Coursera Deep Learning 3 Structuring Machine Learning Projects, ML Strategy
Why ML stategy
怎么提高预测准确度?有了stategy就知道从哪些地方入手,而不至于找错方向做无用功.


Satisficing and Optimizing metric

上图中,running time <= 100ms 就是satisficing,accuracy 就是 optimazing.
Dev set and test set should be from same distribution.
传统的traing set/ dev set / test set 比例是60/20/20, 在大数据时代可以是 98/1/1 这样的比例.
有些时候不能只看error rate 的值,下面这个图讲到算法A虽然error值低一些,但是如果含有色情图片就是不能接受的,所以需要一种新的计算error的方法, 对特定的图片加权.

还有一种情况是下面讲的,当你去做预测的时候,发现B的实际效果,比如你在高精度training set上训练的model, 用户却经常上传一些不专业的或者模糊的照片。这时你就要调整你的training set了.

Comparing to human performance
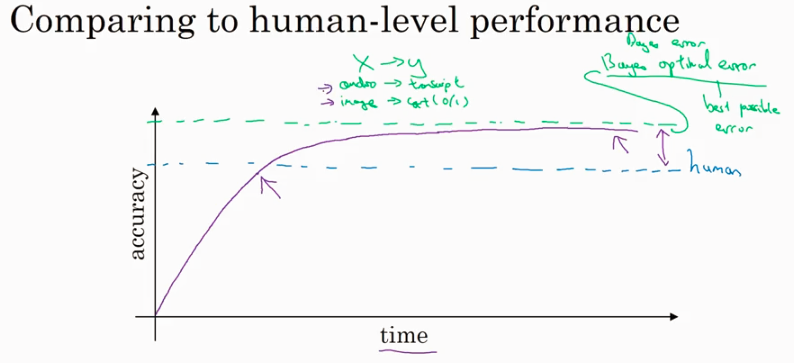
why comparing to human performance, 我的理解就是找到差距,变的更强大.

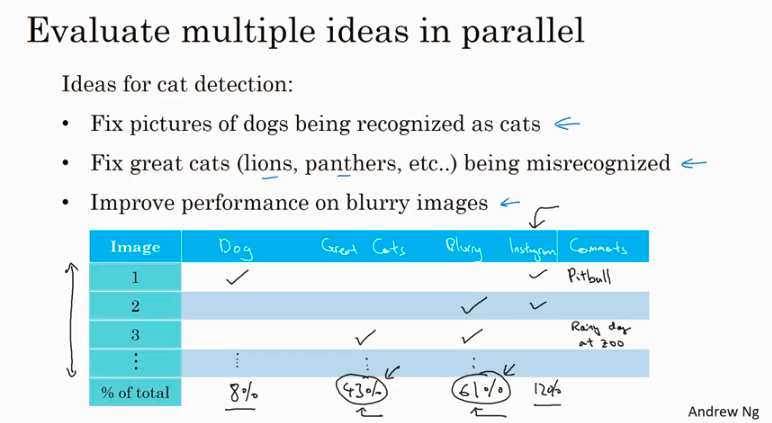
Error analysis
从mislabelled example 里统计各种不同类型的error, 看哪种占比大就从哪里入手.

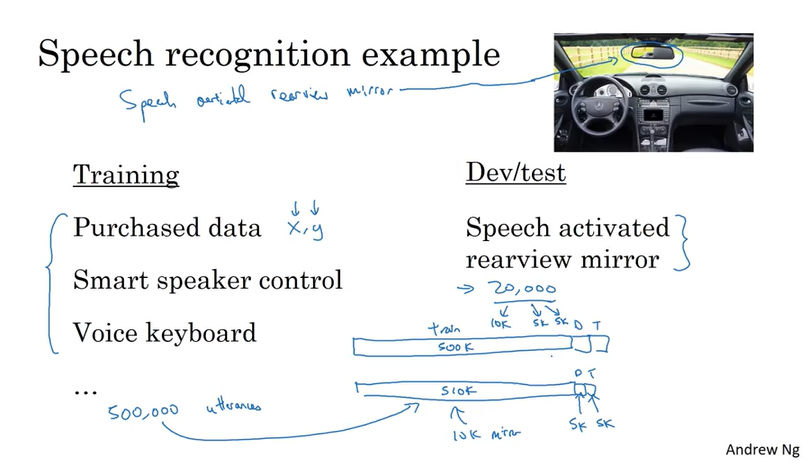
Mismatched training and dev/test set (training data 和 dev/test data 来自不同的distribution)
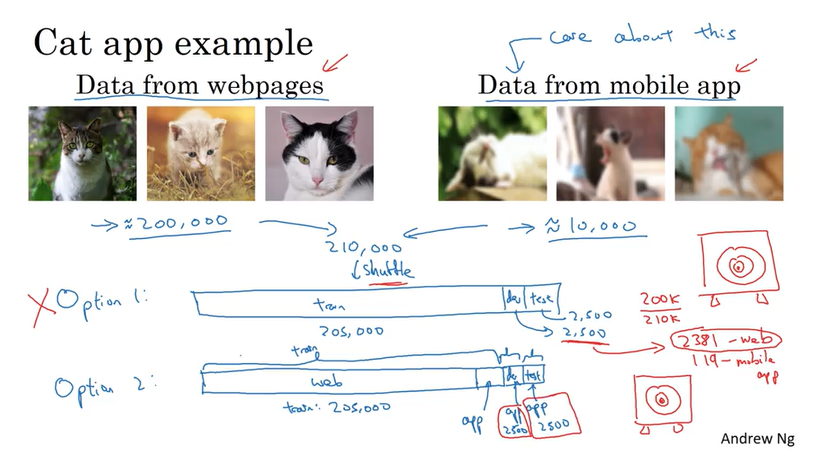
把一些来自实际场景的数据,这些数据有价值但是数量不多,一部分放在training set里,另一部分都放在dev/test set. 就是下面的推荐的Option 2,dev set 和test set 里都是真正有价值的data. 这样做的好处使得我们的model 面向最终解决的问题.
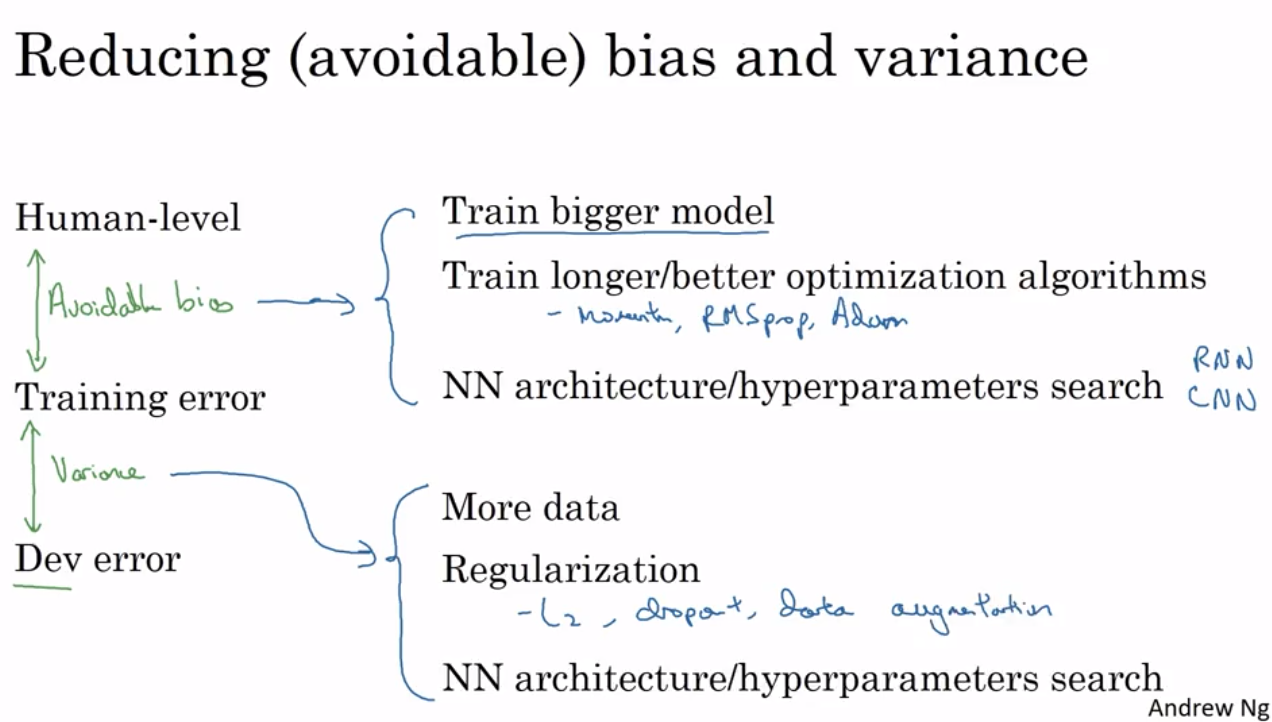
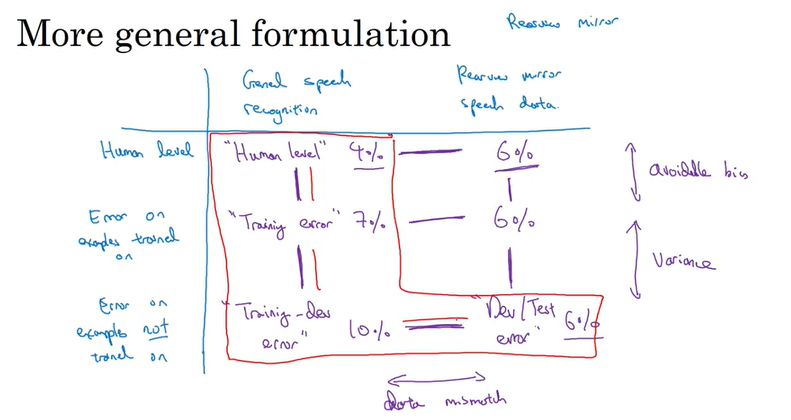
在training set 和dev/test set 有不同的distribution时,根据训练得到的不同error值,怎么定位到底是bias, variance, 还是 data mismatch 问题?
可以多分一份 training-dev 的数据集


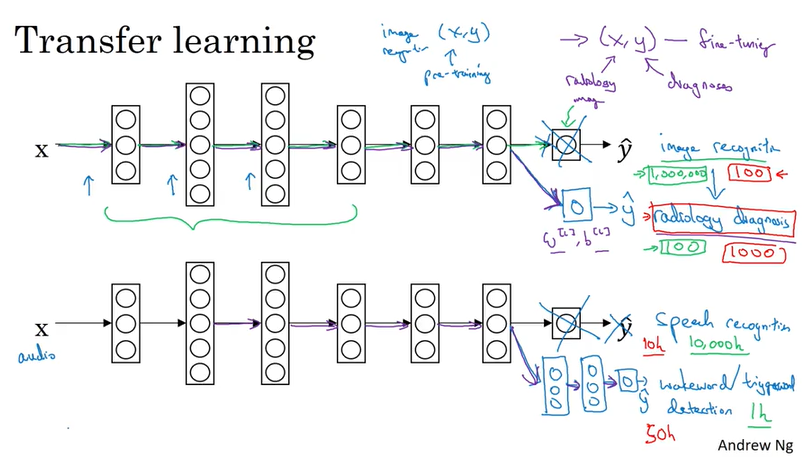
How to address data mismatch ?



Transfer learning

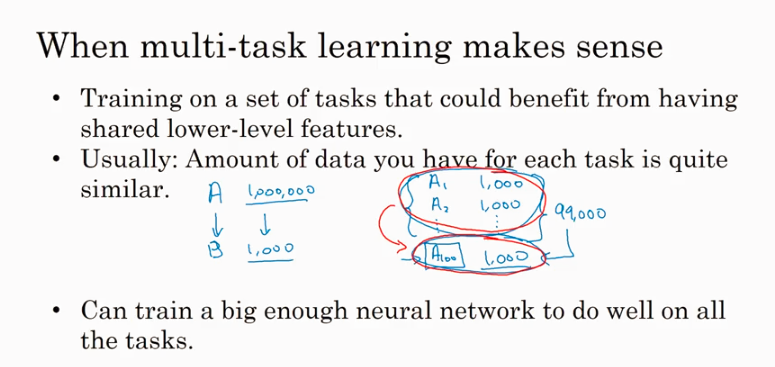
Mult-task learning
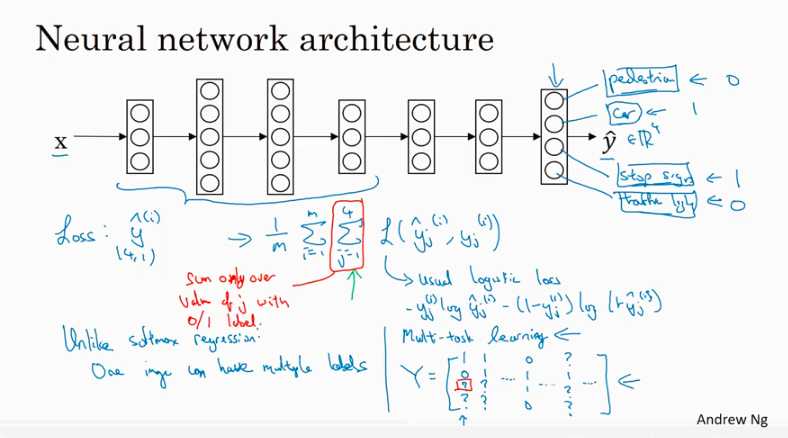
只要神经网络够大,multi-task learning 的performance会比针对每种分类跑一次softmax分类效率更高 (softmax 一个输出只包含一种类型, multi-task 一个输出可以有多个类型,比如既有行人又有汽车). multi-task learing is much less than transfer leaning in practice.
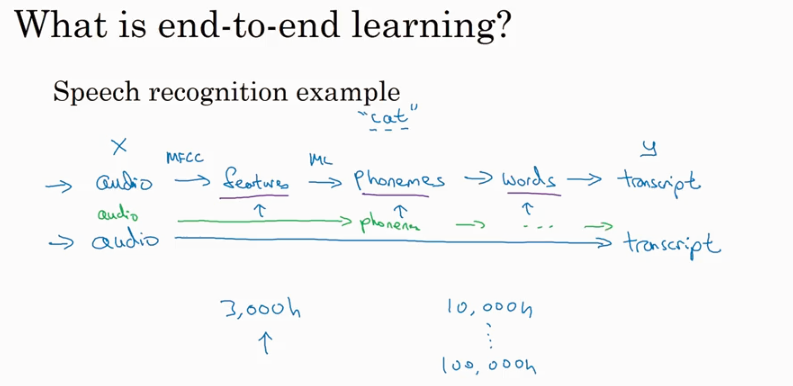
End-to-end learning
一般的做法是经历很多中间步骤,但是E2E learning 就是直接从raw data X 到 Y. 在有大量数据的情况下E2E 可能会有很好的performance, 但是
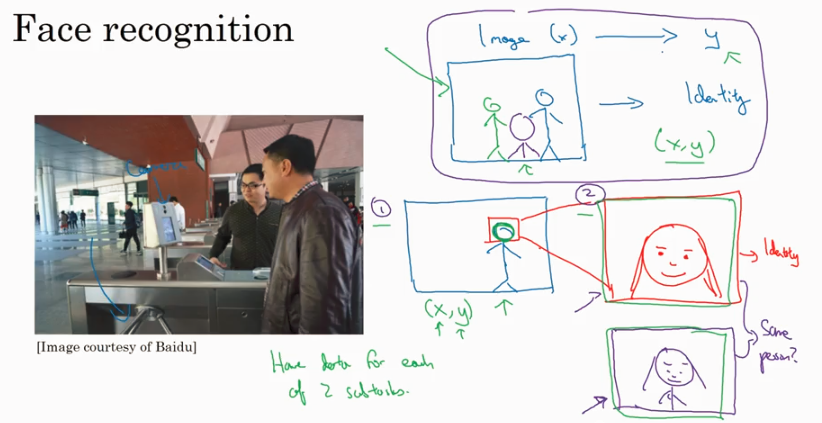


补充阅读:
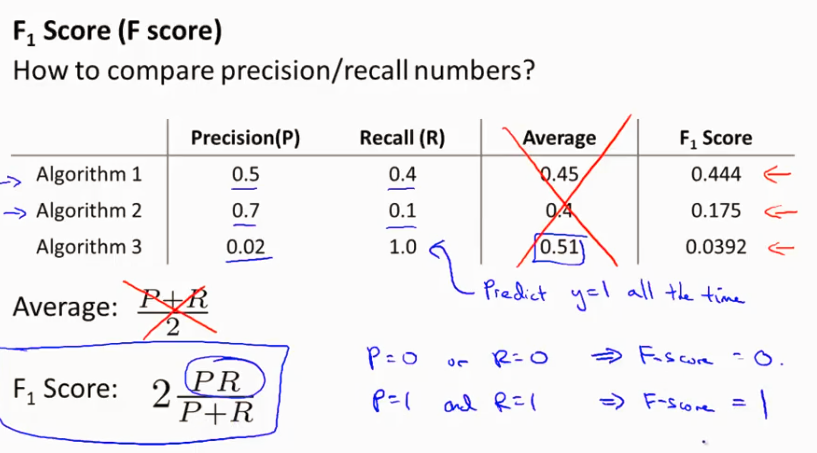
什么是precision 和 recall
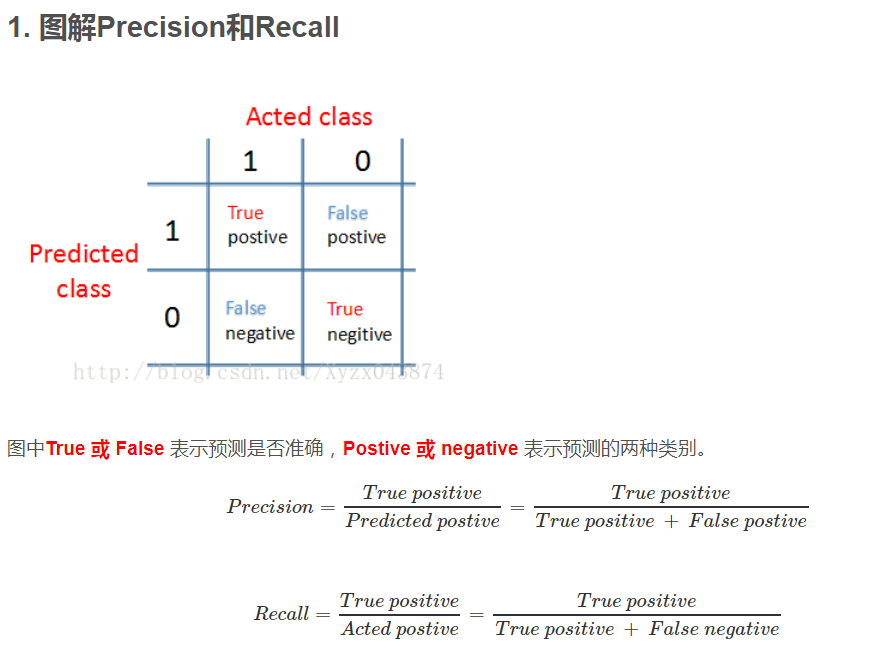
关于Precision 和 Recall 的作用有个很好的例子可以说明,就是针对 skewed data 比如判断病人是否有癌症,一个Model直接hardcode 使得 y=0 (没有癌症)也可以得到很好的预测结果,这个model 明显不合理,就引出了使用 Precision 和 Recall 来判断一个model 的优劣. 在这两个值都很大的情况下(接近1)就可以说Model很好.
用一个值来判断可以用F1 score.