
LLM
LangChain 是啥,能干啥? AutoChain 又是啥
近年来的LLM模型
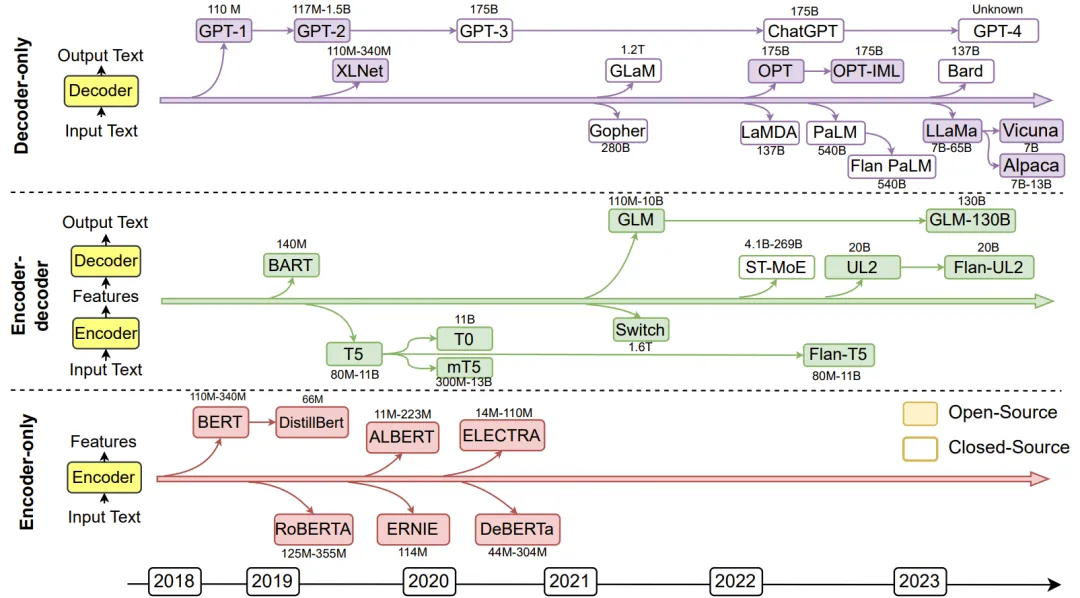
LLM 都是基于transformers 结构的,具体又分为
Encoder-only(Autoencoding), 比如 BERT, ROBERTA

Encoder-Decoder,

Decoder-only(Autoregressive), 目前用的比较普遍。 GPT, BLOOM, LLAMA...

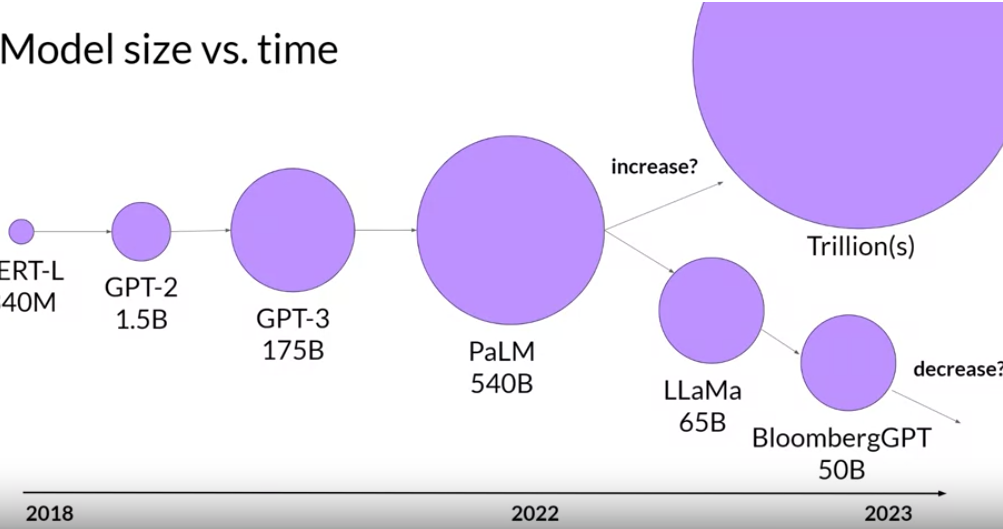
根据chinchila paper, 目前很多大模型是under trained, 只要喂给大模型的数据大于其参数的 20倍,可以做成更小的模型而且达到很好的效果.
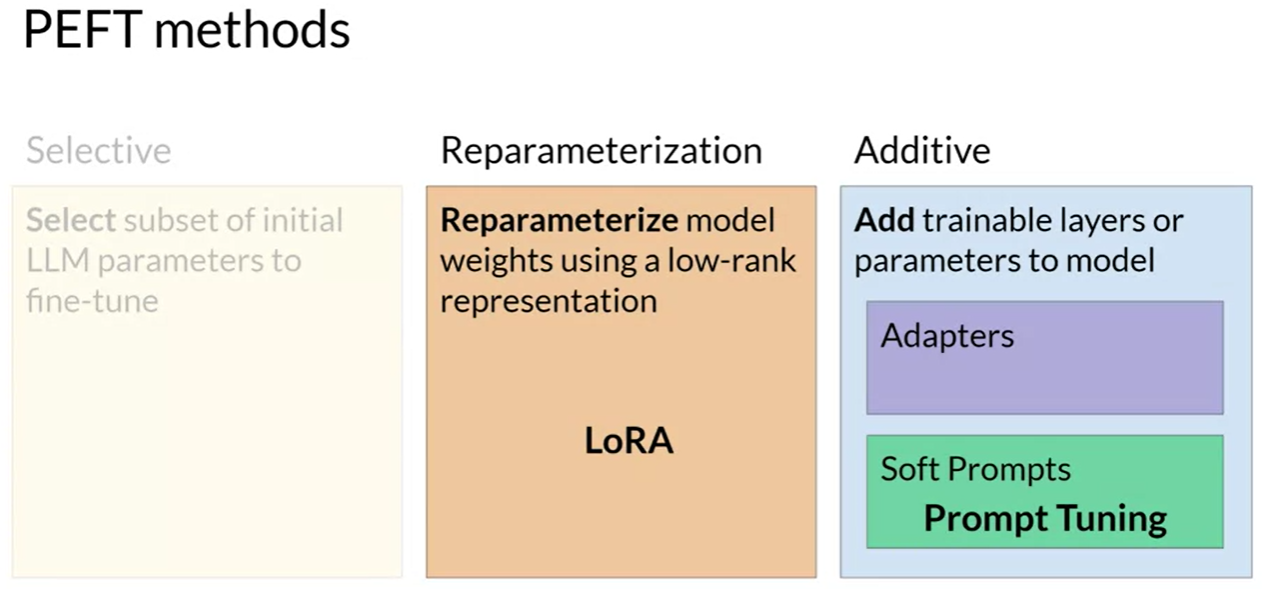
Fine-tuning
有两种方法
一种是 instruction fine-tuning, 是直接重新训练的原来model的参数
一种是 FEFT (Parameter Efficient Fine-Tuning), 要么freeze 大部分参数,重新训练一小部分; 要么freeze 全部参数,增加一些新的Adapter参数.
Ref:
https://www.datacamp.com/tutorial/how-to-train-a-llm-with-pytorch
https://zhuanlan.zhihu.com/p/620529542
Coursera
转载请注明出处 http://www.cnblogs.com/mashuai-191/
