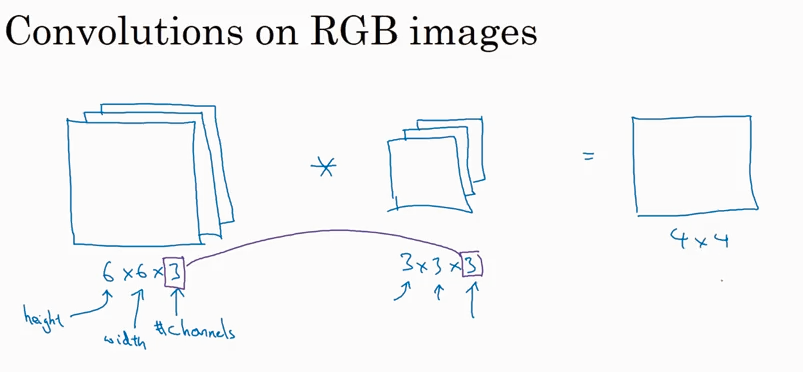
Convolution over volumes
前面讲的都是对2D 的image有卷积,现在开始讲对3D 的image 怎么求卷积。
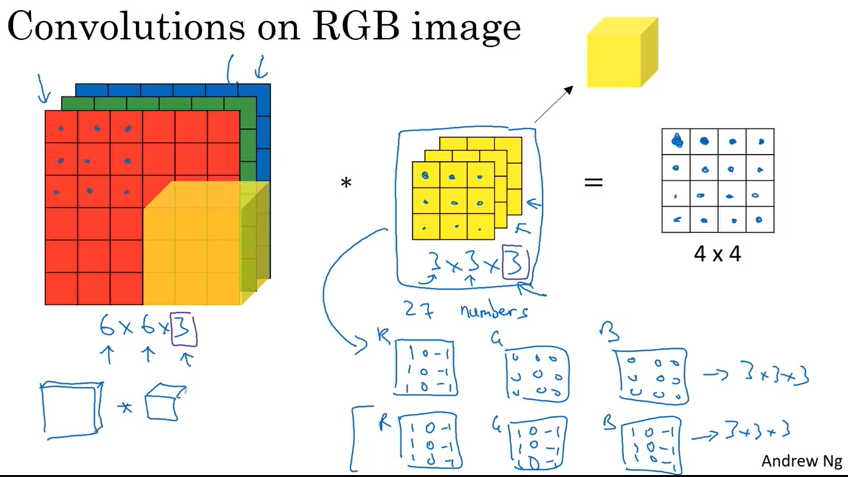
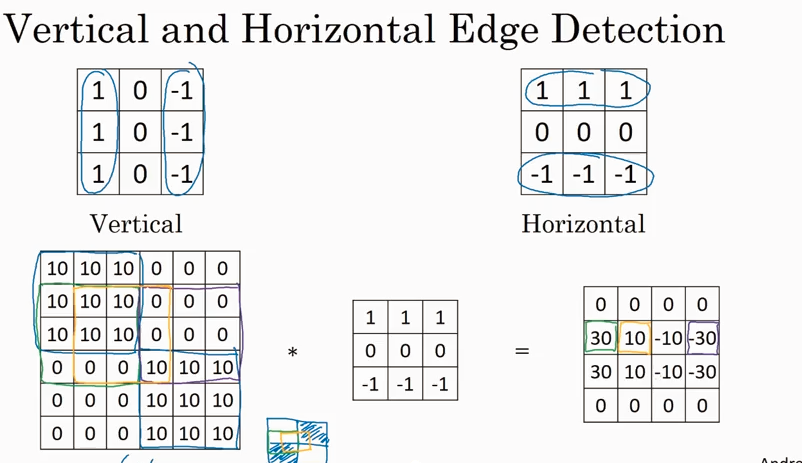
前面一直在讲用一个filter 来识别 vertical 或者 horizotal edge, 那如果要同时识别vertical 和 horizotal edge呢?答案是可以同时使用两个filter, 具体如下图。
这里提一下,第3个维度可以叫channel, 也有人叫depth.
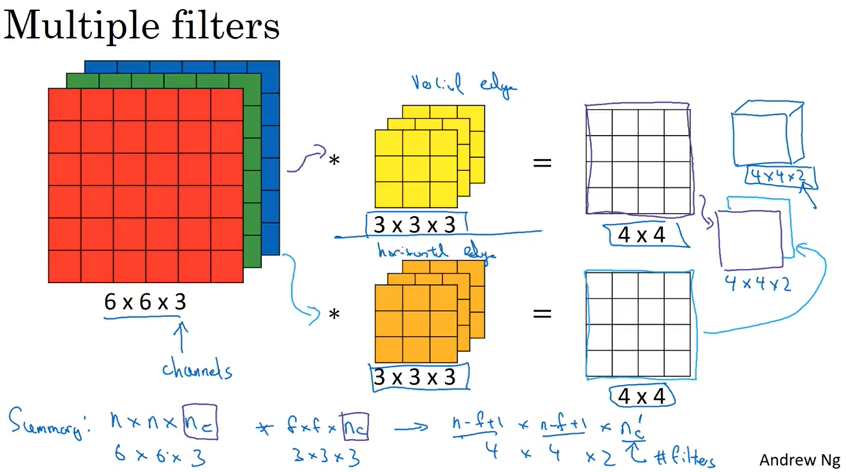
One Layer of convolutional network
一层convolution network 可以和传统的neural network 类比如下图。
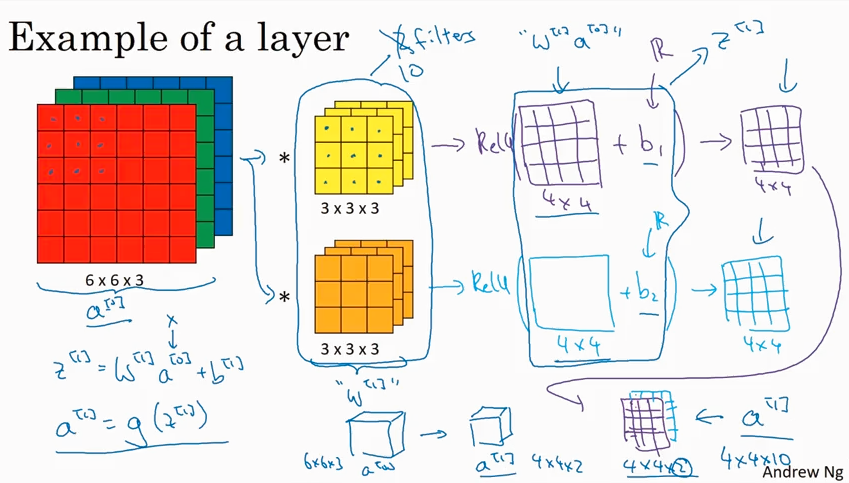
下图解释了convolutional network 中,无论input layer 的 X 维度多大(比如5000维),我们都可以用这10个filter 来充当W[1] 的角色,同时保持280个parameters不变。

下面是CNN中的一些notation. 需要说明的是本课程用了n[H][l] * n[W][l] * n[C][l] 这样的顺序,在CNN里也有用 n[C][l] * n[H][l] * n[W][l] 这样的顺序,效果一样.

Simple convolutional network example
下图是一个多层ConvNet 网络,通常image size 会逐渐减小,而channel size会逐渐增大.

通常一个convolutional network里不仅有convoluional layer, 还会经常看到 pooling layer, 和fully connected layer.

Pooling layers
先看Max pooling, 就是根据filter 的大小在input image里取最大值。一旦filter 的维度f 和步长 s 确定了,就可以从input里得出output, 无需计算filter 的参数。
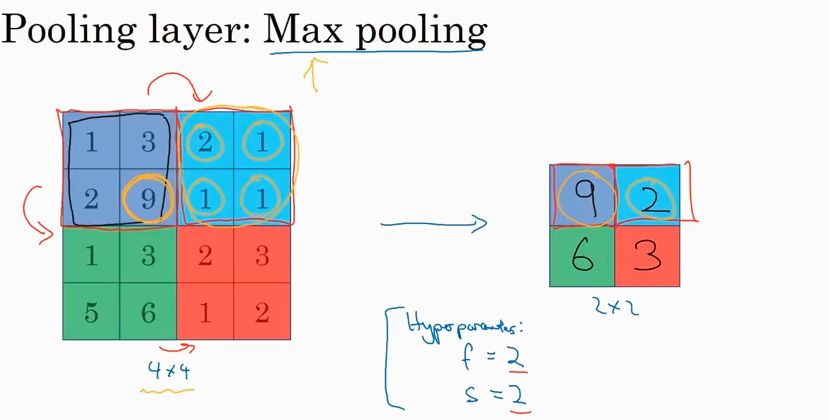
刚才是看的2D的情况,如果input lay 是3D的就是说有channel, 那么output 也会有相同的channel.
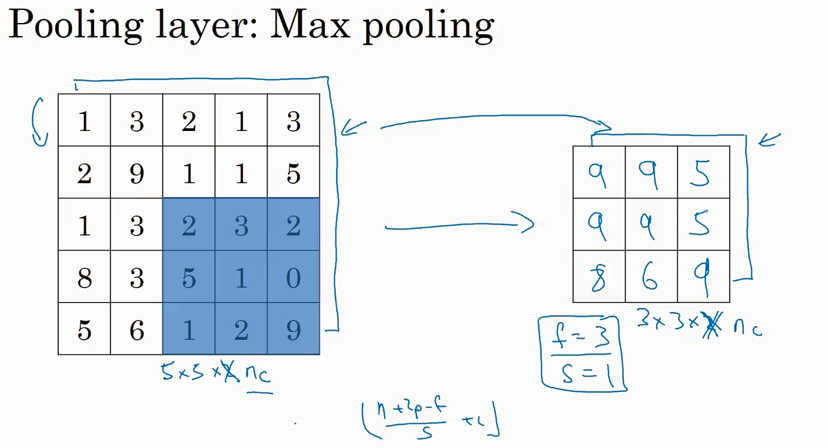
Max pooling 是求最大值,如果是求平均值,就叫average pooling. Average pooling 不常用.
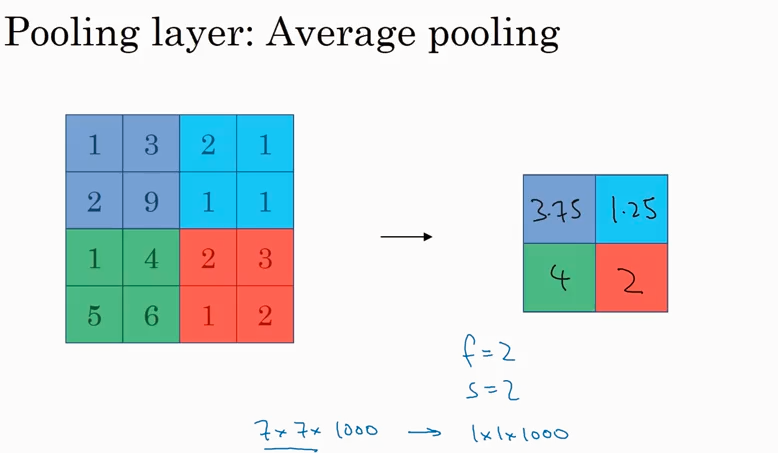
通常padding=0. f, s 最常见的值如下图.

Typical CNN example
按照习惯conv layer 和 pooling layer 合起来叫一个network layer, 这是只计算了有weight 的conv layer 而pooling layer 没有weight 就没有算.
FC means Fully Connected layer. 其实就是传统的network layer.
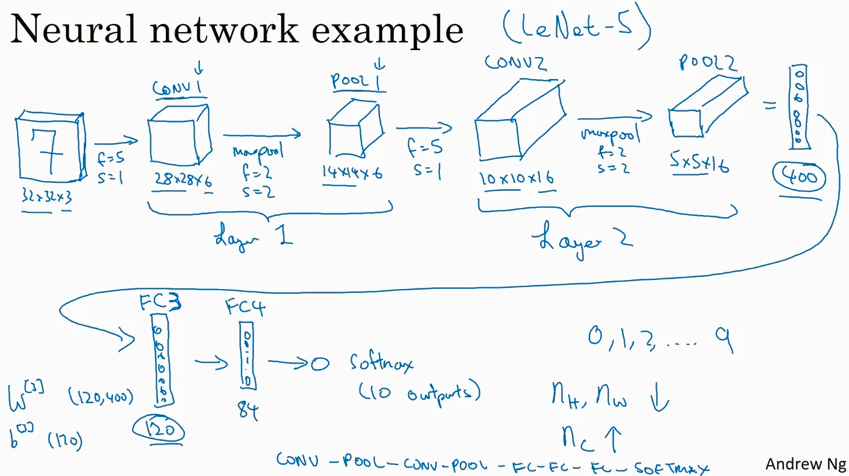
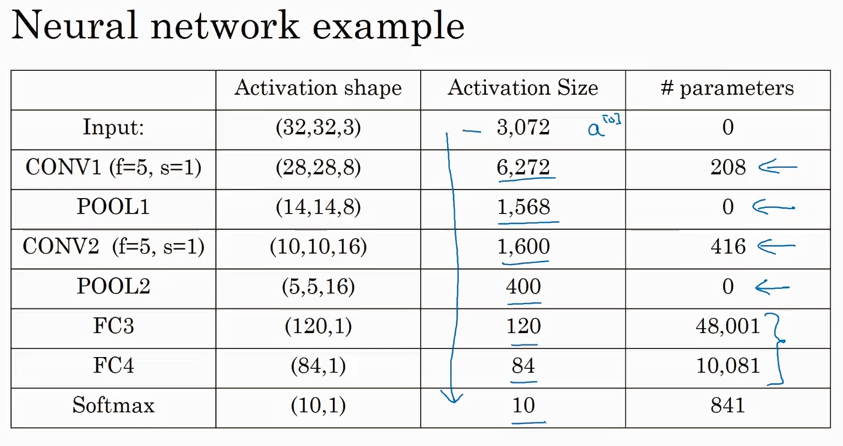
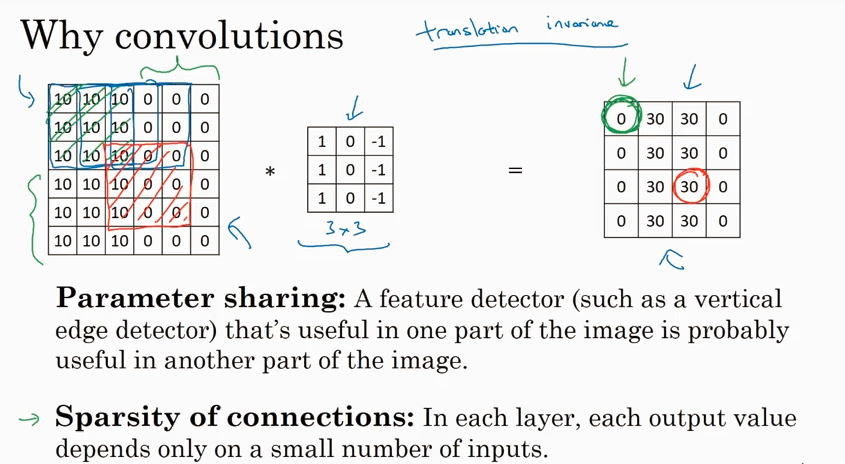
Why convolutions?
相比于传统的fully connected network layer, convolutional layer 的parameters少的多.
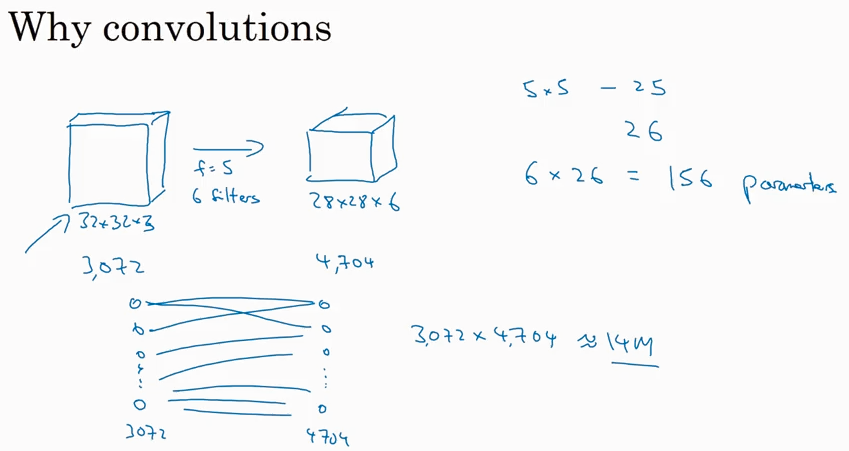
为什么parameters 少了那么多,还能达到很好的performance呢?
有以下两个原因:
feature sharing: 共享了3x3的filter,这个filter 的参数对每次convolutional 计算都是一样的。
sparsity of connections: output 中的一部分只取决于 input 中的一部分。